
Fundamentos de protección de datos: Cómo hacer backup de un bucket de Amazon S3
Amazon S3 es un almacenamiento en la nube fiable proporcionado por Amazon Web Services (AWS). Los archivos se almacenan como objetos en buckets de Amazon S3. Este almacenamiento es muy utilizado para almacenar backups de datos debido a la alta fiabilidad de Amazon S3. A diferencia de Amazon Elastic Block Storage (EBS), donde los datos redundantes se almacenan en una zona de disponibilidad, en Amazon S3 los datos redundantes se distribuyen en varias zonas de disponibilidad.
Si un centro de datos de una zona deja de estar disponible, puede acceder a los datos de otra zona. En algunos casos, es posible que necesite hacer backup de los datos almacenados en buckets de Amazon S3 para evitar la pérdida de datos causada por errores humanos o fallos de software. Los datos pueden borrarse o corromperse si un usuario que tiene acceso a un bucket de S3 borra datos o corrompe datos escribiendo cambios no deseados. Un fallo del software puede provocar resultados similares.

Control de versiones de Amazon S3
El control de versiones de objetos es una función eficaz de Amazon S3 que protege los datos de un bucket contra la corrupción, la escritura de cambios no deseados y la eliminación. Cuando se realizan cambios en un archivo (que se almacena como un objeto en S3), se crea una nueva versión del objeto. Múltiples versiones del mismo objeto se almacenan en un cubo. Puede acceder a versiones anteriores del objeto y restaurarlas. Si se borra el objeto, se le aplica el «marcador de borrado», pero se puede invertir esta acción y abrir una versión anterior del objeto antes de borrarlo. El control de versiones de Amazon S3 puede utilizarse sin necesidad de software adicional para hacer backups de S3.
Puede utilizar la política de ciclo de vida para definir durante cuánto tiempo deben almacenarse las versiones en un bucket de S3 para tener una forma de backup en Amazon S3. Los costes adicionales de almacenamiento de versiones adicionales no deberían ser elevados si se configura correctamente la política de ciclo de vida y las nuevas versiones sustituyen a las más antiguas. Las versiones antiguas pueden eliminarse o trasladarse a un almacenamiento más rentable (por ejemplo, almacenamiento en frío) para optimizar los costes.
Cómo activar el control de versiones de AWS S3
Inicie sesión en la consola de administración de AWS utilizando la cuenta con permisos suficientes. Haga clic en Servicios y seleccione S3 en la categoría Almacenamiento.
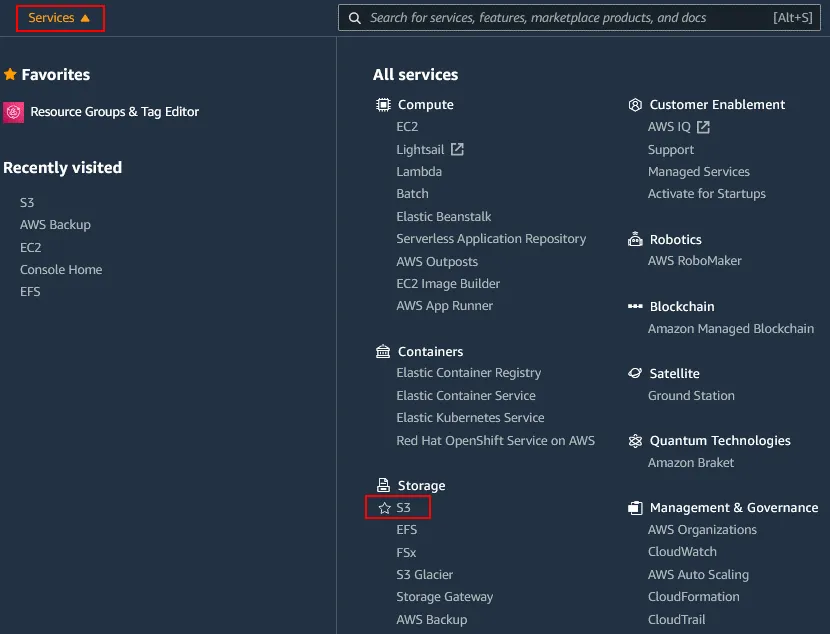
En el panel de navegación, haga clic en Buckets y seleccione el bucket de S3 necesario para el que desea activar el control de versiones. En este ejemplo, selecciono el bucket con el nombre blog-bucket01. Haga clic en el nombre del cubo para abrir los detalles del cubo.
