
Setting Up Hybrid Cloud Backup: A Complete Guide
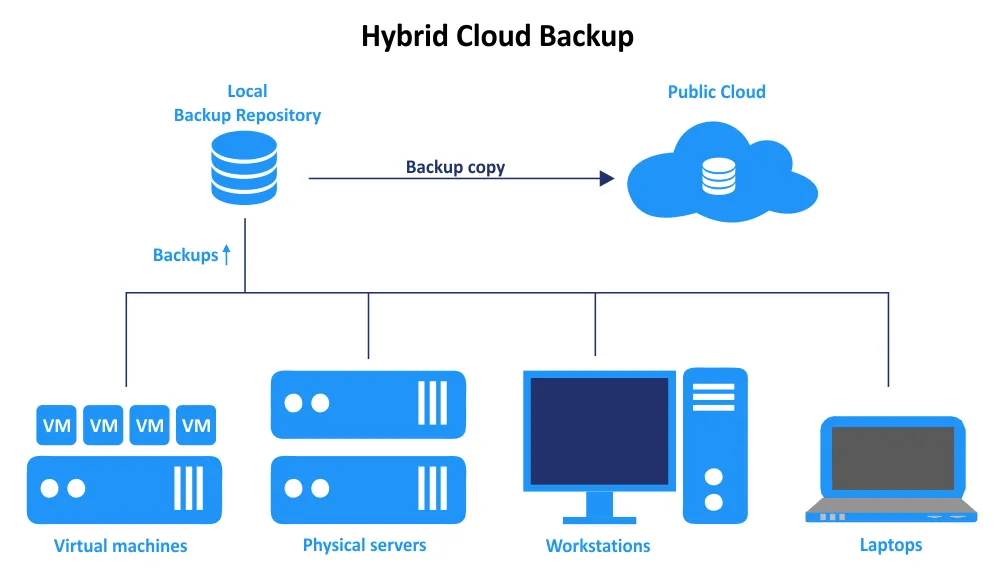
Hybrid cloud backup is a data protection strategy that combines both on-premises and cloud-based storage for backup data. This approach stands out from other backup strategies by including a cloud component to enhance redundancy, availability, resilience, and cost efficiency.
In this article, we won’t be focusing on backup of a hybrid cloud infrastructure but rather with backup to hybrid cloud setups, including basic principles and data protection solution configuration to integrate with cloud services.

Hybrid cloud backup strategy
Let’s now look at what a hybrid cloud strategy for backup and recovery includes:
- Local backup (on-premises infrastructure)
- An organization maintains its own backup infrastructure as part of its on-premises data center. This includes backup servers, storage devices (for example, NAS) or other appliances.
- Regular backups are created at specified intervals, capturing changes to your data over time. Frequent recovery points are created to provide quick access to data and ensure operational continuity.
- This local infrastructure allows for faster backup and recovery times for day-to-day operations and is suitable for scenarios where immediate access to data is essential and the recovery time objective (RTO) is short.
- Cloud-based infrastructure
- In addition to the on-premises setup, an organization uses a cloud service provider, such as Amazon Web Services (AWS), Microsoft Azure, or another cloud platform to store backup copies in the service provider’s remote data center.
- Cloud storage provides offsite redundancy, which is crucial for data recovery in case of local disasters, hardware failures, or other on-premises issues, which can also make local backups unavailable. Cloud backups are accessible from any location with an internet connection, enabling remote data retrieval and recovery.
- Cloud resources are also easily scalable, allowing an organization to adapt to changing capacity requirements without major hardware investments in advance.
- Implementation
- Backup management software is used to schedule, manage, and initiate backups across both on-premises and cloud environments.
- Initially, data from on-premises systems is backed up locally, ensuring quick backup and recovery for operational needs.
- Backup data stored on-premises is then periodically copied to the cloud storage, creating redundant copies in the remote environment.
- Organizations establish retention policies to determine how long backup copies are retained both locally and in the cloud. This helps manage storage costs and compliance requirements.
- Data and machine recovery
- The combination of local and cloud backups enhances your organization’s business continuity and disaster recovery capabilities and IT resilience. In the event of data loss, corruption, hardware failure, or other emergencies, you have two options for data recovery: local and cloud-based backups.
- Local backups address immediate recovery needs, while cloud backups provide a safety net in case of larger-scale disasters that affect your on-premises environment.
- Local backups offer quicker recovery times for day-to-day operations, as data can be restored from on-premises infrastructure without relying on the internet. The speed of a local area network is also faster than internet speeds.
- The cloud component of hybrid cloud backup serves as a crucial element in disaster recovery planning, as it provides data redundancy in geographically separate locations. In the event of a disaster affecting the local infrastructure, organizations can restore data from the cloud to ensure business continuity.
Benefits of Hybrid Cloud Backup
Hybrid cloud backup offers several benefits that make it a compelling data protection strategy for organizations. The enhanced operational resilience results from several factors:
- Redundancy and disaster recovery. Hybrid cloud backup provides redundancy by storing data in both on-premises and cloud environments. This redundancy ensures data availability and recovery even in the event of hardware failures, data corruption or local disasters.
- Flexibility and scalability. Hybrid cloud backup offers scalability by utilizing cloud resources for additional storage capacity during peak demand periods or as data volumes grow. This scalability eliminates the need for constant hardware upgrades.
- Remote accessibility. Cloud backups allow authorized users to access data from anywhere with an internet connection. This remote accessibility is crucial for businesses with remote or distributed teams and in disaster recovery scenarios.
- Quick recovery. Local backups allow for fast data recovery for routine operations, while cloud backups offer a secondary option for disaster recovery. This combination enables organizations to meet varying recovery time objectives (RTOs) for different scenarios.
- Offsite protection. Cloud backups provide off-site protection, safeguarding data against physical threats like theft, flood, fire, typhoon, or other natural disasters that could affect the on-premises infrastructure. Cloud storage serves as a remote location for storing backup data. In the event of on-premises data loss, hardware failure, or natural disasters, data stored in the cloud remains accessible and recoverable.
- Security enhancements. Cloud providers often offer advanced security features, encryption, and compliance certifications. This improves data security compared to traditional local backup methods that might lack these measures. Many cloud storage providers also deliver immutability to protect data stored in the cloud against modification, corruption, and encryption by malware.
- Data mobility and workload management. Hybrid cloud backup allows for seamless data movement between on-premises and cloud environments, supporting flexible workload management and data migration strategies.
