
Introducción a Amazon S3: Cómo funciona el almacenamiento de objetos en la nube
Amazon Simple Storage Service (S3) es un popular servicio de almacenamiento en la nube que forma parte de Amazon Web Services (AWS). El almacenamiento en la nube Amazon S3 proporciona alta fiabilidad, flexibilidad, escalabilidad y accesibilidad. El número de objetos y la cantidad de datos almacenados en Amazon S3 son ilimitados. El almacenamiento en la nube S3 es atractivo para las empresas porque sólo pagas por lo que usas.
Sin embargo, la terminología y la metodología pueden dar lugar a malentendidos y dificultades para los nuevos usuarios de Amazon S3. ¿Dónde se almacenan los datos del S3? ¿Cómo funciona el almacenamiento en Amazon S3? Esta entrada del blog explica los conceptos principales y el principio de funcionamiento del almacenamiento en la nube Amazon S3.

Acerca del almacenamiento en Amazon S3
Amazon S3 fue el primer servicio en la nube de AWS y se lanzó en 2006. Desde entonces, la popularidad de este servicio de almacenamiento no ha dejado de crecer. Ahora Amazon proporciona una amplia lista de otros servicios en la nube, pero el almacenamiento en la nube Amazon S3 es el más utilizado. Además del almacenamiento de Amazon S3, AWS ofrece volúmenes de Amazon EBS para EC2 y Amazon Drive. Pero los tres servicios tienen usos y finalidades diferentes.
Los volúmenes EBS (Elastic Block Storage) para instancias EC2 (Elastic Compute Cloud) son discos virtuales para máquinas virtuales que residen en la nube de Amazon. Como se puede entender por el nombre de EBS, se trata de un almacenamiento en bloque en la nube que es el análogo de las unidades de disco duro en los ordenadores físicos. Se puede instalar un sistema operativo en un volumen EBS adjunto a una instancia EC2.
Amazon Drive (antes conocido como Amazon Cloud Drive) es el análogo de Google Drive y Microsoft OneDrive. Amazon Drive tiene una gama de funciones más reducida que Amazon S3. Amazon Drive se posiciona como un servicio de almacenamiento en la nube para hacer backup de fotos y otros datos del usuario.
El almacenamiento en la nube Amazon S3 es un servicio de almacenamiento basado en objetos. No se puede instalar un sistema operativo cuando se utiliza el almacenamiento de Amazon S3 porque no se puede acceder a los datos a nivel de bloque como lo requiere un sistema operativo. Si necesita montar el almacenamiento de Amazon S3 como unidad de red en su sistema operativo, utilice un sistema de archivos en el espacio de usuario. Lee la entrada del blog sobre cómo montar el almacenamiento en la nube S3 en diferentes sistemas operativos. Google Cloud es el análogo del almacenamiento en la nube Amazon S3.
Conceptos principales de Amazon S3
Si va a utilizar Amazon S3 por primera vez, es posible que algunos conceptos le resulten inusuales y desconocidos. La metodología de almacenamiento de datos en la nube S3 es diferente del almacenamiento de datos en unidades de disco duro tradicionales, unidades de estado sólido o matrices de discos. A continuación se ofrece una descripción general de los principales conceptos y tecnologías utilizados para almacenar y administrar datos en el almacenamiento en la nube Amazon S3.
¿Cómo almacena S3 los archivos?
Como se ha explicado anteriormente, los datos en Amazon S3 se almacenan como objetos. Este enfoque proporciona un almacenamiento altamente escalable en la nube. Los objetos pueden estar ubicados en diferentes unidades de disco físicas distribuidas por un centro de datos. En los centros de datos de Amazon se utilizan hardware, software y sistemas de archivos distribuidos especiales para proporcionar una gran escalabilidad. La redundancia y el control de versiones son funciones que se implementan utilizando el enfoque de almacenamiento en bloques. Cuando un archivo se almacena en Amazon S3 como un objeto, se almacena en varios lugares (como en discos, en centros de datos o zonas de disponibilidad) simultáneamente de forma predeterminada. El servicio Amazon S3 comprueba periódicamente la coherencia de los datos verificando las sumas hash de control. Si se detecta corrupción de datos, el objeto se recupera utilizando los datos redundantes. Los objetos se almacenan en buckets de Amazon S3. Por defecto, se puede acceder a los objetos del almacenamiento de Amazon S3 y administrarlos a través de la interfaz web.
