
What Is Synthetic Full Backup: Facts Every Sysadmin Should Know
There are multiple backup approaches, including full, incremental, and differential. Creating full backups frequently may be inconvenient and technically impossible because a full backup requires time and consumes hardware resources. In this case, the incremental backup and synthetic full backup approaches can be useful.
In this blog post, we’ll explain what synthetic full backup is and how it differs from active full and forever-incremental backup approaches.

What Is Synthetic Full Backup?
A synthetic full backup is a backup approach that involves creating a new full backup by using the previous full backup and related incremental backups. This means that a backup solution does not have to transfer the full amount of data from the source machine and can synthetize the latest incremental backups with the last full backup to create the next synthetic full backup.
How Does Synthetic Full Backup Work?
Let’s first look at the full and incremental approaches used in a synthetic full backup. We will also cover forever-incremental backups, which share some characteristics with synthetic backups.
Full backup
A full backup involves copying all data from the source machine to the target storage. The advantage of a full backup is the high level of reliability and ease and speed of data restores. A full backup that copies all data directly from a source machine is called an active full backup.
Modern backup solutions require using the traditional approach to backup and, thus, performing full backups periodically. However, an approach relying exclusively on full backups of virtual or physical machines has its drawbacks:
- Backups take too much time.
- Creating full backups places an extra load on both the infrastructure resources (processor, disk drives, memory) and the network.
- Workloads such as VMs running on a source server may slow down.
- As the chain of full backups grows over time, the amount of backup data becomes quite large and consumes a lot of storage space in the backup repository.
Incremental backup
An incremental backup involves copying only data that has changed since the last full or incremental backup. Incremental backups are fast and require less storage space for data changes than storing the whole data set for a full backup.
Restoring data by using a chain of incremental backups takes more time compared to a full backup because you need to “play the changelog” and reassemble data by using the chain of multiple increments. The more increments you need to replay for restoring data, the more time recovery takes.
One more disadvantage is that if one of the increments in the chain is corrupted, you cannot recover data backed up starting from this incremental backup. This is one of the reasons why it is usually recommended that you create a full backup at regular intervals and use an incremental-with-full-backup approach for a reliable data protection strategy.
Creating a full backup periodically still places a load on production machines and networks. Here’s where the synthetic full backup comes in.
Synthetic full backup
Synthetic full backup involves using the last full backup and the following chain of incremental backups to synthesize a new full backup periodically. In this case, there’s no load on production or source servers, disks, and networks as no data is copied from the source machine. The increments in the backup storage are used as the source for creating this synthetic full backup. Only a backup server and target disks (where backups are stored) are loaded.
Using synthetic full backup is the optimal way to create periodic full backups as this approach is fast and doesn’t rely on production machines. Now let’s consider an example of how a synthetic full backup works.
Example of a full synthetic backup
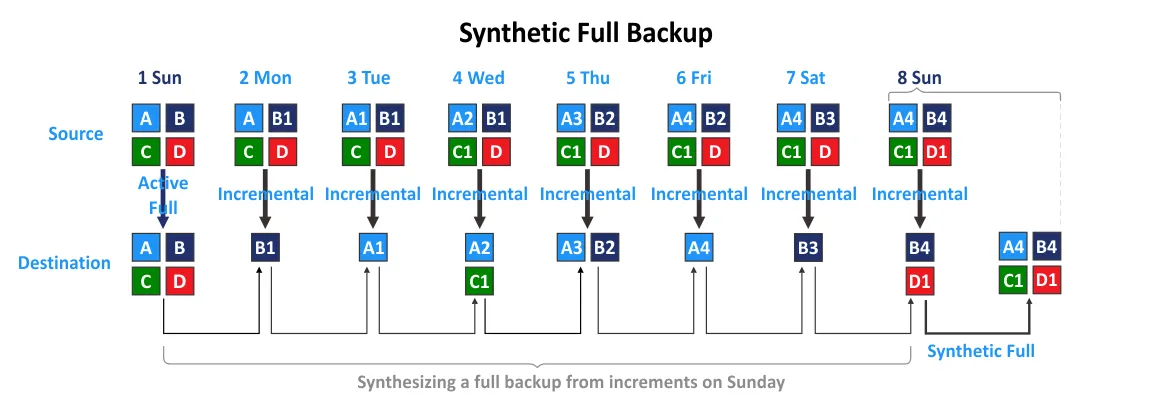
Let’s say that we have four blocks (A, B, C, D) on a disk, and some of these blocks change every day. After a change, 1 is added to the block name. For example, if block A changes, its name becomes A1. If block A1 changes again, it is renamed to A2, and so on and so forth.