- Geographic distribution. Organizations with multiple locations can centrally manage backups while enabling different sites to access data from the cloud. This improves data availability, collaboration, and disaster recovery capabilities. Cloud providers often have data centers in multiple geographic regions. This geographic distribution adds an extra layer of redundancy, ensuring that data remains available even if a data center experiences issues.
- Cost optimization. Organizations can optimize costs by using on-premises infrastructure for routine backups and relying on cloud resources only as needed. Cloud resources often use the pay-as-you-go payment model, reducing upfront investment and maintenance costs. Hybrid Cloud Backup helps optimize costs by utilizing on-premises infrastructure for routine backups and cloud resources for additional capacity during peak demands or emergencies.
Drawbacks of Hybrid Cloud Backup
- Complexity and management overhead
- Implementing and managing a hybrid cloud backup solution can be complex, requiring expertise in both on-premises and cloud technologies.
- Administrators need to handle synchronization, data transfer, and management of backup policies across different environments. This can add more difficulties if multiple different public cloud providers are used.
- Data transfer and latency
- Transferring large volumes of data between on-premises and the cloud can be time-consuming and dependent on internet bandwidth.
- Latency might affect data access and recovery times, particularly for cloud-based restores.
- Data security concerns
- Although cloud providers implement advanced security measures, some organizations might still have concerns about entrusting sensitive data to third-party providers.
- Data breaches or unauthorized access to cloud-stored backups could be a risk if not properly managed.
- Vendor lock-in. Adopting a specific cloud provider for backup services might result in vendor lock-in, making it difficult to switch providers or migrate data to another environment.
- Network dependencies. Hybrid cloud backup heavily relies on network connectivity. If network issues occur, it could impact the ability to transfer backups to the cloud or access cloud-stored backups.
- Data compliance and regulations. Some industries have strict data compliance and residency regulations. Ensuring that cloud providers comply with these regulations might require additional efforts.
- Limited control over cloud infrastructure. Cloud services abstract underlying infrastructure, limiting the level of control an organization has over hardware and configurations compared to on-premises solutions.
- Data recovery dependency. Relying solely on cloud backups might create a dependency on external services for data recovery. If the cloud provider experiences issues, data recovery might be affected.
- Data ownership and retention. Clarifying data ownership and retention policies when using cloud services is important to ensure that organizations maintain control over their data.
- Operational dependencies. Organizations might become operationally dependent on cloud services for backup and recovery. This reliance could pose challenges if the cloud provider experiences disruptions.
- Initial setup and migration challenges. Transitioning from traditional backup methods to a hybrid cloud backup model might require time and resources for setup, migration of existing backups, and user training.
- Cost management complexity
- While cloud resources can offer cost savings through pay-as-you-go models, managing and predicting costs across both local and cloud environments can be challenging.
- Poor cost management could lead to unexpected expenses.
Potential costs of cloud storage
The potential costs associated with cloud storage can be considered a disadvantage of hybrid cloud backup. These costs can include:
- Storage costs. Cloud providers typically charge for the amount of storage used. As data volumes grow, storage costs can increase. Organizations need to estimate their storage needs accurately to avoid unexpected expenses.
- Data transfer costs. Uploading data to the cloud and retrieving data from the cloud can incur data transfer charges. These costs can accumulate, particularly if there’s frequent movement of large amounts of data.
- Data access and egress fees. Some cloud providers charge fees for data access and retrieval. Depending on the frequency of data restores or retrievals, these costs can add up over time. Egress fees. Moving data out of the cloud environment, especially if it’s to another cloud provider or back to on-premises infrastructure, might incur egress fees.
- Redundancy and data replication costs. Data replication across multiple regions or data centers for redundancy purposes can result in additional costs. This is especially relevant for organizations with high data availability requirements.
- Inactivity charges. Some cloud providers may impose charges if data remains inactive (i.e., not accessed or modified) for extended periods.
- Cost variability. While cloud storage’s pay-as-you-go model can be cost-effective, cost predictability might be a concern due to fluctuations in data storage needs and usage patterns.
It’s essential to carefully assess these drawbacks in the context of your organization’s specific needs, goals, and resources. Mitigation strategies and proper planning can help address these challenges and ensure a successful hybrid cloud backup implementation.
How to mitigate cost-related issues
There are several steps you can take to mitigate the high costs of cloud storage in a hybrid cloud backup setup:
- Use an incremental backup approach (optionally with periodic synthetic full backups) and deduplication technologies.
- Use the cloud as secondary backup storage and use local backups as primary backups to reduce access and retrieval fees set by cloud providers (such as egress fees). You can also choose vendors with no egress fees, for example, Wasabi.
- Choose cloud storage tiers (such as standard, infrequent access, or archive storage) that match the access patterns of your data.
- Use more cost-efficient media for long-term storage and archival, for example, tape drives.
- Monitor data usage and regularly assess the cost-effectiveness of your storage strategy.
Hybrid Cloud Backup Types
Hybrid cloud backup can encompass different approaches, with specific benefits and aligning with different organizational needs. The choice of backup type depends on factors like data recovery objectives, storage requirements, budget considerations, and the overall IT infrastructure. The main types of hybrid cloud backup are as follows:
- Local-first backup + backup copy to cloud
Backups are created in local, on-premises storage first. The backup is then used to create a backup copy in the cloud for offsite redundancy. This approach provides fast local recovery and uses the cloud for more severe recovery scenarios. It also minimizes the impact on the production environment.
The schedule and retention policy for cloud backup copies can differ from the ones used for the local backup. This way, the cloud is used for tiering where older recovery points are moved to the cloud as they become less frequently accessed. This approach optimizes costs by using cloud storage for less active data while keeping frequently accessed data locally for fast retrieval.
- Cloud-first backup with local cache
In this model, backups are initially taken directly to the cloud. A local cache might be maintained for frequently accessed data, allowing for quicker restores.
This approach is practical when data recovery needs are primarily cloud-oriented but require local access for specific data.
- Two-way cloud replication
Data is continuously synchronized between on-premises infrastructure and the cloud. Changes made in the local or cloud environment are replicated to the other location.
This approach is resource-intensive. However, it ensures that data remains consistent across both environments, allowing for flexible data access and recovery.
- Tiered backup storage
With this strategy, different tiers of data are stored in different locations based on access frequency. Frequently accessed data might be stored locally, while less frequently accessed data is stored in the cloud to optimize costs.