¿Qué es el almacenamiento de objetos S3?
El almacenamiento de objetos es un tipo de almacenamiento en el que los datos se guardan como objetos y no como bloques. Este concepto es útil para hacer backups de datos, archivar y escalar en entornos de alta carga.
Los objetos son las entidades fundamentales del almacenamiento de datos en los buckets de Amazon S3. Hay tres componentes principales de un objeto: el contenido del objeto (datos almacenados en el objeto, como un archivo o directorio), el identificador único del objeto (ID) y los metadatos. Los metadatos se almacenan como valores de pares de claves y contienen información como nombre, tamaño, fecha, atributos de seguridad, tipo de contenido y URL.
Cada objeto tiene una lista de control de acceso (ACL) para configurar quién puede acceder al objeto. El almacenamiento de objetos de Amazon S3 le permite evitar los cuellos de botella en la red durante las horas punta, cuando el tráfico a sus objetos almacenados en la nube S3 aumenta significativamente. Amazon proporciona un ancho de banda de red flexible, pero cobra por el acceso de red a los objetos almacenados. El almacenamiento de objetos es bueno cuando un gran número de clientes debe acceder a los datos (alta frecuencia de lectura). La búsqueda a través de metadatos es más rápida en el modelo de almacenamiento de objetos.
Lea también sobre Cifrado de Amazon S3 que puede ayudarle a proteger los datos almacenados en la nube de Amazon S3 y mejorar la seguridad.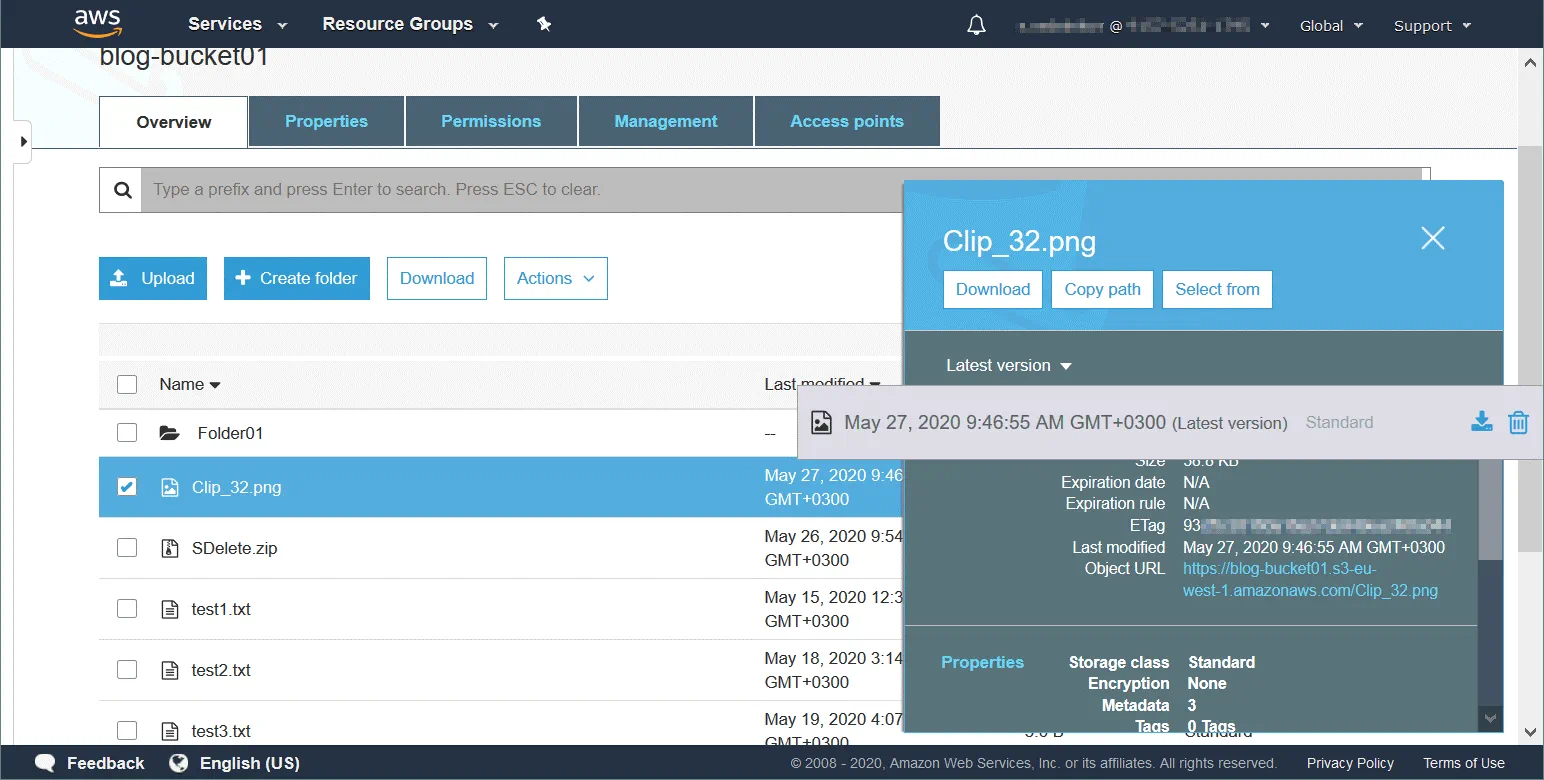
Cubos
Un bucket es un contenedor lógico fundamental donde se almacenan los datos en el almacenamiento de Amazon S3. En un cubo se puede almacenar una cantidad infinita de datos y un número ilimitado de objetos. Cada objeto S3 se almacena en un bucket. Existe una limitación de 5 TB para el tamaño de un objeto almacenado en un cubo. Los buckets se utilizan para organizar el espacio de nombres al más alto nivel y se utilizan para el control de acceso.
Claves
