
Recuperación ante desastres con NAKIVO: planificación, implementación y pruebas
El backup y la recuperación ante desastres son las bases de las estrategias de protección de datos en todas las organizaciones e industrias. La recuperación ante desastres es el proceso de recuperación de máquinas virtuales y los servicios que se ejecutan en ellas en un sitio secundario (conocido como sitio de recuperación ante desastres) cuando el sitio de producción deja de estar disponible. Estos emplazamientos secundarios de RD, que albergan servidores, ordenadores y equipos de red redundantes con el software necesario, pueden ser de distintos tipos en función del nivel de redundancia.
NAKIVO Backup & Replication incluye la función Site Recovery que permite crear secuencias de recuperación avanzadas (con failover completo del sitio) que pueden iniciarse con un solo clic cuando el sitio principal se cae. Lea esta entrada del blog para conocer los componentes clave de la estrategia de recuperación ante desastres, como la planificación de la recuperación ante desastres de TI, las pruebas y la realización de la recuperación ante desastres con la solución integrada de NAKIVO.

Primer paso. Planificación de la recuperación ante desastres
Como paso esencial para una recuperación ante desastres eficaz, la planificación debe incluir una evaluación de las necesidades de recuperación de la organización y el desarrollo de una comprensión global de qué componentes, pasos y procedimientos deben incluirse en un flujo de trabajo de recuperación ante desastres.
Planificación de la recuperación ante desastres: prácticas recomendadas
1. Realizar un análisis del impacto en la empresa
Un análisis del impacto en la empresa (o BIA, por sus siglas en inglés) se utiliza para determinar el posible impacto negativo de incidentes graves o catástrofes naturales en las operaciones de la empresa. Este análisis implica asignar un orden de prioridad a las distintas máquinas virtuales, la secuencia de recuperación y el tiempo disponible antes de que una interrupción afecte significativamente a las operaciones de la empresa. Por ejemplo, el fallo de una máquina virtual puede causar retrasos e inconvenientes, mientras que el fallo de otra máquina virtual puede provocar la interrupción total de las operaciones críticas para la empresa.
2. Evaluar los riesgos
Antes de planificar la RD, recopile los datos pertinentes sobre los riesgos para las operaciones de su organización y la continuidad de la actividad. En algunas zonas, un apagón prolongado o un ataque de virus son más probables que un tornado, pero en otras las catástrofes naturales son habituales. Una evaluación de riesgos le ayuda a determinar el nivel adecuado de protección frente a determinadas amenazas y a idear medidas para minimizar los riesgos y mitigar las consecuencias. Aunque los riesgos no pueden eliminarse por completo, estará mejor preparado para las situaciones de catástrofe a las que probablemente se enfrente.
3. Desarrollar la documentación de recuperación ante desastres
Una vez identificados los riesgos y su posible impacto en su empresa, comprenderá mejor dónde debe centrar sus esfuerzos para planificar los procesos de recuperación ante desastres. Documente los procedimientos de recuperación, describiendo detalladamente todos los pasos vitales y las medidas de RD, y actualice los documentos periódicamente para reflejar los cambios realizados en el entorno. La documentación debe incluir:
- Alcance de la recuperación ante desastres. Evalúe la importancia de cada componente de hardware y software de su infraestructura e incluya en su plan de recuperación ante desastres los destinados a operaciones de misión crítica. Las máquinas virtuales que albergan información crítica, sistemas informáticos y aplicaciones cuyo funcionamiento es esencial para garantizar la prestación continua de servicios deben ser su máxima prioridad para la recuperación.
- Orden de recuperación de MV. Determinadas máquinas virtuales pueden depender del software o la información alojados en otra máquina virtual, lo que significa que no pueden funcionar por separado ni iniciarse aleatoriamente. Debe especificar el orden de recuperación para agilizar la recuperación y eliminar el riesgo de conflictos de software en el sitio de DR. Por ejemplo, la máquina virtual que ejecuta el controlador de dominio de Active Directory debe estar en funcionamiento antes de poder iniciar una máquina virtual con un servidor de archivos que utilice la autenticación de Active Directory.
Otro ejemplo son los servicios web, que a menudo dependen de software instalado en varias máquinas virtuales diferentes. Podría ser necesario aplicar la siguiente secuencia:
- La máquina virtual con el servidor de base de datos debe iniciarse en primer lugar.
- A continuación, puede iniciarse la máquina virtual con el servidor de aplicaciones.
- Sólo entonces podrá iniciarse la máquina virtual con el servidor web.
- RTO y RPO en la recuperación ante desastres. Establezca el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO) para las distintas máquinas virtuales prioritarias en el plan de recuperación ante desastres. Por ejemplo, las máquinas virtuales con sistemas financieros podrían tener objetivos de recuperación más cortos que las utilizadas para almacenar documentos archivados.