Cloud-based archiving involves moving infrequently accessed or older data to cloud storage to free up space in your on-premises storage systems. Archived data is retained for long-term storage and compliance purposes, but it’s less accessible compared to frequently used data.
- Backup rotation and lifecycle management
This approach involves rotating backup copies between local and cloud environments based on retention policies. Older backups might be moved to the cloud for long-term retention, while recent backups are kept locally for quicker restores.
- Cloud-based disaster recovery
The cloud is primarily used for disaster recovery purposes. By storing backup copies and virtual machine images in the cloud, you can quickly recover entire systems in case of a disaster affecting the local environment, including the local backup infrastructure.
- Hybrid backup appliances
Hybrid appliances combine local backup hardware with cloud integration. These appliances manage data deduplication, encryption, and synchronization between local and cloud backups.
These concepts highlight the various ways organizations can utilize both on-premises and cloud storage to achieve data protection, disaster recovery, cost optimization, and efficient data management. An organization’s approach depends on multiple factors, such as data retention policies, recovery time objectives, data access patterns, and budget considerations.
Setting Up Hybrid Cloud Backup with NAKIVO
NAKIVO Backup & Replication is a data protection solution designed for different infrastructures:
- On-premises, whether physical or virtualized servers
- Cloud, including multi-cloud setups
- Hybrid cloud
The solution supports backup of workloads in local datacenters and in the cloud as well as backup to local data centers and public/private clouds. NAKIVO solution offers a convenient way to implement a hybrid cloud backup strategy by creating a local backup and then creating a backup job to a cloud storage destination. Moreover, these jobs can be automated to run one after the other with the Job Chaining feature. Let’s find out how to set up a hybrid cloud backup with NAKIVO Backup & Replication.

Adding items to the inventory
You can add both local and cloud platforms to the NAKIVO solution inventory to start protecting them. You should also add the destination cloud storage to the inventory.
To add items to the inventory:
- Go to Settings > Inventory and click the + icon.
- Select the needed platform and finish the Add Inventory Item wizard.
Read the detailed explanation about adding different items to the inventory.
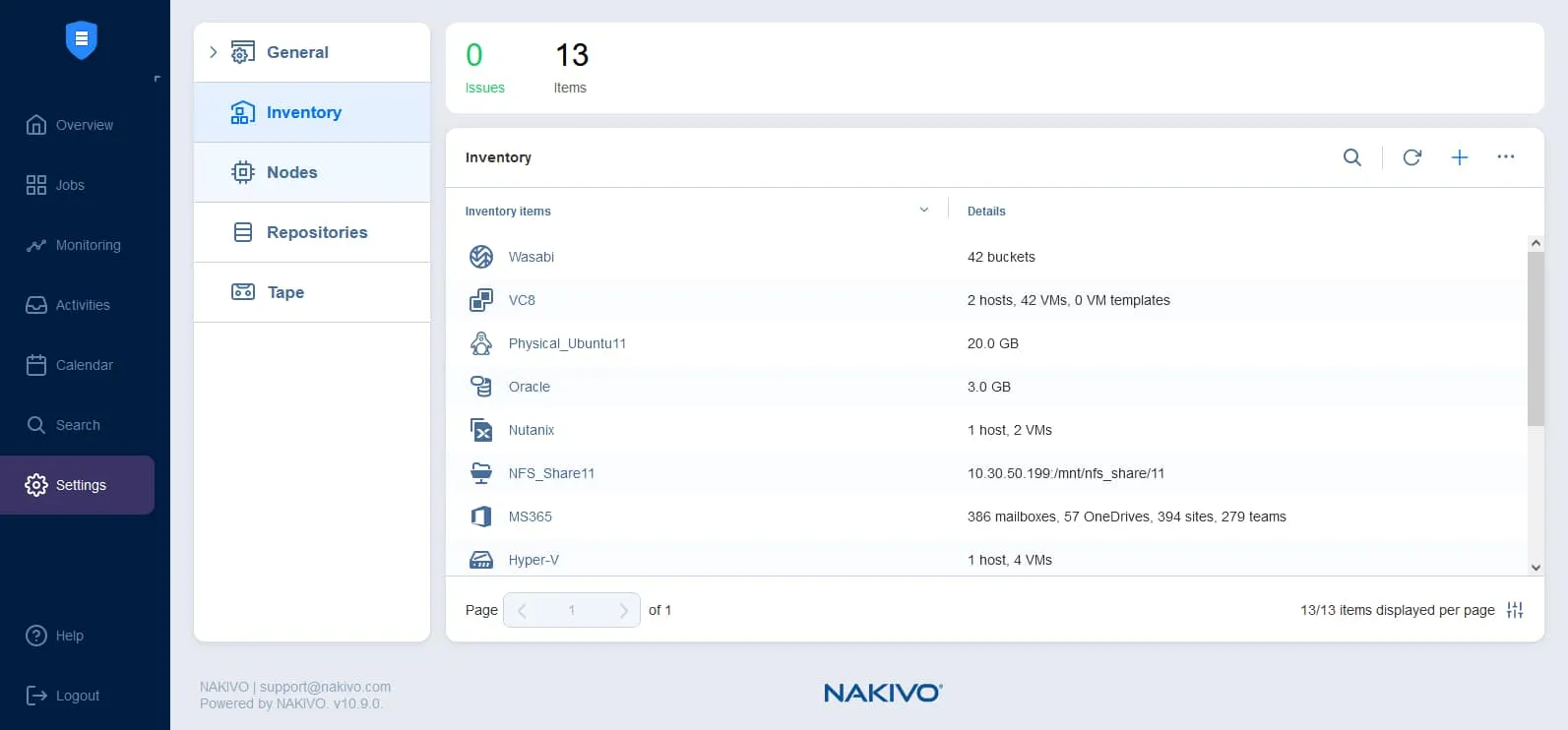
In our example, we add ESXi hosts, which are part of VMware vSphere, as the source platform as well as Amazon S3 storage to create a backup copy to cloud.