Un objeto tiene una clave única después de haber sido cargado en un bucket. Esta clave es una cadena que imita una jerarquía de directorios. Conocer la clave permite acceder al objeto en el cubo. Un cubo, una clave y un ID de versión identifican un objeto de forma única. Por ejemplo, si el nombre de un bucket es blog-bucket01, la región donde los centros de datos almacenan sus datos es s3-eu-west-1 y el nombre del objeto es test1.txt (un archivo de texto), la URL del archivo necesario almacenado como objeto en el bucket es:
https://blog-bucket01.s3-eu-west-1.amazonaws.com/test1.txt
Los permisos deben configurarse editando los atributos de los objetos si desea compartir objetos con otros usuarios. Del mismo modo, puede crear una carpeta TextFiles y almacenar el archivo de texto en esa carpeta:
https://blog-bucket01.s3-eu-west-1.amazonaws.com/TextFiles/test1.txt
Hay dos tipos de URL que se pueden utilizar:
- bucketname.s3.amazonaws.com/objectname
- s3.amazon.aws.com/bucketname/nombre_objeto
Regiones de AWS
Amazon tiene centros de datos en distintas regiones del mundo, como Estados Unidos, Irlanda, Sudáfrica, India, Japón, China, Corea, Canadá, Alemania, Italia y Gran Bretaña. Puede seleccionar la región que desee al crear un cubo. Se recomienda seleccionar la región más cercana a usted o a sus clientes para que la latencia de la conexión a la red sea menor o para minimizar los costes (porque el precio del almacenamiento de datos es diferente según la región). Los datos almacenados en una determinada región de AWS nunca abandonan los centros de datos de esa región hasta que usted migra los datos manualmente. Las regiones de AWS están aisladas entre sí para proporcionar tolerancia a fallos y estabilidad.
Cada región contiene zonas de disponibilidad que son ubicaciones aisladas dentro de una región de AWS. Cada región dispone de al menos tres Zonas de Disponibilidad para evitar fallos causados por catástrofes como incendios, tifones, huracanes, inundaciones, etc.