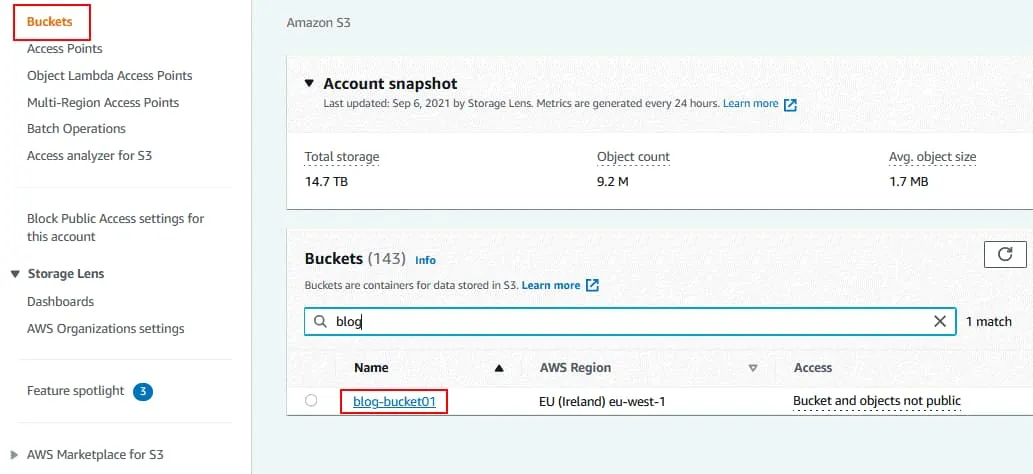
Abra la pestaña Propiedades del cubo seleccionado.
En la sección Control de versiones de cubos, haga clic en Editar.
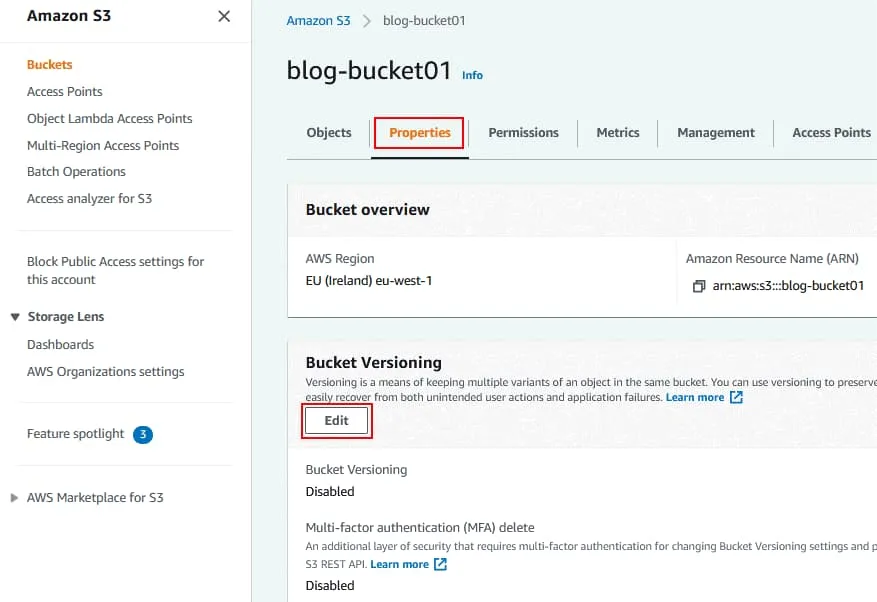
El control de versiones de los cubos está desactivado por defecto.
Haga clic en Activar para activar el control de versiones de cubos.
Haga clic en Guardar cambios.
Se muestra un aviso de que puede que necesite subirdate sus reglas de ciclo de vida. Este es el siguiente paso.