- Dependencias. A la hora de determinar la cadena de dependencias entre el personal y los componentes informáticos, colabore con su personal y téngalo en cuenta para evitar eslabones débiles que puedan llevar al fracaso de la recuperación. Por ejemplo, puede ser necesario recuperar primero una máquina virtual utilizada por el departamento de contabilidad si los trabajadores de otros departamentos dependen de esas operaciones financieras para realizar su trabajo.
- Personal. Asigne funciones y responsabilidades a los miembros del equipo que forman parte de los procesos de RD. Si van a trabajar en el emplazamiento de la RD, asegúrese de que haya allí estaciones de trabajo con todos los equipos, mobiliario de oficina y hardware necesarios, para que puedan continuar su trabajo con las mínimas interrupciones. Si los empleados pueden trabajar a distancia durante una catástrofe, configure el acceso VPN y proporcione cuentas VPN con antelación.
- Requisitos de hardware. El éxito de un plan de recuperación ante desastres depende en gran medida del rendimiento y las capacidades del hardware ubicado en el emplazamiento de RD. Hay que tener en cuenta varios factores:
- Los servidores deben tener suficiente CPU, memoria y capacidad de disco para soportar las cargas de trabajo transferidas. Un rendimiento bajo de la CPU y una memoria insuficiente pueden afectar a la velocidad de sus máquinas virtuales, mientras que una velocidad insuficiente del disco provoca un rendimiento deficiente de las máquinas virtuales.
- Las redes deben proporcionar suficiente ancho de banda para que las máquinas virtuales recuperadas interactúen entre sí, con el almacenamiento compartido y con los usuarios, según sea necesario.
Segundo paso. Preparación para la recuperación ante desastres
Una vez que tenga la documentación, puede proceder a preparar la recuperación ante desastres preparando el sitio de recuperación ante desastres y configurando la replicación de las cargas de trabajo críticas en ese sitio. La replicación es necesaria para la conmutación por recuperación de máquinas virtuales a máquinas virtuales de réplica cuando la infraestructura principal se cae.
¿Qué es la replicación de máquinas virtuales?
La replicación de máquinas virtuales es el proceso de crear una copia idéntica de una máquina virtual de origen (denominada «réplica de máquina virtual») en un host diferente (el host de destino). La réplica de la máquina virtual es una máquina virtual normal que permanece apagada hasta que se necesita (momento en el que puede ponerse en marcha en su host casi al instante).
Compruebe cómo crear y configurar un job de replicación VMware en NAKIVO Backup & Replication para más detalles.
El proceso de conmutación de cargas de trabajo de una VM de origen (producción) a una réplica de VM en el sitio de DR con el fin de mantener la continuidad del negocio y la alta disponibilidad se conoce como conmutación por recuperación.
Prácticas recomendadas de replicación de máquinas virtuales
Existen diversas prácticas recomendadas de replicación para garantizar una mayor fiabilidad y eficacia del proceso. Aquí nos centraremos en dos puntos clave:
- Realice la replicación de máquinas virtuales en el a nivel de host en lugar de a nivel de invitado. La capa de virtualización es la capa intermedia entre el hardware físico y el sistema operativo invitado que se ejecuta en una máquina virtual. La replicación realizada a nivel de virtualización se denomina a nivel de host y es más eficiente que la replicación a nivel de invitado.
- Utilice la replicación coherente con las aplicaciones para evitar la pérdida de datos. Si se toma una instantánea de la máquina virtual necesaria para la replicación mientras estas aplicaciones se están ejecutando sin ninguna acción adicional, entonces el efecto sería similar a la pérdida inesperada de energía y el apagado y los datos se pueden perder.
Con los métodos coherentes con las aplicaciones, las aplicaciones se congelan (quiesced) y la memoria se vacía, y los datos no pueden escribirse en el disco antes de que se tome una instantánea. Una vez tomada la instantánea coherente, se puede crear una réplica de la máquina virtual. Estas réplicas de máquinas virtuales pueden restaurarse correctamente con las aplicaciones que contienen.
NAKIVO Backup & Replication admite la replicación a nivel de host compatible con las aplicaciones para VMware VMs, Hyper-V VMs e instancias EC2 con funciones especiales para Microsoft SQL Server, Exchange Server y Active Directory Domain Controller.
Tercer paso. Creación de un flujo de trabajo de recuperación ante desastres
Para crear un flujo de trabajo de recuperación ante desastres, necesita una solución de recuperación ante desastres especializada como NAKIVO Backup & Replication, que proporciona una función Site Recovery integrada para orquestar y automatizar las secuencias de recuperación ante desastres.
- ¿Qué es un flujo de trabajo de recuperación ante desastres?
- Acciones disponibles para un flujo de trabajo de RD
- Cómo crear un flujo de trabajo de recuperación ante desastres
- Guía de configuración de la función Site Recovery de NAKIVO
¿Qué es un flujo de trabajo de recuperación ante desastres?