El modelo de coherencia de datos
La comprobación de coherencia de lectura tras escritura se realiza para los objetos almacenados en el almacenamiento de Amazon S3. Amazon S3 replica los datos entre servidores y centros de datos de una región seleccionada para lograr una alta disponibilidad. Tras una solicitud PUT correcta, los datos modificados deben replicarse en los servidores. Este proceso puede llevar algún tiempo. En este caso, un usuario puede obtener los datos antiguos o actualizados, pero no los corruptos. Lo mismo ocurre con los objetos y cubos eliminados. El bloqueo de objetos no se realiza cuando se envían objetos nuevos a los buckets de S3. La última solicitud PUT gana si se realizan varias solicitudes PUT simultáneamente. Puede crear su propia aplicación con un mecanismo de bloqueo que funcione con objetos almacenados en el almacenamiento de Amazon S3.
Funciones de Amazon S3
El concepto de almacenamiento basado en objetos permite a Amazon proporcionar funciones útiles y una gran flexibilidad para almacenar datos en el almacenamiento y la administración de Amazon S3. Repasemos estas funciones.
Control de versiones
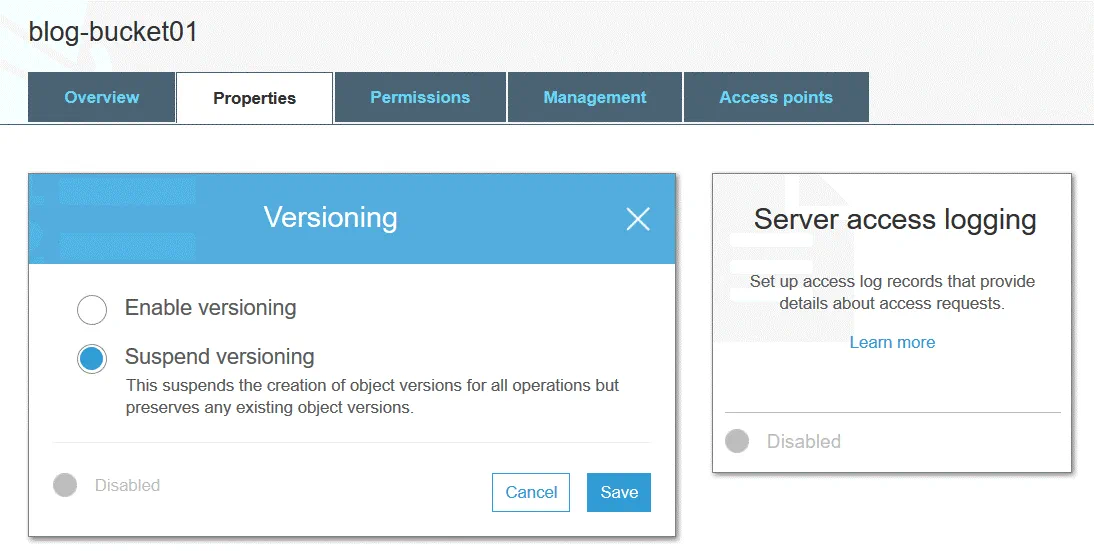
El control de versiones de objetos permite almacenar varias versiones de un objeto en un mismo cubo. Esta función puede proteger los objetos almacenados en Amazon S3 frente a ediciones, sobrescrituras o eliminaciones no deseadas. Después de modificar o eliminar un objeto, puede restaurar una de las versiones anteriores de ese objeto. El control de versiones se implementa gracias al uso del enfoque de almacenamiento de objetos. Puede utilizar el control de versiones con fines de archivo. El control de versiones está desactivado por defecto.
Se asigna un ID de versión a cada objeto S3 incluso si el control de versiones no está habilitado (en este caso el valor del ID de versión se establece en null). Si el control de versiones está activado, se asigna un nuevo valor de ID de versión a una nueva versión del objeto después de escribir los cambios. El control de versiones puede activarse a nivel de cubo. El valor del ID de versión de la primera versión del objeto sigue siendo el mismo. Al eliminar un objeto de un bucket de S3 (con el control de versiones activado), el marcador de eliminación se aplica a la última versión del objeto.