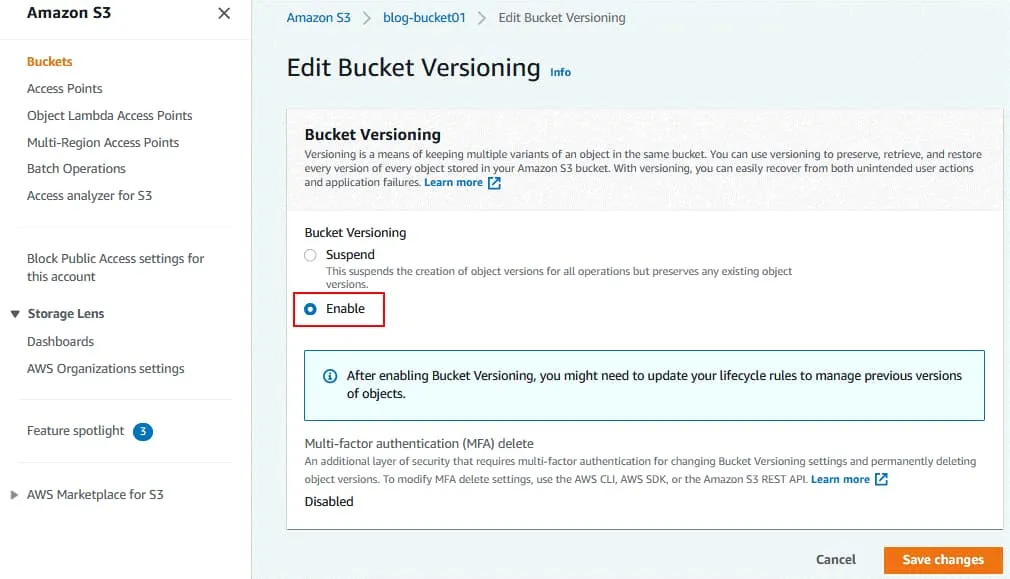
El mensaje se muestra en la parte superior de la página si se han aplicado los cambios de configuración: Control de versiones del cubo editado correctamente.
Normas del ciclo de vida
Para configurar las reglas del ciclo de vida para el control de versiones de Amazon S3, vaya a la pestaña Administración de la página del bucket seleccionado. En la sección Reglas del ciclo de vida, haga clic en Crear regla del ciclo de vida.
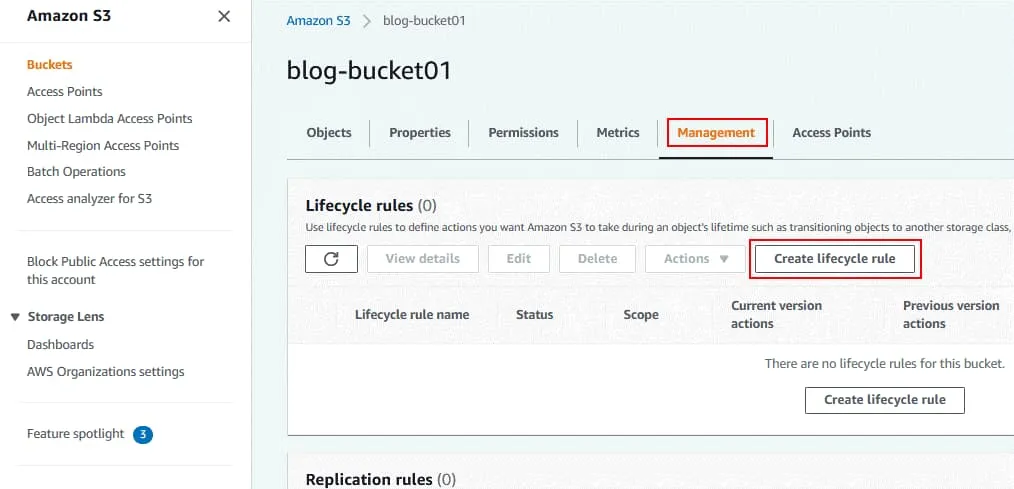
Se abre la página Crear regla del ciclo de vida.
Configuración de las reglas del ciclo de vida. Introduzca el nombre de la regla del ciclo de vida, por ejemplo, Ciclo de vida del blog 01.