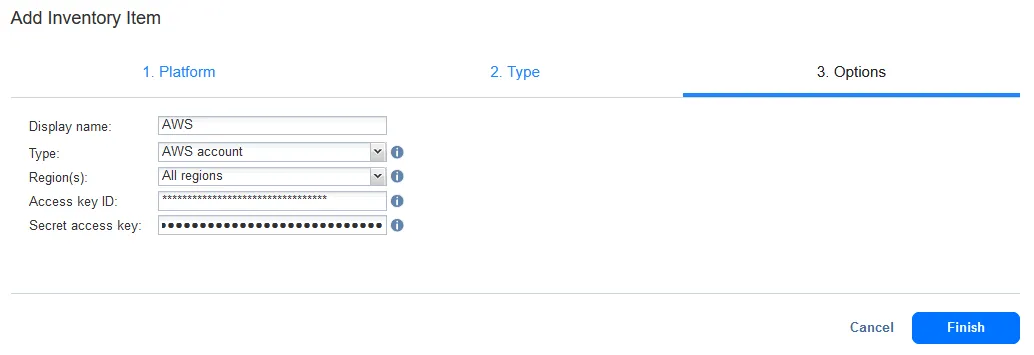
To add Amazon S3 or other cloud destination:
- Select Storage at the first step of the Add Inventory Item wizard to add cloud storage.
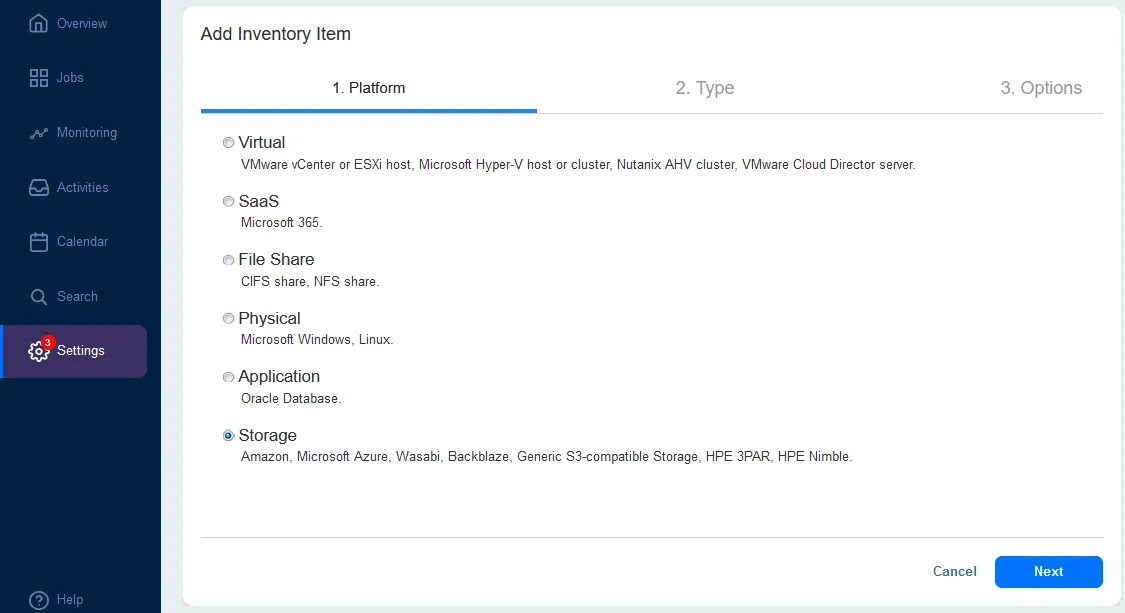
- For Type, select Amazon S3 or another cloud platform. You can add one of the supported cloud storage accounts:
- Amazon S3
- Generic S3 compatible object storage in the cloud
- Microsoft Azure Storage
- Wasabi
- BackBlaze B2
- For Options, enter the needed connection options.
Creating a repository on-premises
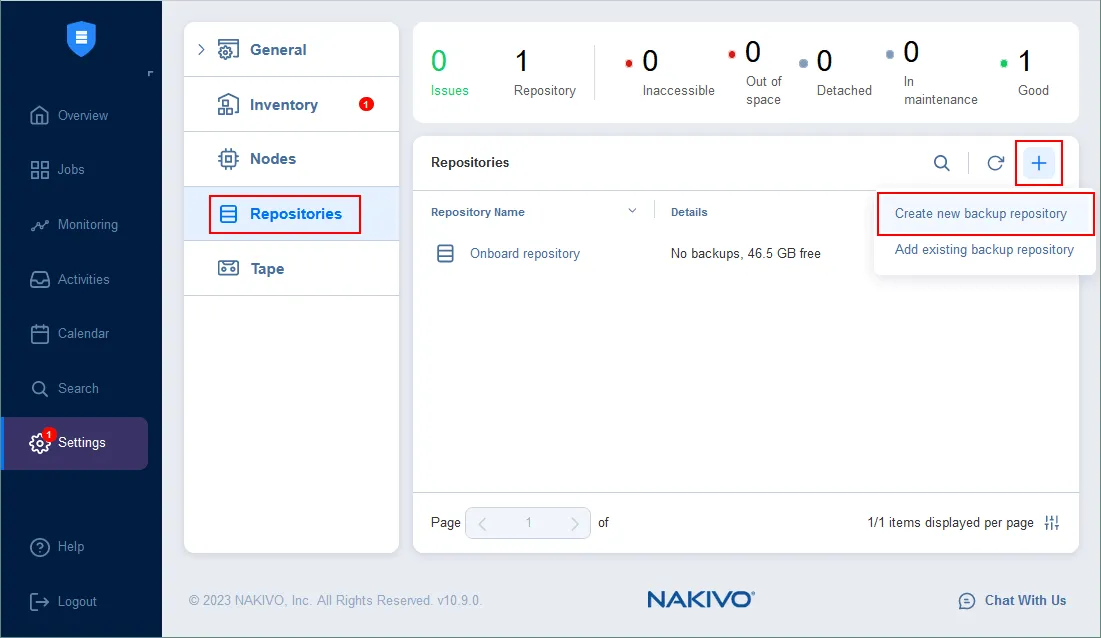
Create a backup repository in your local infrastructure or use the Onboard Backup Repository. Go to Settings > Repositories and click + to create a new backup repository.
You can create a backup repository using a local folder on a machine with an installed Transporter, which can be a NAS device or a deduplication appliance. You can also use alternative repository locations in the on-premises infrastructure and create a backup repository on an SMB share or NFS share.