Clases de almacenamiento
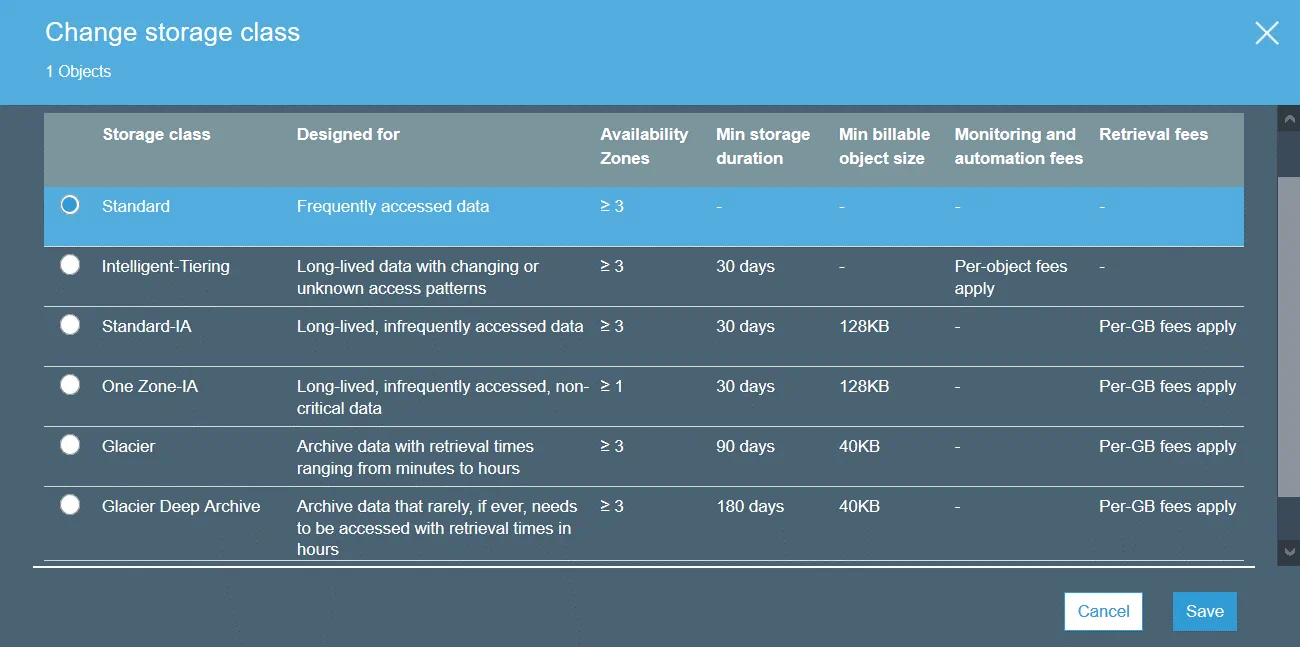
Las clases de almacenamiento de Amazon S3 definen la finalidad del almacenamiento seleccionado para guardar datos. Se puede establecer una clase de almacenamiento a nivel de objeto. Sin embargo, puede establecer la clase de almacenamiento predeterminada para los objetos que se crearán a nivel de cubo.
S3 Estándar es la clase de almacenamiento por defecto. Esta clase es de almacenamiento de datos en caliente y es buena para datos de uso frecuente. Utilice la clase de almacenamiento estándar para alojar sitios web, distribuir contenidos, desarrollar aplicaciones en la nube, etc. Los altos costes de almacenamiento, los bajos costes de restauración y el acceso rápido a los datos son las funciones de esta clase de almacenamiento.
S3 Standard-IA (acceso infrecuente) puede utilizarse para almacenar datos a los que se accede con menos frecuencia que en S3 Standard. S3 Standard-IA está optimizado para un periodo de almacenamiento más largo. La recuperación de datos almacenados en la clase de almacenamiento S3 Standard-IA tiene un coste. Además, tanto en S3 Estándar como en S3 Estándar-IA hay que pagar por las solicitudes de datos (PUT, COPY, POST, LIST, GET, SELECT).