Seleccione el ámbito de aplicación de la regla. Puede aplicar filtros para aplicar reglas de ciclo de vida a objetos específicos o aplicar la regla a todos los objetos del bucket.
Defina etiquetas de objeto para señalar los objetos a los que deben aplicarse acciones del ciclo de vida. Introduzca una clave y un valor en los campos correspondientes y haga clic en el botón Añadir etiqueta para añadirla o en el botón Quitar para eliminarla.
Acciones de la regla de ciclo de vida. Seleccione las acciones que desea que realice esta regla:
- Transición de versiones actuales de objetos entre clases de almacenamiento
- Transición de versiones anteriores de objetos entre clases de almacenamiento
- Expiración de las versiones actuales de los objetos
- Eliminar permanentemente las versiones anteriores de los objetos
- Eliminar marcadores de borrado caducados o cargas multiparte incompletas

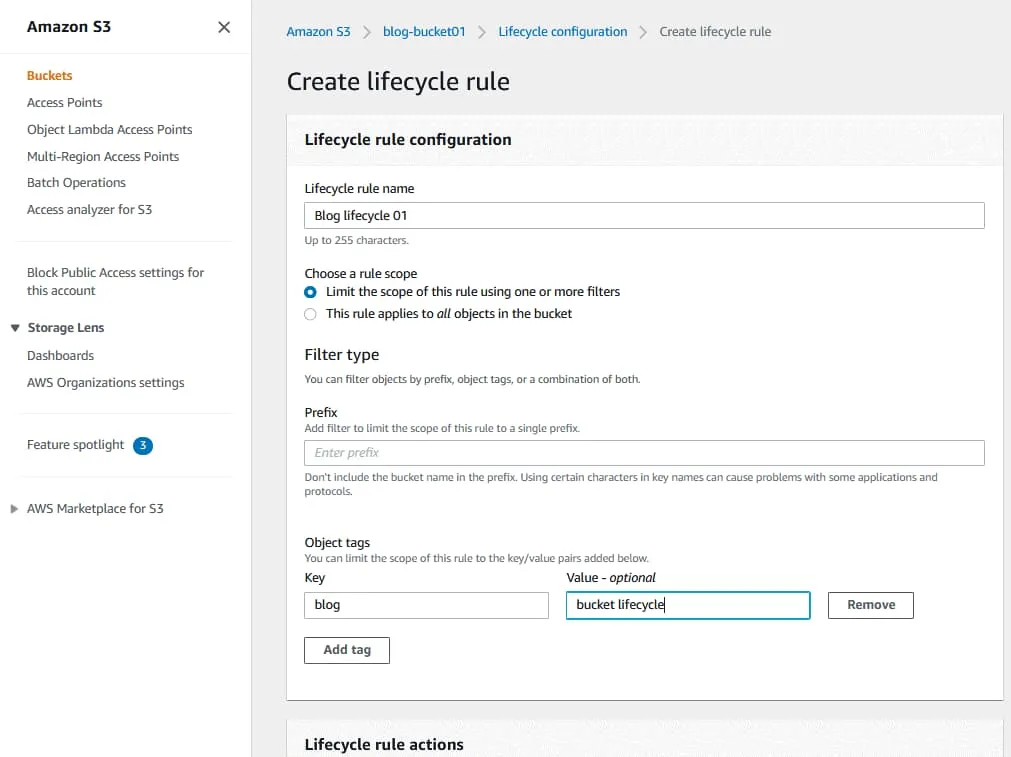
Transición de versiones no actuales de objetos entre clases de almacenamiento.
Seleccione las transiciones de clase de almacenamiento y el número de días tras los cuales los objetos dejan de ser actuales.
En mi ejemplo, los objetos se mueven de la clase de almacenamiento S3 actual a Standard-IA después de 35 días.
Elimine permanentemente las versiones anteriores de los objetos.
Introduzca el número de días tras los cuales deben eliminarse las versiones anteriores. El valor debe ser superior al número de días tras los cuales los objetos pasan a ser no corrientes. En mi ejemplo, los objetos se borran definitivamente al cabo de 40 días.