Un flujo de trabajo de recuperación ante desastres es una secuencia de acciones ejecutadas como parte del proceso de recuperación ante desastres para la conmutación por error segura y rápida de las cargas de trabajo a las réplicas. El flujo de trabajo organiza el proceso de conmutación por recuperación con acciones relacionadas con las máquinas virtuales de origen, las máquinas virtuales de destino, las condiciones que deben cumplirse, etc. Debe definir en qué orden deben ejecutarse las acciones, ya que algunos procedimientos de recuperación ante desastres pueden depender del resultado de la ejecución de otros.
Acciones disponibles de la función Site Recovery
La función Site Recovery permite crear secuencias de recuperación de desastres complejas combinando acciones y condiciones en un único flujo de trabajo. Cada acción puede ejecutarse sólo en modo de prueba, sólo en modo de producción o en ambos modos (éste es el utilizado por defecto) en NAKIVO Backup & Replication.
Puede incluir cualquiera o todas las acciones siguientes en una secuencia:
- Conmutación por recuperación: inicia la conmutación por recuperación a réplicas de máquinas virtuales VMware, Hyper-V o instancias EC2.
- Conmutación por error: devuelve las cargas de trabajo de la réplica de la máquina virtual a la máquina virtual de origen. Los cambios realizados en la réplica de la VM desde el punto de conmutación por error se escriben en la VM de origen cuando se realiza la operación de conmutación por error. Las máquinas virtuales se sincronizan y la máquina virtual de origen vuelve a estar en el estado de producción real.
- Iniciar: inicia máquinas virtuales VMware, Hyper-V o instancias EC2.
- Detener – detiene VMs VMware, Hyper-V VMs, instancias EC2 que se están ejecutando.
- Run job – ejecuta un job de backup, replicación, recuperación del entorno, copia de backup o Flash VM Boot.
- Detener jobs – detiene un job (cualquiera de los jobs listados en el punto anterior).
- Ejecutar script: ejecuta un script en uno de los siguientes destinos: el servidor con el Director, un Servidor Windows Remoto, un Servidor Linux Remoto, una VMware VM, una VM Hyper-V o una instancia EC2.
- Adjuntar repositorio: adjunta un repositorio de backups utilizado por NAKIVO Backup & Replication para almacenar backups.
- Separar repositorio – separa un repositorio de backups.
- Enviar correo electrónico: envía un correo electrónico con el mensaje que redacte a uno o varios destinatarios definidos.
- Esperar – espera el periodo de tiempo designado antes de proceder a la siguiente acción.
- Comprobar condición: en función de lo que introduzca (todo o parte de un nombre de recurso), comprueba una de las siguientes condiciones:
- El recurso existe
- El recurso está en funcionamiento
- IP/Nombre de host accesible
Cómo crear un flujo de trabajo de restauración del entorno
Veamos un ejemplo de cómo crear un job de restauración del entorno en NAKIVO Backup & Replication.
Nuestra configuración
Esta es la configuración que vamos a considerar: un sitio primario (producción) con VMware vSphere VMs y un sitio DR en una ubicación remota:
- DC-VM es una máquina virtual basada en Windows que ejecuta Active Directory Domain Controller.
- FS-VM es una máquina virtual basada en Windows con un servidor de archivos en ejecución (el protocolo SMB se utiliza para compartir archivos). Active Directory se utiliza para la autenticación de usuarios. Los volcados de la base de datos Oracle se almacenan en el servidor de archivos.
- Ora-DB es la máquina virtual en la que se ejecuta la base de datos Oracle.
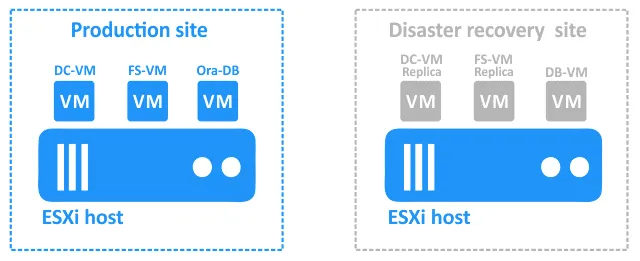
El sitio de recuperación ante desastres contiene las siguientes máquinas virtuales:
- DC-VM-replica y FS-VM-replica son réplicas de las máquinas virtuales de producción. Pueden utilizarse como objetivos para la conmutación por recuperación.
- DB-VM es una VM basada en Linux con el software Oracle Database instalado pero que no contiene bases de datos.
La copia de seguridad de la base de datos se realiza con NAKIVO Backup & Replication a nivel de base de datos en FS-VM en el sitio de producción (esta copia de seguridad de la base de datos Oracle es coherente con la aplicación). FS-VM y DC-VM se replican a nivel de host en el sitio DR con la solución NAKIVO.