S3 One Zone-IA está diseñado para datos a los que se accede con poca frecuencia. Los datos sólo se almacenan en una zona de disponibilidad (en el caso de S3 Standard, los datos se almacenan en tres zonas de disponibilidad), por lo que el nivel de redundancia y resiliencia es menor. El nivel de disponibilidad declarado es del 99,5%, inferior al de las otras dos clases de almacenamiento. S3 One Zone-IA tiene menores costes de almacenamiento, mayores costes de restauración y hay que pagar por la recuperación de datos por GB. Puede considerar el uso de esta clase de almacenamiento como rentable para almacenar copias de backup o copias de datos realizadas con la replicación entre regiones de Amazon S3.
S3 Glacier no ofrece acceso instantáneo a los datos almacenados, a diferencia de las otras clases de almacenamiento. S3 Glacier puede utilizarse para almacenar datos para archivarlos a largo plazo a bajo coste. No se garantiza el funcionamiento ininterrumpido. Hay que esperar desde unos minutos hasta unas horas para recuperar los datos. Puede transferir datos antiguos de un almacenamiento de una clase superior (por ejemplo, de S3 Standard) a S3 Glacier utilizando las políticas de ciclo de vida de S3 y reducir los costes de almacenamiento.
S3 Glacier Deep Archive es similar a S3 Glacier, pero el tiempo necesario para recuperar los datos es de entre 12 y 48 horas. El precio es inferior al del S3 Glacier. La clase de almacenamiento S3 Glacier Deep Archive puede utilizarse para almacenar backups y datos de archivo de empresas que siguen requisitos normativos para el archivo de datos (financieros, sanitarios). Es una buena alternativa a los cartuchos de cinta.
S3 Intelligent-Tiering es una clase de almacenamiento especial que utiliza otras clases de almacenamiento. S3 Intelligent-Tiering está pensado para seleccionar automáticamente una clase de almacenamiento mejor para almacenar datos cuando no se sabe con qué frecuencia se necesitará acceder a estos datos. Amazon S3 puede supervisar los patrones de acceso a los datos cuando se utiliza S3 Intelligent-Tiering y, a continuación, almacenar los objetos en una de las dos clases de almacenamiento seleccionadas (una que es para los datos a los que se obtiene acceso con frecuencia y otra para los datos a los que se obtiene acceso con poca frecuencia). Este enfoque le ofrece una rentabilidad óptima sin comprometer el rendimiento.