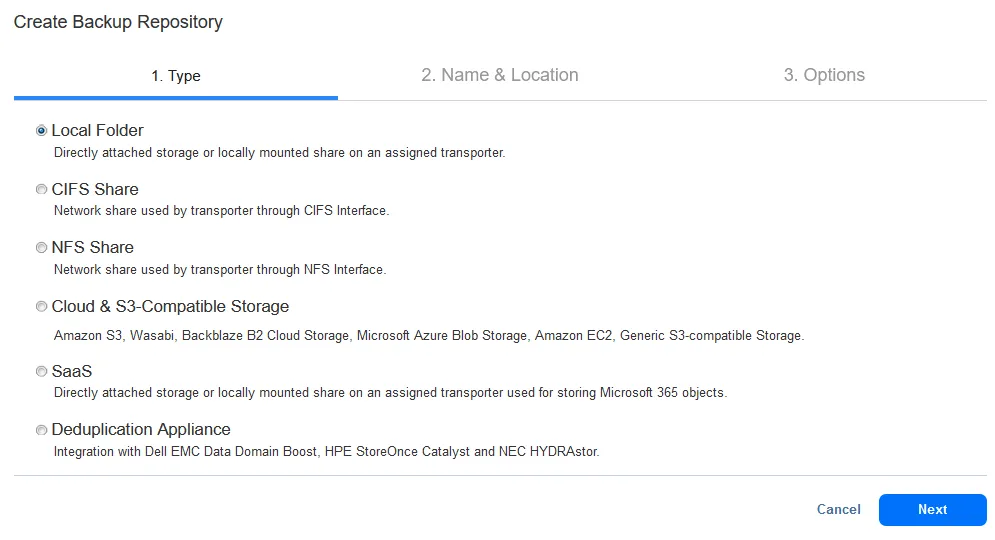
Follow the wizard steps to finish creating a backup repository of the appropriate type. You can enable data encryption when creating a backup repository.
Creating a repository in a public cloud
Create a backup repository in the cloud. Go to Settings > Repositories and click + to create a new backup repository. Follow the instructions to create a backup repository in the public cloud:
- Create a repository in Amazon S3
- Create a repository in Azure Blob Storage
- Create a repository in Amazon EC2
- Create a repository in BackBlaze B2 cloud storage
- Create a repository in Wasabi Hot Cloud storage
As we use Amazon S3 in this example, we select Cloud & S3-Compatible Storage as the repository type and then Amazon S3 in the Create Backup Repository wizard.
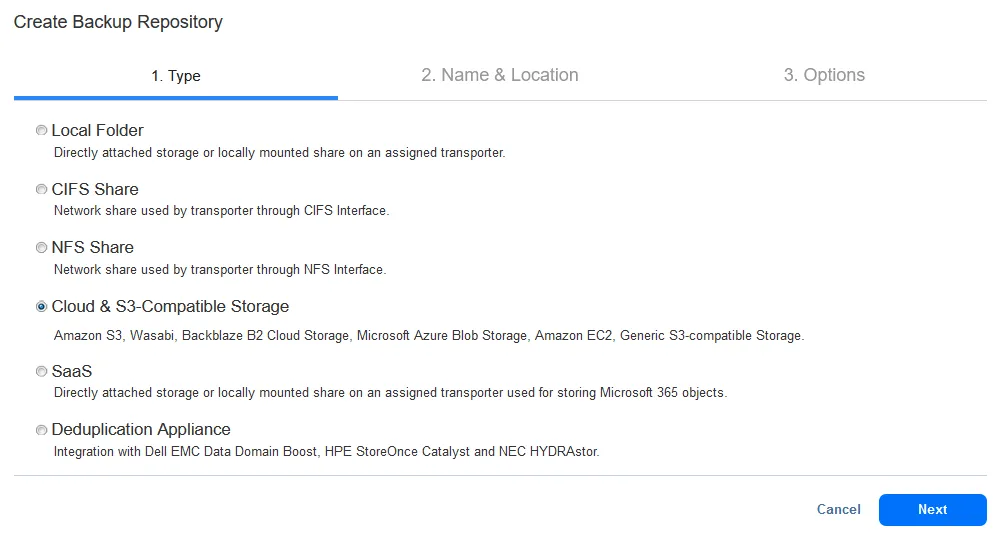
You must have at least one backup repository on-premises and then create a backup repository in a public cloud. Our backup repositories are displayed in the screenshot below. You can have more than one repository on-premises and in the public cloud for higher flexibility and scalability.
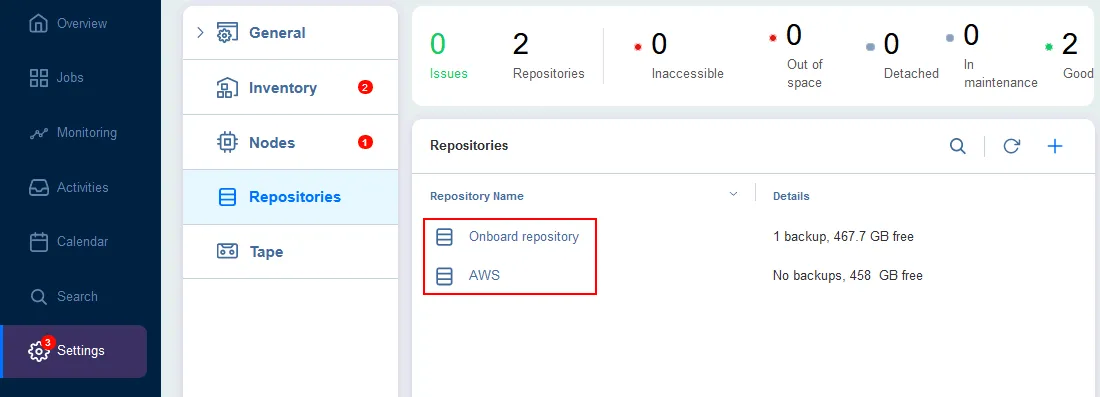
Configuring a local backup job
In our example, we create 2 backup jobs: a backup job to on-premises storage for quick operational recovery and a backup copy job to an Amazon S3 bucket to be used when our on-premises backup infrastructure is not available.
Let’s configure a backup job for data backup to the on-premises backup repository.
Click Jobs in the left panel, click + and hit VMware vSphere backup job or other backup job type, depending on what you want to back up.