The backup cycle is configured to create a full backup once a week on Sunday. Incremental backups are created once every day.
Sunday is day 1 in our backup schedule, and we create the initial active full backup as shown in the image below. All data is copied from the source server to a destination backup server.
After a week, a synthetic full backup is created on Sunday (day 8) instead of creating an active full backup. In this case, a full backup is synthesized from the previous increments. The data is assembled by using the first full backup made on Sunday ( day1) and the chain of subsequent incremental backups (days 2 to 7). As a result, we have a synthetic full backup on Sunday (day 8) with blocks (A4, B4, C1, D1).
The data set in a backup repository on Sunday (day 8) is the same as on a source server (A4, B4, C1, D1). However, only data of the changed blocks (B4, D1) was copied on Sunday (day 8) to the backup repository by running an incremental backup instead of copying all data by running an active full backup.
As a result, we have a full backup on Sunday (8) after doing two operations: creating an incremental backup and creating a full synthetic backup.
Let’s visualize how much data is copied from a source server to a backup server by using a backup scheme with an active full backup once a week and daily incremental backups. We create a full synthetic backup every Sunday, as before. For simplicity, we suppose that data is written on the source server each day but not deleted.
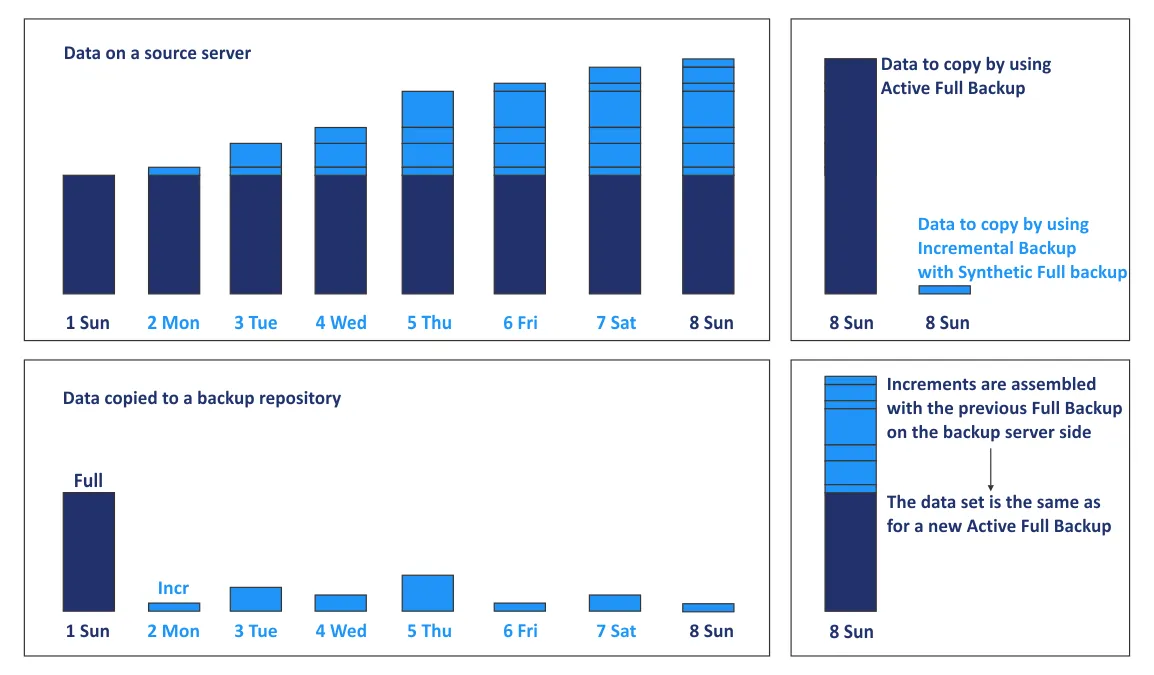
After a synthetic full backup has been created on Sunday (day 8), the incremental backup created on that same Sunday can be deleted because we can recover data for the Sunday (day 8) recovery point from the synthetic full backup made on that day.