Por ejemplo, si accede a un objeto almacenado en una clase de almacenamiento para datos a los que se accede con poca frecuencia, este objeto se traslada automáticamente a una clase de almacenamiento para datos a los que se accede con frecuencia. De lo contrario, si no se ha accedido a un objeto durante mucho tiempo, el objeto se traslada a la clase de almacenamiento para datos de uso poco frecuente. Los objetos pueden estar ubicados en el mismo bucket y la clase de almacenamiento se cambia a nivel de objeto S3.
Listas de control de acceso
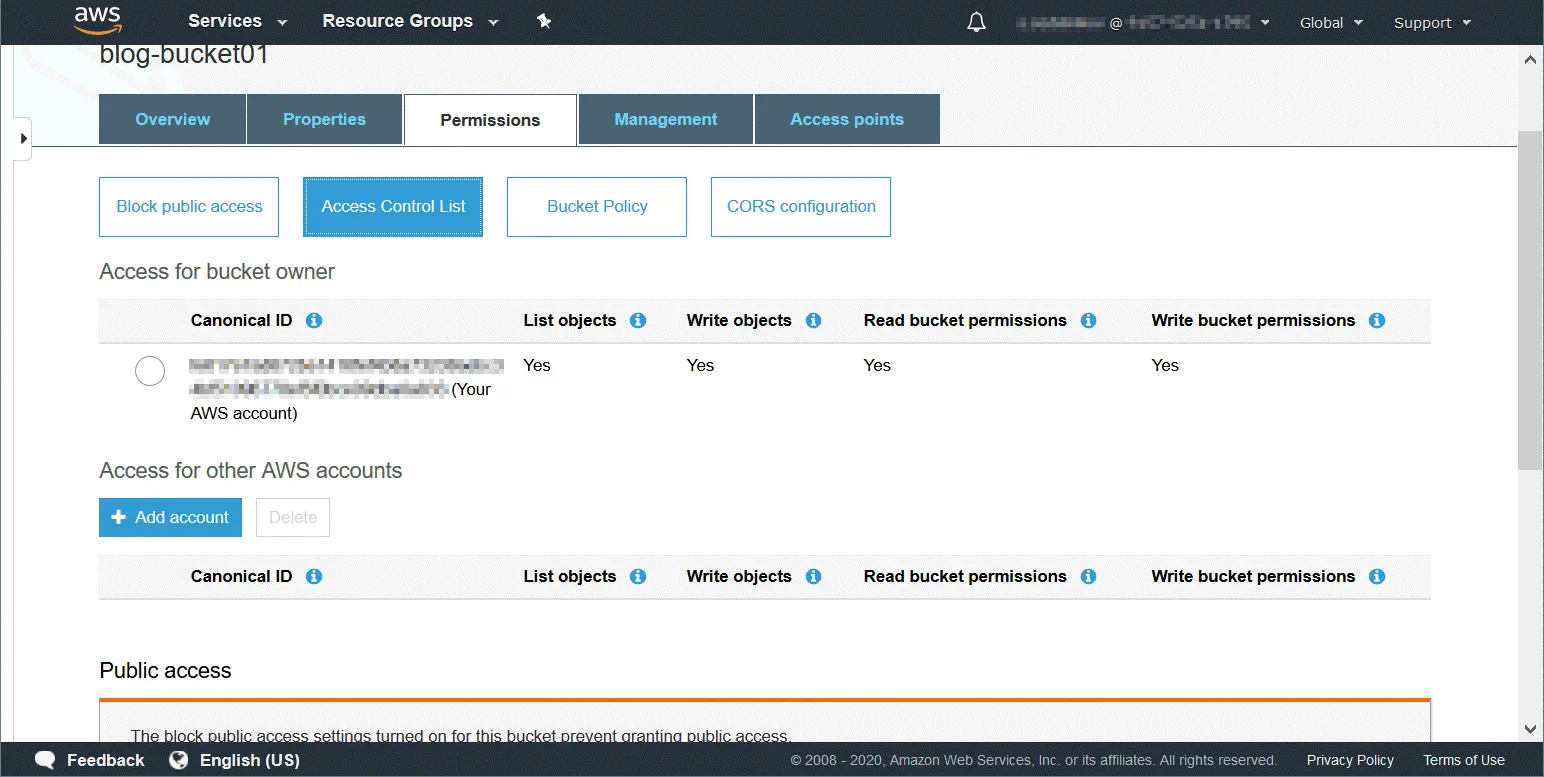
Una lista de control de acceso (ACL) es una función utilizada para gestionar y controlar el acceso a objetos y buckets. Las listas de control de acceso son políticas basadas en recursos que se adjuntan a cada cubo y objeto para definir los usuarios y grupos que tienen permisos para acceder al cubo y al objeto. Por defecto, el propietario del recurso tiene acceso total a un cubo u objeto después de crear el recurso. Los permisos de acceso al bucket definen quién puede acceder a los objetos del bucket. Los permisos de acceso a objetos definen los usuarios que pueden acceder a los objetos y el tipo de acceso. Puede establecer permisos de sólo lectura para un usuario y permisos de lectura y escritura para otro, por ejemplo.
La lista completa de usuarios que pueden tener permisos (un usuario que tiene permisos se denomina cesionario):
Propietario: usuario que crea un cubo/objeto.
Usuarios autenticados – cualquier usuario que tenga una cuenta de AWS.
Todos los usuarios – cualquier usuario, incluidos los usuarios anónimos (usuarios que no tienen una cuenta de AWS).
Usuario por correo electrónico/Id – un usuario especificado que tiene una cuenta de AWS. Se debe especificar el correo electrónico o el ID de AWS de un usuario para concederle acceso.
Tipos de permisos disponibles:
Control total: este tipo de permiso proporciona permisos de Lectura, Escritura, Lectura (ACP) y Escritura ACP.
Leer – permite listar el contenido del cubo cuando se aplica a nivel de cubo. Permite leer los datos y metadatos del objeto cuando se aplica a nivel de objeto.
Escritura: sólo puede aplicarse a nivel de cubo y permite crear, eliminar y sobrescribir cualquier objeto del cubo.
Permisos de lectura (READ ACP): un usuario puede obtener permisos de lectura para el objeto o cubo especificado.