Orden de recuperación de máquinas virtuales
Durante un incidente que provoque la caída del sitio de producción, los componentes deben recuperarse en el sitio de DR de la siguiente manera:
- Conmutación por recuperación de DC-VM a DC-VM-replica.
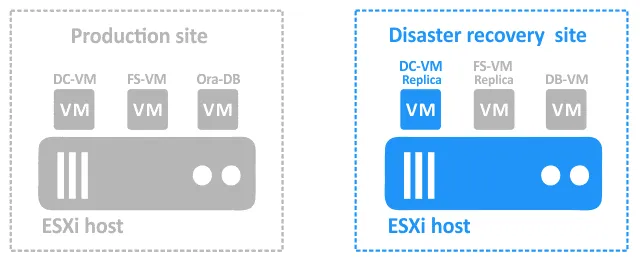
- Una vez que la réplica DC-VM está en funcionamiento, conmutación por recuperación de FS-VM a la réplica FS-VM. Debe operar en este orden porque FS-VM depende de DC-VM para la autenticación de usuarios en el servidor de archivos.
- Una vez que estas dos máquinas virtuales están funcionando, DB-VM puede acceder al directorio compartido en el servidor de archivos donde se almacena el volcado. Ahora se puede iniciar DB-VM.
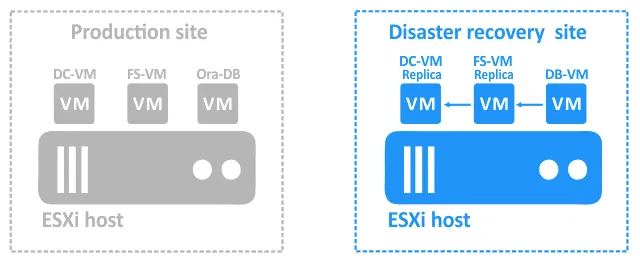
- Una vez que DB-VM se esté ejecutando, ejecute un script que pueda restaurar la base de datos a partir del volcado ubicado en el servidor de archivos. Las flechas azules de los diagramas anteriores muestran las dependencias.
Tenga en cuenta que puede ser necesario algún tiempo para que los servicios se inicien en una réplica de VM encendida después de la acción de conmutación por error y antes de conmutar a la siguiente réplica o recuperar una aplicación o una base de datos. Este tiempo de espera debe formar parte de la secuencia de DR.
Para este orden de conmutación por error de máquinas virtuales, es necesario crear un job de restauración del entorno en NAKIVO Backup & Replication con la siguiente lógica:
- Acción 1: Fail over DC-VM. Espere a que se complete esta acción antes de proceder al siguiente paso. Detenga el job si esta acción falla.
- Acción 2. Espere 3 minutos.
- Acción 3. Compruebe el estado de la réplica DC-VM. Comprueba si el recurso está en funcionamiento. Si el recurso está en ejecución, pase a la siguiente acción en el job de Site Recovery. Si no es así, detenga y suspenda el job.
- Acción 4. Fail over FS-VM. Espere a que finalice esta acción antes de pasar a la siguiente. Detenga el job si esta acción falla.
- Acción 5. Espere 3 minutos.
- Acción 6. Compruebe el estado de la réplica FS-VM. Si el recurso está en ejecución, pase a la siguiente acción de la función Site Recovery job. Si no es así, detenga y suspenda el job.
- Acción 7. Inicie DB-VM. Espere a que finalice esta acción antes de pasar a la siguiente. Detenga el job si esta acción falla.
- Acción 8. Espere 5 minutos.
- Acción 9. Ejecutar script. Tipo de objetivo: VMware VM. VM objetivo: DB-VM. Ruta del script: /home/oracle/restore_db.sh (al añadir este paso, debe introducir el nombre de usuario y la contraseña de una cuenta con permisos suficientes para ejecutar el script).
Recorrido de la función Site Recovery de NAKIVO
Vamos a crear una nueva función Site Recovery basada en el plan descrito anteriormente. En la página Jobs de su instancia de NAKIVO Backup & Replication, haga clic en Create > Site recovery job.