If you create a backup once a day and create a full synthetic backup once a week, the pattern for each week is identical. If your retention settings require storing all backups for two weeks, you can delete backups (full and incremental) older than two weeks. Note that in this example, you need to preserve three full backups for days 8, 15, and 22, as the chain of incremental backups for days 9-14 depends on the full backup on day 8.
Forever-incremental backup
Forever-incremental involves creating only one initial full backup, and all subsequent backups are incremental. Backup data is sorted into unique blocks as a catalog in a backup repository. Dependencies and relationships are tracked. This information allows you to restore data for the needed recovery point by reassembling the data from the backup repository.
A backup repository is less loaded because there is no need to create an active or synthetic full backup periodically. Data is reassembled only when it is required for recovery. When a recovery point expires, this oldest incremental backup is merged with the full backup based on the retention settings (where you set how many recovery points to retain).
Forever-incremental backup uses the synthetic backup storage mode approach. The principle of this mode is that we need to create a full backup only once. After that, we create forever-incremental backups based on our schedule, and these increments will contain only changes made to the source machine since the previous backup.
To get a synthetic backup, a backup solution reads the initial full backup and all of the incremental backups with changes stored in the backup repository and synthesizes this data into a backup. This synthesized backup will be identical to an active full backup and will fully reflect the state of the source machine at a particular point in time.
Today’s backup solutions support both synthetic full backup and forever-incremental backups. Read more about other backup approaches on our blog.
Why Use Synthetic Backup?
The synthetic approach to creating backups has a set of advantages. These are:
- Synthetic backups reduce the load on the source server because synthetic backups are created in the backup repository rather than by using the source server.
- Synthetic backups reduce the load on the network, as the amount of data transferred from the source server to the backup repository is significantly decreased. Copying fewer data requires less time to copy this data and can be used to improve the RPO.
- Machines and individual items can be easily and quickly restored anytime you need. Short time to restore data improves the RTO.
Full Synthetic Backup Data Storage with NAKIVO Backup & Replication
As a modern VM backup solution, NAKIVO Backup & Replication uses the synthetic approach to creating and storing backups. After the initial full backup, all jobs are incremental with periodic full backups or forever-incremental. Using the CBT and RCT technologies, the product tracks changed data blocks and transfers only these blocks to the backup repository.
When using the forever-increment approach the NAKIVO solution, After each backup job run, a recovery point is created, which is essentially a set of references to data blocks stored in a single pool in the backup repository. These recovery points can be used to restore the necessary virtual machine at a particular moment in time.
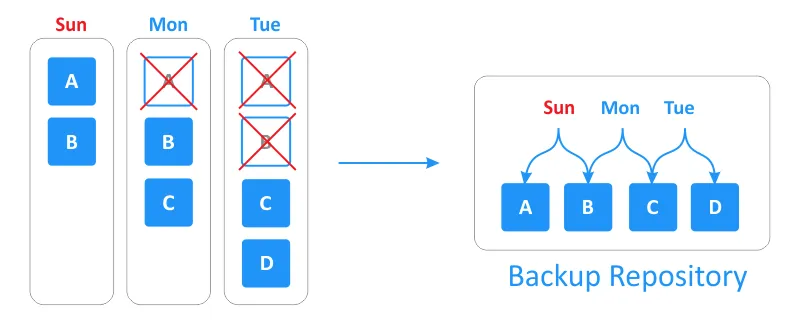
Therefore, creating periodic full backups is unnecessary, as the data in the backup repository is stored using the so-called “full synthetic mode”, which eliminates the need for backup transformation.
The full synthetic mode gives NAKIVO Backup & Replication an advantage over the products applying the traditional backup approach because:
- All data blocks are stored only once, are unique, and can be referred to by multiple recovery points.
- Synthetic backups are substantially faster, as you don’t need to run a full backup, and each recovery point “memorizes” data blocks that should be used for an entire machine restoration.
- Synthetic backups are much safer in comparison with traditional backups. If you lose a data block or an increment in a chain, the NAKIVO solution will provide you with recoverable increments.