Permisos de escritura (ESCRIBIR ACP): un usuario puede sobrescribir los permisos del objeto o cubo especificado. Habilitar este tipo de permiso para un usuario equivale a establecer permisos de Control Total, ya que el usuario puede establecer cualquier permiso para su cuenta. Este permiso está disponible por defecto para el propietario del cubo.
Políticas de cubos
Las políticas de bucket son políticas de administración de acceso e identidades de AWS basadas en recursos que se utilizan para crear reglas condicionales para conceder permisos de acceso a cuentas y usuarios de AWS cuando acceden a buckets y objetos en buckets. Puede utilizar políticas de bucket para definir reglas de seguridad para más de un objeto en un bucket.
La política del cubo se define como un archivo JSON. El texto de configuración de la política de cubos debe cumplir los requisitos del formato JSON para ser válido. La política de cubos sólo puede aplicarse a nivel de cubo y se hereda a todos los objetos del cubo. Puede conceder acceso a usuarios que se conecten desde direcciones IP específicas, usuarios de cuentas de AWS específicas, etc.
A continuación puede ver el ejemplo de una política que concede acceso total a todos los usuarios de una cuenta y acceso de sólo lectura a todos los usuarios de otra cuenta.
{
"Statement": [
{
"Effect": "Allow",
"Principal": {
"SGWS": "95381782731015222837"
},
"Action": "s3:*",
"Resource": [
"urn:sgws:s3:::blog-bucket01",
"urn:sgws:s3:::blog-bucket01/*"
]
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:GetObject",
"Resource": "urn:sgws:s3:::blog-bucket01/shared/*"
},
{
"Effect": "Allow",
"Principal": {
"SGWS": "30284200178239526177"
},
"Action": "s3:ListBucket",
"Resource": "urn:sgws:s3:::blog-bucket01",
"Condition": {
"StringLike": {
"s3:prefix": "shared/*"
}
}
}
]
}
Los usuarios pueden acceder al almacenamiento de Amazon S3 utilizando claves de acceso (ID de clave de acceso y clave de acceso secreta) sin necesidad de introducir el nombre de usuario y la contraseña. Este enfoque permite mejorar la seguridad y se utiliza para crear aplicaciones que utilizan API para acceder al almacenamiento en la nube Amazon S3.
API para Amazon S3
Amazon proporciona interfaces de programación de aplicaciones (API) para acceder a las funciones de S3 y desarrollar aplicaciones propias que deban trabajar con el almacenamiento de Amazon S3. Amazon proporciona interfaces REST y SOAP. La interfaz REST utiliza peticiones HTTP estándar para trabajar con cubos y objetos. La API REST utiliza cabeceras HTTP estándar. La interfaz SOAP es otra interfaz disponible. El uso de SOAP sobre HTTP está obsoleto, pero aún puede utilizar SOAP sobre HTTPS.
El modelo de pago
Amazon S3 ofrecía el modelo «paga solo por lo que usas». No se exige una cuota mínima: no es necesario pagar por una cantidad predeterminada de almacenamiento y tráfico de red. Existen categorías de uso por las que debes pagar:
Almacenamiento. Pago de objetos almacenados en Amazon S3. La cantidad de dinero que tiene que pagar depende del espacio de almacenamiento utilizado, el tiempo de almacenamiento de objetos en el almacenamiento de Amazon S3 (durante el mes) y la clase de almacenamiento utilizada por los objetos almacenados.
Solicitudes y recuperación de datos. Debe pagar por las solicitudes realizadas para recuperar datos almacenados en la nube Amazon S3.
Transferencia de datos. Debe pagar por todo el ancho de banda utilizado (tráfico entrante y saliente), excepto los datos entrantes de Internet; los datos salientes que se transfieren a instancias de Amazon EC2 que se encuentran en la misma región de AWS que el bucket de S3 de origen; los datos salientes de un bucket de S3 a CloudFront.
Gestión y replicación. Debe pagar por utilizar funciones de gestión del almacenamiento como el análisis y el etiquetado de objetos. Amazon cobra por la replicación entre regiones y por la replicación en la misma región.
Utiliza la calculadora de Amazon S3 para estimar tus pagos.