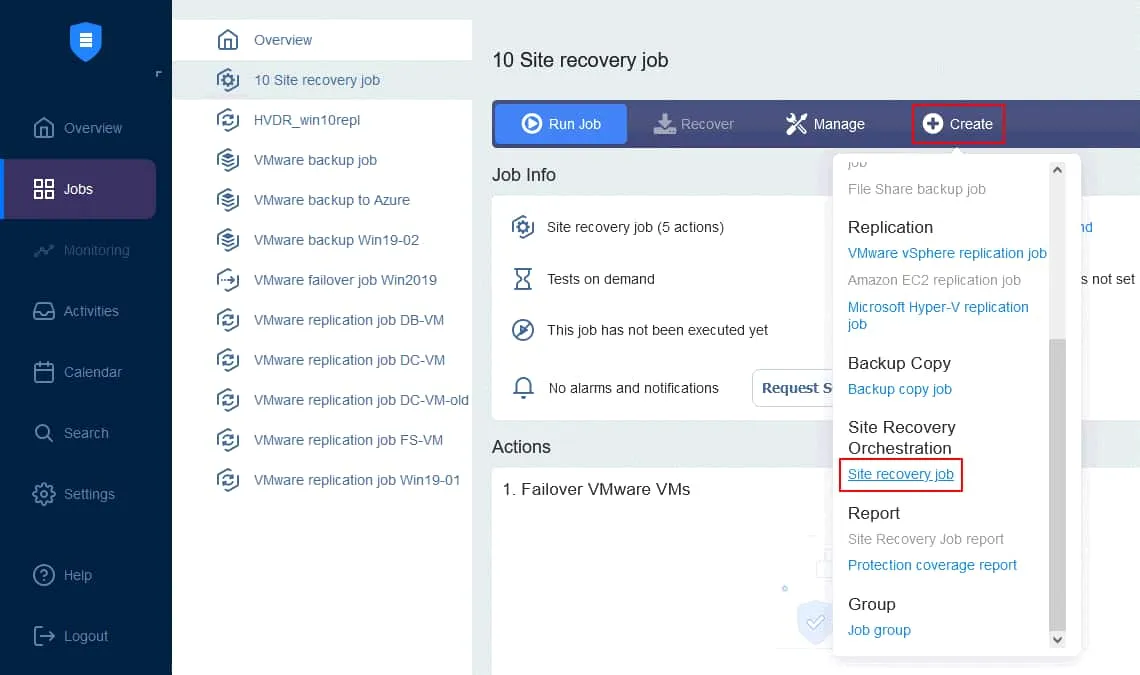
1. Acciones
Se inicia el Asistente para nueva función Site Recovery. En el panel izquierdo, encontrará las acciones que pueden añadirse al job. Basta con hacer clic en una acción para añadirla a la secuencia. Tenga en cuenta que no puede mezclar acciones para diferentes plataformas en una secuencia (estamos creando un job para VMware VMs).
Acción 1. Fail over DC-VM
- En el panel izquierdo, haga clic en Conmutación por recuperación VMware VMs.
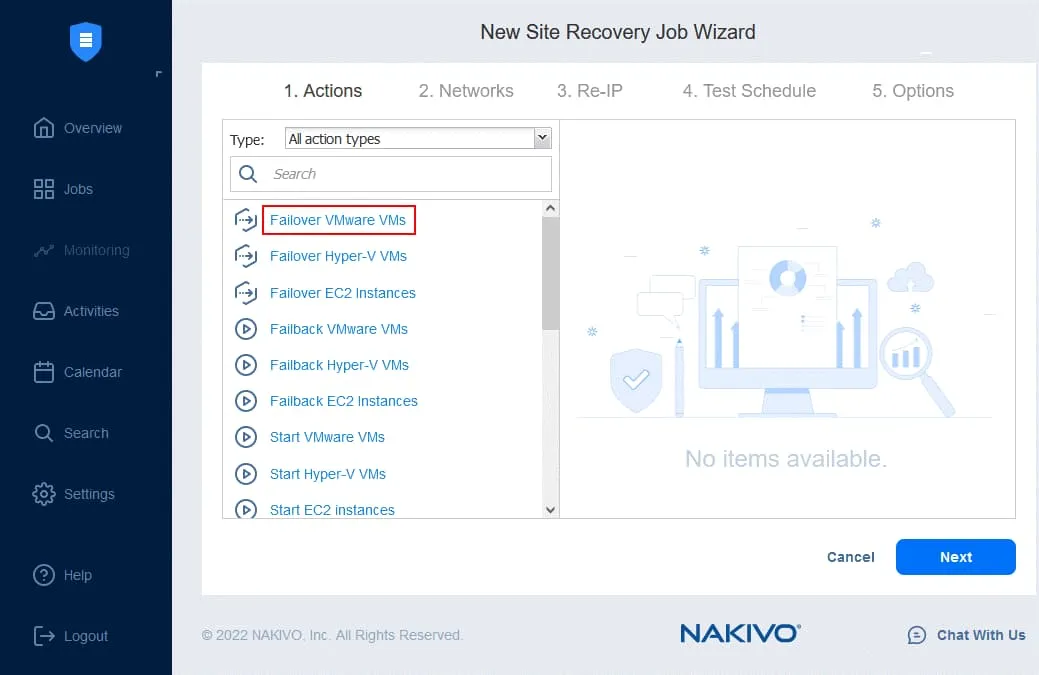
- En el panel izquierdo, seleccione la réplica VM de un job de replicación existente. En nuestro flujo de trabajo, la conmutación por recuperación a DC-VM-replica es la primera acción. En el panel derecho, puede seleccionar un punto de recuperación. Por defecto se utiliza el último punto de recuperación.
Haga clic en Siguiente para continuar.