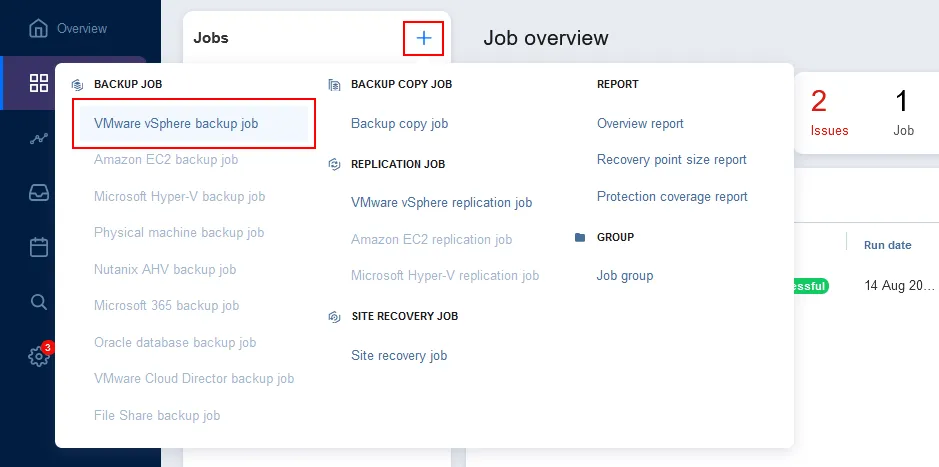
Follow the instructions to create a new backup job for the appropriate data source.
As we are backing up VMware virtual machines in this walkthrough, we follow the instructions for creating a VMware vSphere backup job. You must complete the wizard to create a backup job:
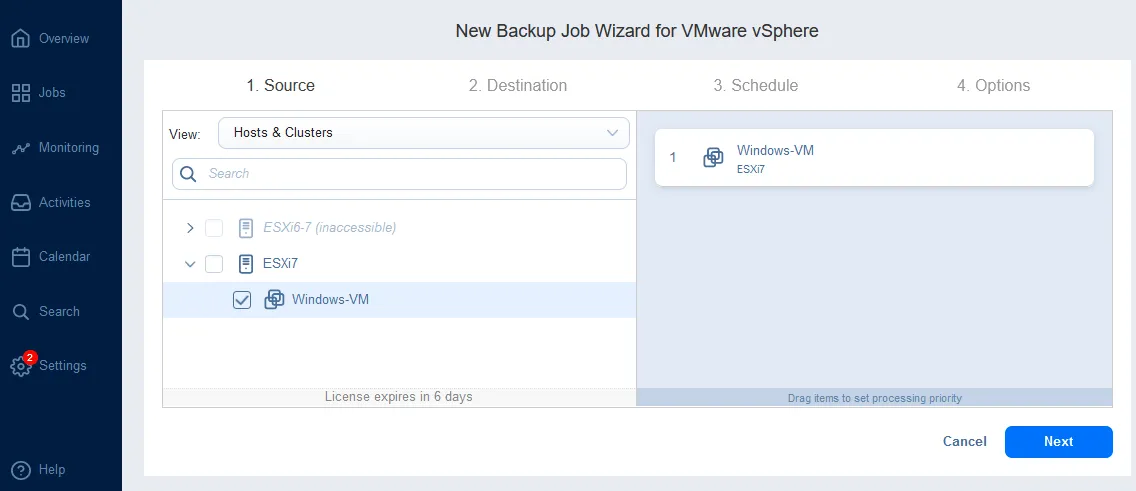
- Source. Select the items you want to back up. We select a Windows VM residing on an ESXi host.
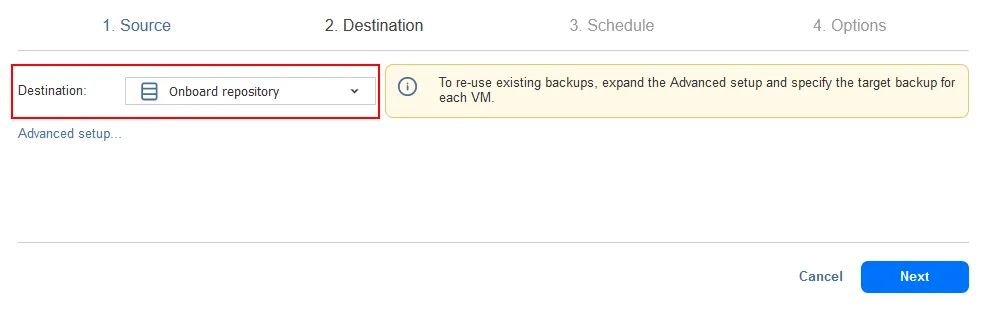
- Destination. Select one of the backup repositories you have deployed on-premises. We are using the Onboard repository located on the local machine where NAKIVO Backup & Replication (Full solution) is installed as our primary repository.
- Schedule. Set the schedule for a backup job to define when to back up data to the on-premises backup repository. We configure a backup job to be executed every day at 0:00 AM. You can configure multiple schedule and retention rules at this step.