- As each recovery point already “knows” which data blocks should be used for VM recovery, the recovery process will run much faster.
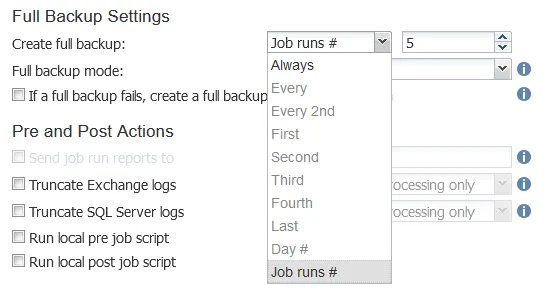
If you need to use a backup scheme with full backups created periodically, the NAKIVO solution can periodically create an active full backup or synthetic full backup. Selecting the full backup mode is displayed in the screenshot below.
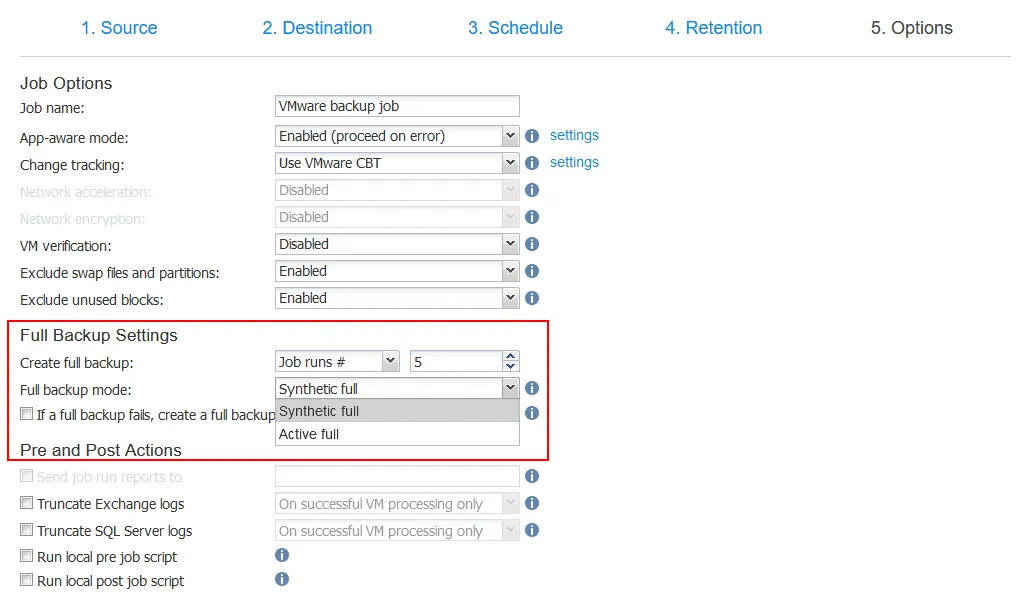
You can configure how often to create a full backup, for example, every 7th day of the week, every 5th backup job, etc.
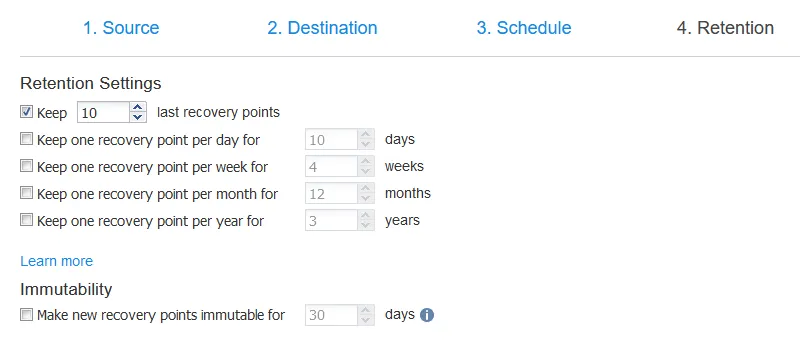
You can use flexible retention settings and the GFS retention scheme that works great with the NAKIVO backup repository.

Conclusion
The synthetic backup is a good alternative to backing up your VM data using the traditional backup approaches. It facilitates and speeds up VM backup and recovery, improves RPO and RTO, unloads your infrastructure resources and network, and saves you time and money.