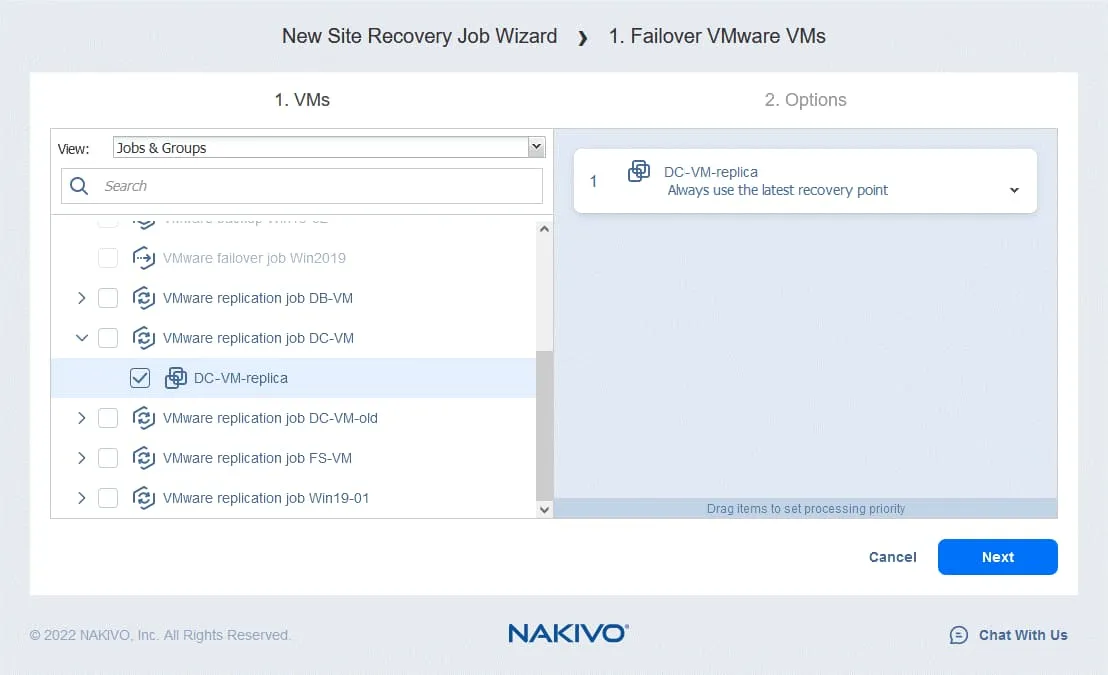
- Para las opciones de conmutación por recuperación ante desastres, puede anular la selección de Apagar las máquinas virtuales de origen: esta opción se puede utilizar para evitar un conflicto de direcciones IP si las máquinas virtuales de origen y las réplicas utilizan las mismas redes.
Basándonos en la lógica expuesta, seleccionamos las siguientes opciones:
- Ejecute esta acción en: Ejecuta esta acción tanto en modo de pruebas como en modo de producción
- Comportamiento de espera: Esperar a que se complete esta acción
- Tratamiento de errores: Detener y fallar el job si esta acción falla.
Haga clic en Guardar para guardar la acción creada.
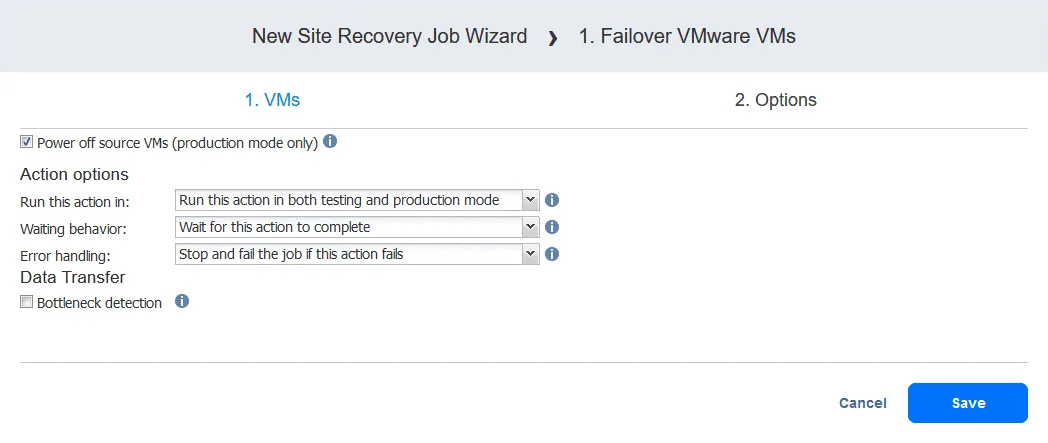
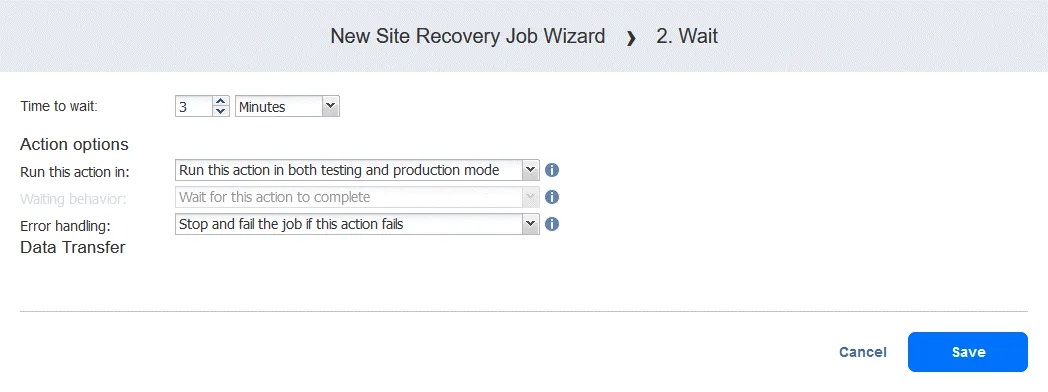
Acción 2. Espere 3 minutos
Una acción de espera es útil en este caso porque la siguiente acción de conmutación por recuperación en el flujo de trabajo (conmutación por error a la réplica de FS-VM) requeriría que la réplica de DC-VM estuviera en funcionamiento con los Servicios de dominio de Active Directory.
- En el panel izquierdo de la pantalla Acciones, haga clic en Esperar.
- Seleccione el tiempo de espera (nosotros utilizamos 3 minutos).