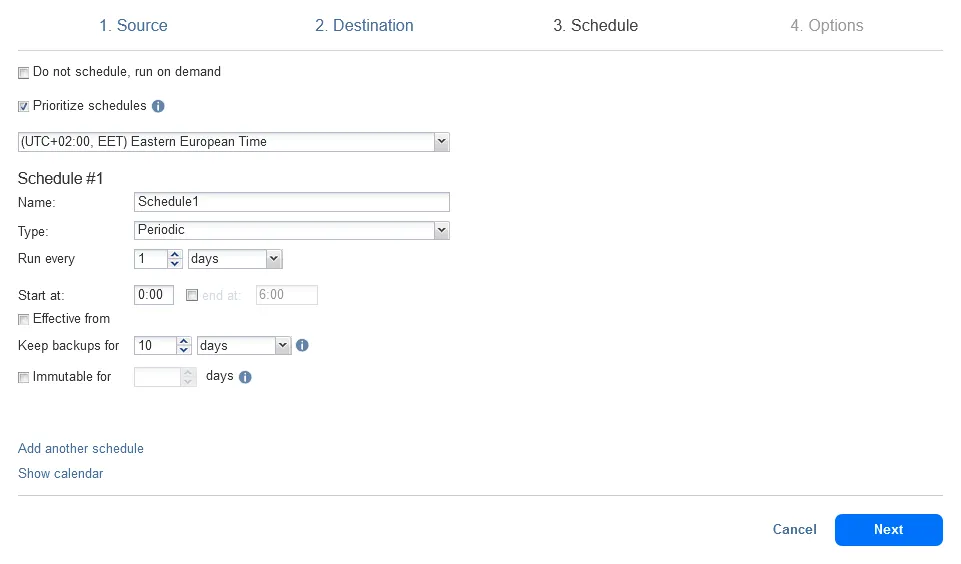
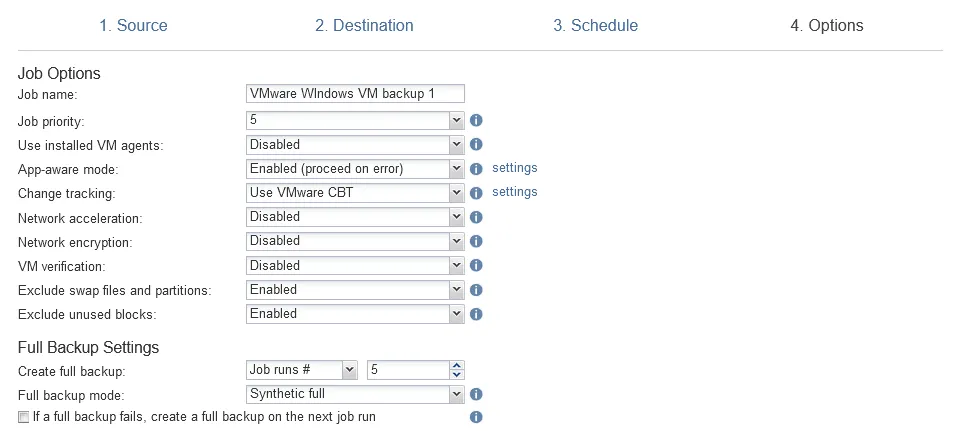
- Options. Enter a backup job name and configure other backup job options. For example, you can enable network encryption to protect data in flight, use Network acceleration, exclude swap files, partitions, and unused blocks to speed up data transfers, etc. Complete the wizard.
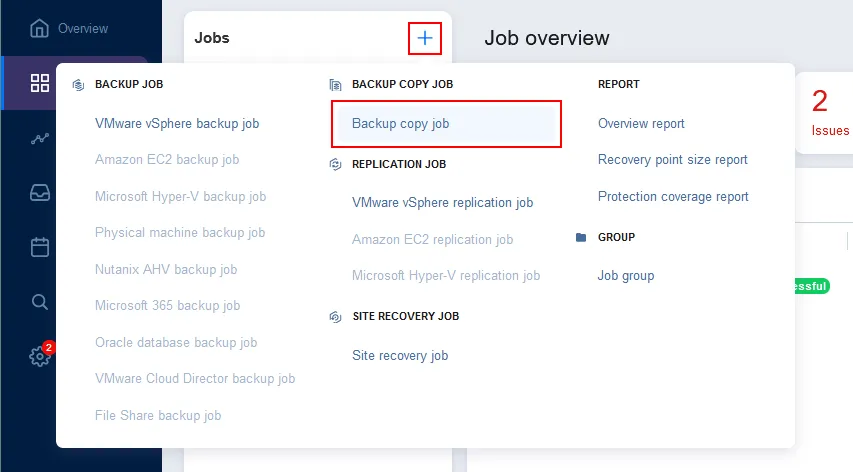
Configuring a backup copy job to the cloud
Configure backup copy to the cloud for a hybrid cloud backup setup.
Click Jobs in the left pane, hit + and click Backup copy job in the menu that opens. The New Backup Copy Job Wizard opens.
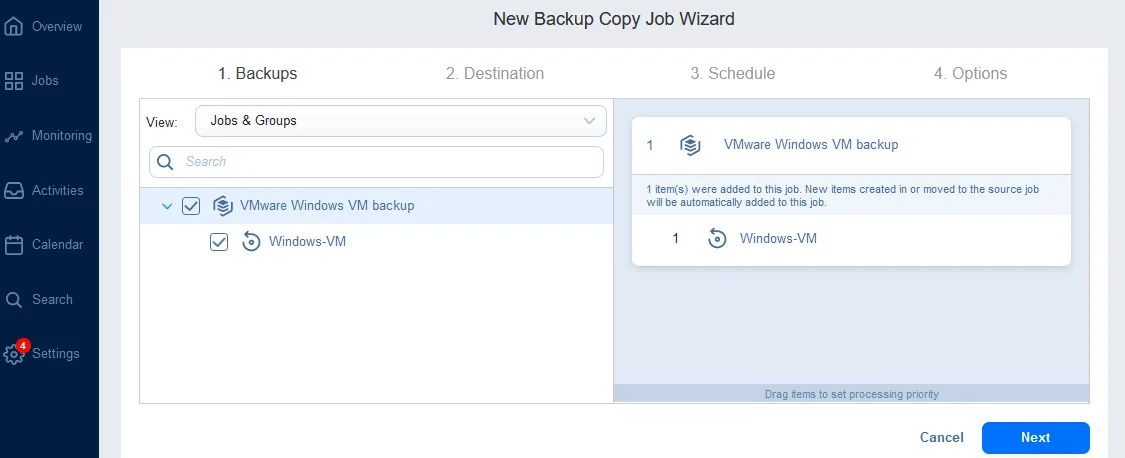
- Backups. Select the backup job you have created and run earlier. In our case, we select the VMware Windows VM backup job with all VM backups created by this job.
- Destination. Select the backup repository you have created in the public cloud. We select the S3 backup repository as the destination in our case.
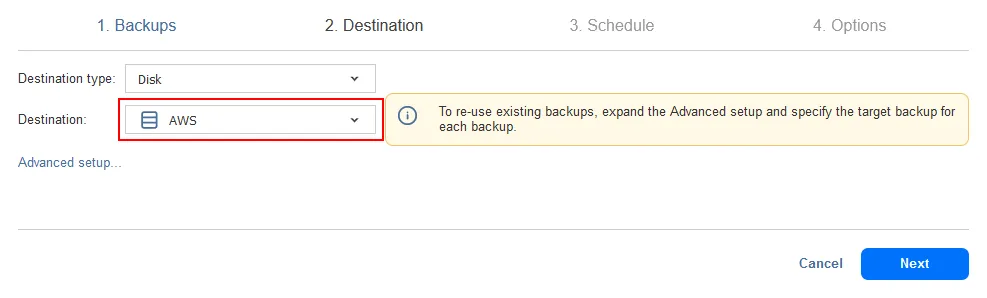
- Schedule. Configure a schedule and retention policy for the backup copy job. As we configured the on-premises backup to be run every day at 0:00 AM, we configure the backup copy to cloud to be started every day at 3:00 AM. Our VM is not large and the on-premises backup job should finish by 3:00 AM. Alternatively, you can use Job Chaining for the backup copy job to be launched automatically after a successful backup job.