Haga clic en Crear regla para crear una regla de ciclo de vida.
Replicar el cubo
Como alternativa a las backups automáticas de Amazon S3, puede replicar el bucket entre regiones. Es necesario crear un segundo bucket que sea el bucket de destino en otra región y crear una regla de replicación. Tras crear la regla de replicación, todos los cambios realizados en el bucket de origen se reflejan automáticamente en el bucket de destino.
Busque la sección Reglas de replicación en la pestaña Gestión de su bucket de origen y haga clic en Crear regla de replicación.
Se abre la página Crear regla de replicación.
Introduzca un nombre de regla de replicación, por ejemplo, Blog S3 bucket replication.
Define el estado de la regla cuando se crea(activada o desactivada).
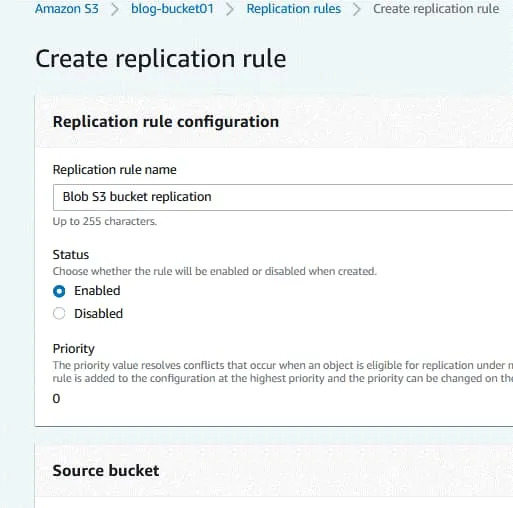
Cubo fuente. El bucket de origen ya ha sido seleccionado(blog-bucket01).
Elija un ámbito de aplicación de la regla. Puede utilizar la regla de replicación para todos los objetos del bucket o configurar filtros y aplicar la regla a objetos personalizados.
Destino. Introduzca el nombre del cubo de destino o haga clic en Examinar S3 y seleccione un cubo de la lista. Puede seleccionar un cubo en esta cuenta o en otra. Si el control de versiones de AWS S3 está habilitado para el bucket de origen, el control de versiones de objetos también debe estar habilitado para el bucket de destino. Se muestra una región de destino para el cubo de destino seleccionado.
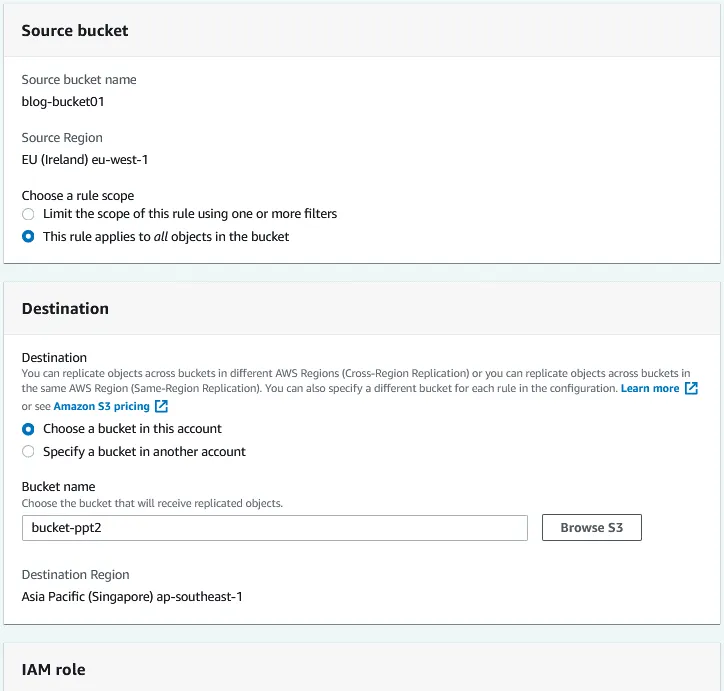
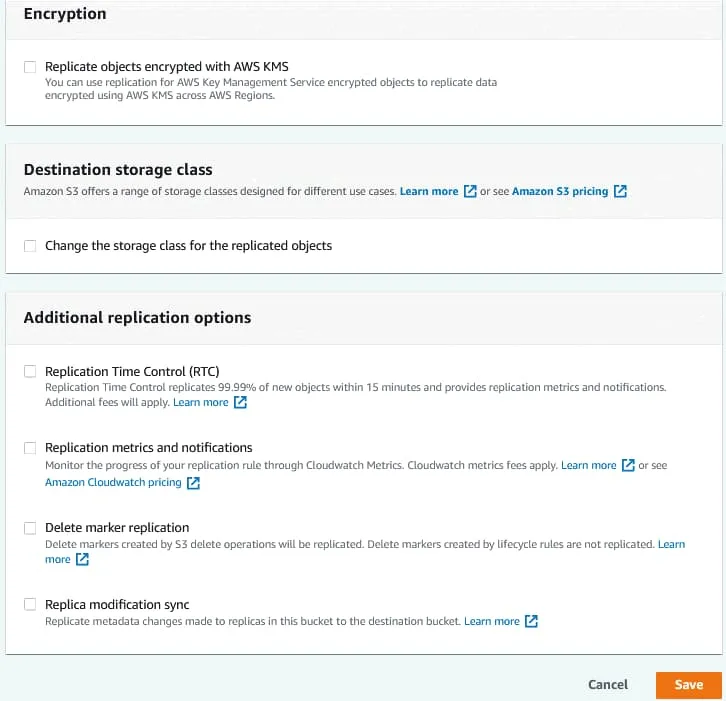
Configure la función de gestión de identidades y accesos (IAM) y, a continuación, seleccione una clase de almacenamiento y opciones de replicación adicionales. Haga clic en Guardar para guardar la configuración y crear una regla de replicación para el bucket.
AWS S3 Backup en la CLI
AWS CLI es la potente interfaz de línea de comandos para trabajar con diferentes servicios de Amazon, incluido Amazon S3. Existe un útil comando sync que permite hacer backup de buckets de Amazon S3 en una máquina Linux copiando archivos del bucket a un directorio local en Linux que se ejecuta en una instancia EC2.