Seleccione las opciones de acción como lo ha hecho para la primera acción y haga clic en Guardar.
La nueva acción se añade después de la anterior, al final de la lista. Puede reordenar, editar o eliminar acciones. Basta con pasar el ratón por encima de una acción para ver las opciones.
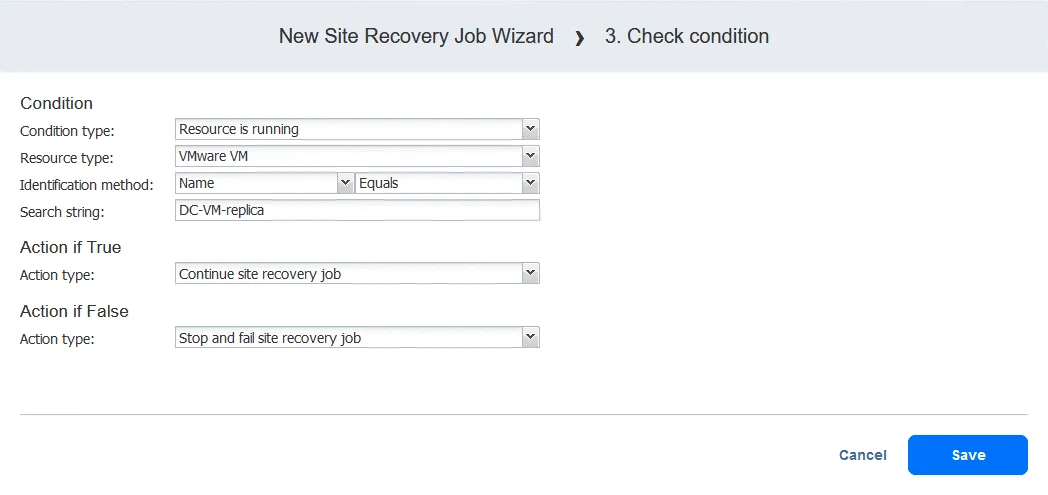
Acción 3. Comprobar el estado de la réplica DC-VM
- En el panel izquierdo de la pantalla Acciones, haga clic en Comprobar estado para comprobar si la máquina virtual sobre la que se produjo el error en la primera acción se está ejecutando.

- Configure esta acción del siguiente modo:
- Seleccione el tipo de condición: El recurso está en marcha. Las otras opciones son recurso existe o IP/nombre de host es alcanzable.
- Seleccione el tipo de recurso: VMware VM.
- Seleccione el método de identificación: Nombre (la otra opción es ID) para identificar la máquina virtual en cuestión. Puede utilizar cualquier parte de la cadena de la máquina virtual. En este caso, conocemos el nombre exacto, por lo que utilizamos la función Iguales.
- Defina la cadena de búsqueda: DC-VM-replica.
Ahora tenemos una acción que comprueba si la VMware VM llamada DC-VM-replica se está ejecutando. Haga clic en Guardar para continuar.