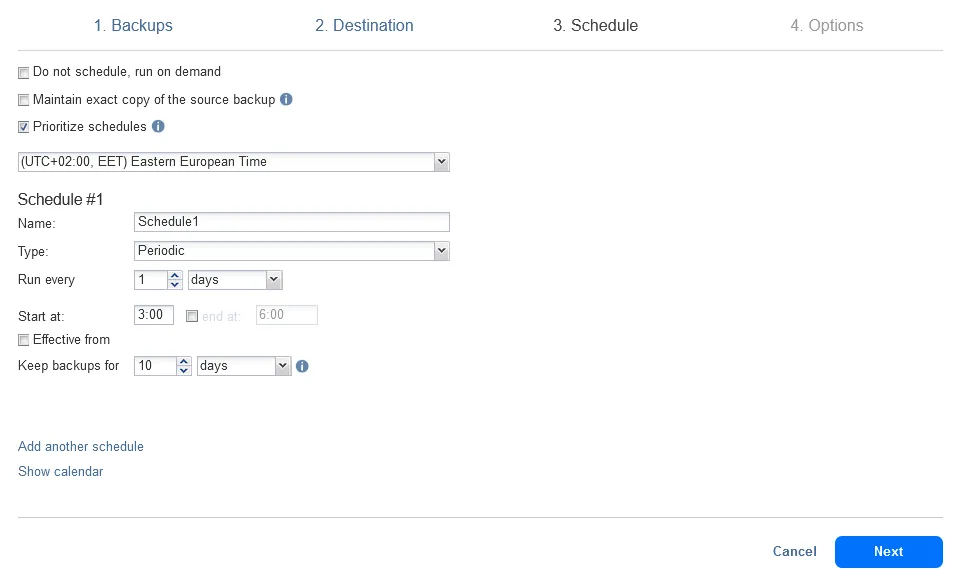
- Options. Enter a backup copy job name, select the needed options, such as network acceleration or network encryption and hit Finish or Finish & Run.
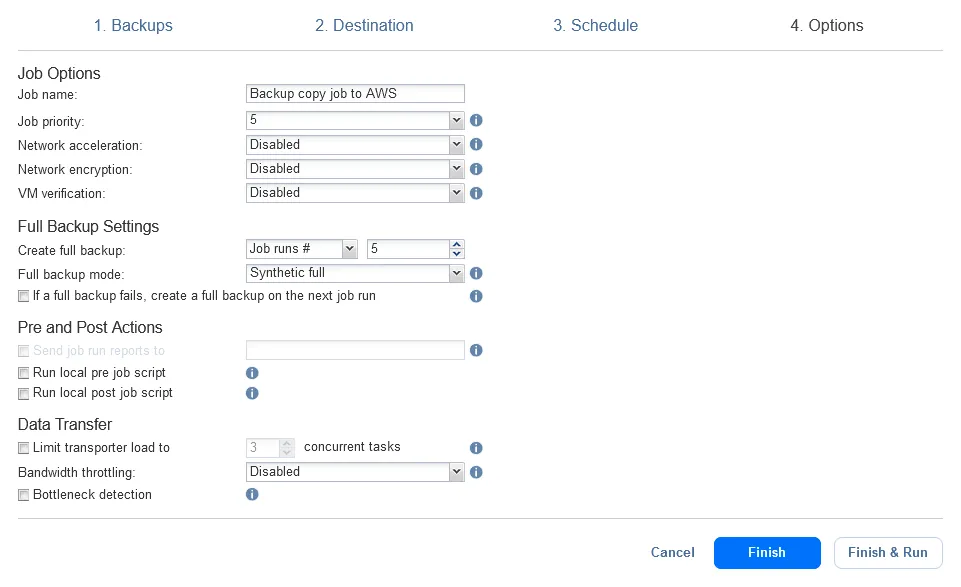
We have configured hybrid cloud backup in NAKIVO Backup & Replication. Wait until the on-premises backup and backup copy to cloud jobs are completed.
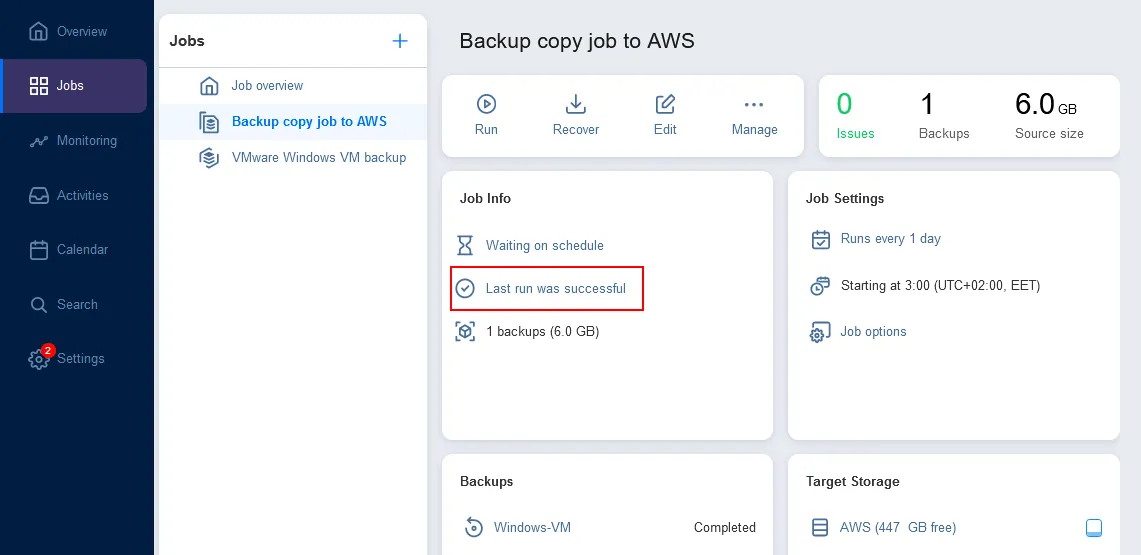
Now you have two backups in different locations to use for recovery: local backup + cloud backup. Such a hybrid cloud backup approach combines the benefits of quick access and local availability with the redundancy and reliability of cloud-based backups.