Una función del comando sync en la CLI de AWS es que los archivos de un sistema de archivos local (destino del backup en Amazon S3) no se eliminan si estos archivos faltan en el bucket de S3 de origen y viceversa. Esto es importante para hacer backups de AWS S3 porque si algunos archivos se borraron accidentalmente en el bucket de S3, los archivos existentes no se borran en el directorio local de una máquina Linux después de la sincronización.
Ventajas:
- Compatibilidad con grandes buckets de S3 y escalabilidad
- Se admiten varios subprocesos durante la sincronización
- La posibilidad de sincronizar sólo archivos nuevos y actualizadosdated
- Alta velocidad de sincronización gracias a algoritmos inteligentes
Desventajas:
- Linux ejecutándose en una instancia EC2 consume el espacio de almacenamiento de los volúmenes EBS. Los costes de almacenamiento de los volúmenes EBS son superiores a los de los buckets S3.
En este tutorial se utilizan comandos para Ubuntu Server.
En primer lugar, debe instalar AWS CLI.
Subirdate el árbol de repositorios:
sudo apt-get update
Instalar AWS CLI:
sudo apt install awscli
o
Instalar unzip:
sudo apt install unzip
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscli-exe-linux-x86_64.zip
sudo ./aws/install
Compruebe las credenciales de AWS en Linux ejecutándose en su instancia EC2.
aws configure list
Añada credenciales para acceder a AWS con AWS CLI desde la instancia Linux si no se han establecido las credenciales:
aws configure
Introduzca los siguientes parámetros:
ID de la clave de acceso de AWS
Clave de acceso secreta de AWS
Nombre por defecto de la región
Formato de salida predeterminado
Cree un directorio para almacenar su backup de Amazon S3. En mi ejemplo, creo el directorio ~/s3/ para almacenar los backups de S3 y un subdirectorio con un nombre idéntico al nombre del bucket. Los archivos almacenados en el bucket de S3 deben copiarse en este directorio local de la máquina Linux. ~ es el directorio home de un usuario, que en mi caso es /home/ubuntu.
mkdir -p ~/s3/your_bucket_name
Sustituye tu_nombre_bucket por el nombre de tu bucket(blog-bucket01 en nuestro ejemplo).
mkdir -p ~/s3/blog-bucket01
Sincronice el contenido del bucket con su directorio local en la instancia EC2 que ejecuta Linux:
aws s3 sync s3:// blog-bucket01 /home/ubuntu/s3/ blog-bucket01/
Si la configuración de credenciales, el nombre del bucket y la ruta de destino son correctos, los datos deberían empezar a descargarse del bucket de S3. El tiempo necesario para finalizar la operación depende del tamaño de los archivos del cubo y de la velocidad de tu conexión a Internet.
Amazon S3 backups automáticos
Puede configurar los jobs de backups automáticos de Amazon S3 con la sincronización de la CLI de AWS. Cree un archivo de script sync.sh para ejecutar AWS S3 backups (sincronizar archivos de un bucket de S3 a un directorio local en su instancia de Linux) y, a continuación, ejecute este script de forma programada.
nano /home/ubuntu/s3/sync.sh
#!/bin/sh
# Display the current date and time
echo '-----------------------------'
date
echo '-----------------------------'
echo ''
# Display the script initialization message
echo 'Syncing remote S3 bucket...'
# Running the sync command
/usr/bin/aws s3 sync s3://{BUCKET_NAME} /home/ubuntu/s3/{BUCKET_NAME}/
# Echo "Script execution is completed"
echo 'Sync complete'
Sustituya {BUCKET_NAME} por el nombre del bucket de S3 del que desea hacer backup de.
Se define la ruta completa a aws (binario CLI de AWS) para que crontab ejecute la aplicación aws correctamente en el entorno shell utilizado por crontab.
Hacer ejecutable el script:
sudo chmod +x /home/ubuntu/s3/sync.sh
Ejecute el script para comprobar si funciona:
/home/ubuntu/s3/sync.sh
Edita crontab (un planificador en Linux) del usuario actual para programar la ejecución del script de backups de Amazon S3.
crontab -e
Es posible que tenga que seleccionar un editor de texto para editar la configuración de crontab.
El formato de crontab para programar tareas es el siguiente:
m h dom mon dow command
Donde: m – minutos; h – horas; dom – día del mes; dow – día de la semana.
Añadamos una línea de configuración para que la tarea ejecute la sincronización cada hora y guarde los resultados de los backups de AWS S3 en el archivo de registro. Añada esta línea al final de la configuración de crontab.
0 * * * * /home/ubuntu/s3/sync.sh > /home/ubuntu/s3/sync. log
El backup automático de Amazon S3 está configurado. El archivo de registro puede utilizarse para comprobar la ejecución de las tareas de sincronización.
Conclusión
Hay varios métodos para hacer backups de Amazon S3 y dos de ellos han sido cubiertos en esta entrada del blog. Puede activar el control de versiones de objetos de un bucket para conservar las versiones anteriores de los objetos, lo que le permite obtener archivos si se han escrito en ellos cambios no deseados. La replicación de Amazon S3 es otra herramienta nativa para realizar una copia de los archivos almacenados en un bucket de Amazon S3 como objetos. En este caso, los objetos se replican de un cubo a otro. También puede hacer backups de un bucket de Amazon S3 mediante la herramienta de sincronización de la CLI de AWS, que permite sincronizar los archivos de un bucket con un directorio local de una máquina Linux que se ejecute en una instancia de EC2. El backup automático de Amazon S3 se puede programar utilizando un script y crontab.
En general, el almacenamiento en la nube de Amazon S3 es muy fiable y hacer backups en Amazon S3 es una práctica habitual. Si tiene una estrategia sólida de protección de datos y una estrategia de backup de AWS, debería tener una copia de backup. En este caso, se recomienda hacer backup de los datos en Amazon S3 y en otra ubicación de destino. Utilice NAKIVO Backup & Replication para proteger sus datos en máquinas físicas y virtuales. NAKIVO Backup & Replication es un sólido software de copia de seguridad de virtualización que se puede utilizar para proteger máquinas virtuales, así como instancias de Amazon EC2 y máquinas físicas.