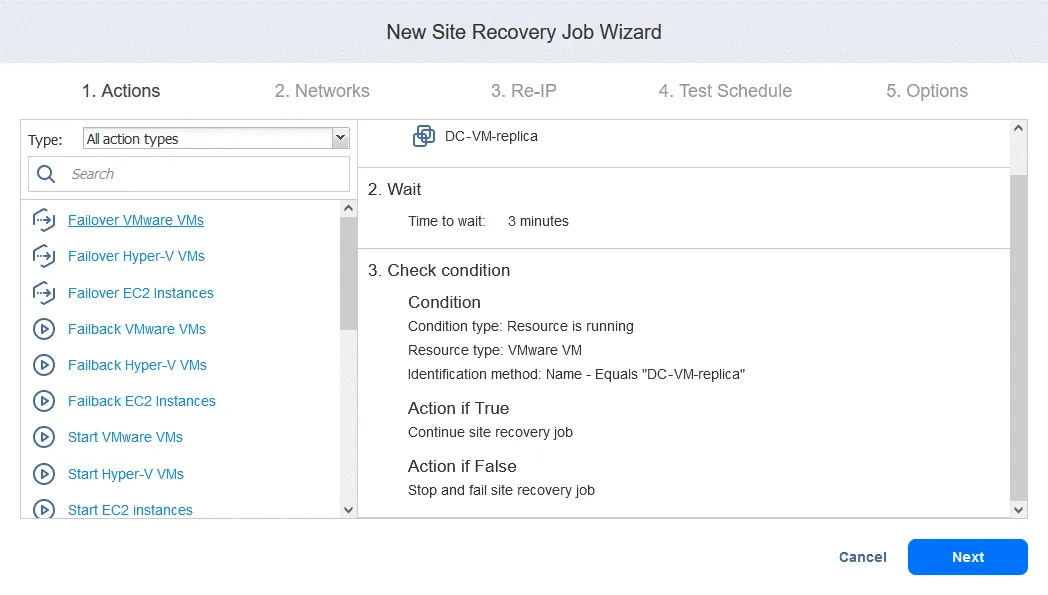
Acción 4. Conmutación por recuperación FS-VM
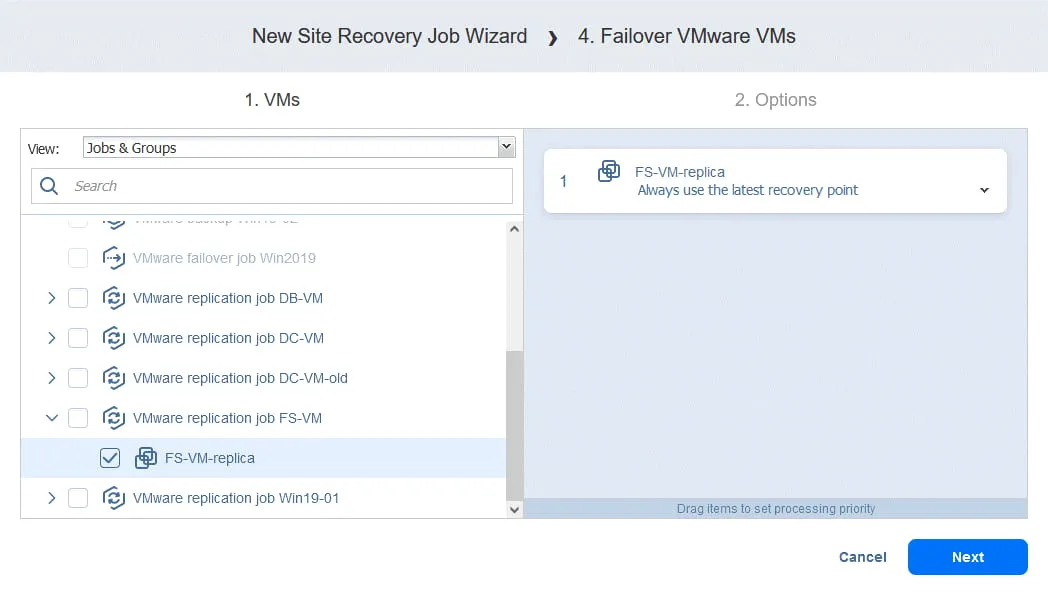
- Igual que en la Acción 1, haga clic en Conmutación por recuperación VMware VMs.
- En este caso seleccionamos FS-VM-replica. Haga clic en Siguiente, seleccione las mismas opciones para la acción de conmutación por recuperación que en la Acción 1 y haga clic en Guardar.
Acción 5. Espere 3 minutos
Haga clic en Esperar y configure esta acción como lo hizo para la acción 2. El tiempo especificado vuelve a ser de 3 minutos en nuestro caso.
Acción 6. Comprobar el estado de la réplica FS-VM
Haga clic en Comprobar estado para comprobar si la réplica VMware VM FS-VM se está ejecutando. Consulte la acción 2 y seleccione las mismas opciones, excepto, por supuesto, el nombre de la máquina virtual.
Acción 7. Iniciar DB-VM
- Haga clic en Iniciar VMware VMs en el panel izquierdo de la pantalla Acciones.
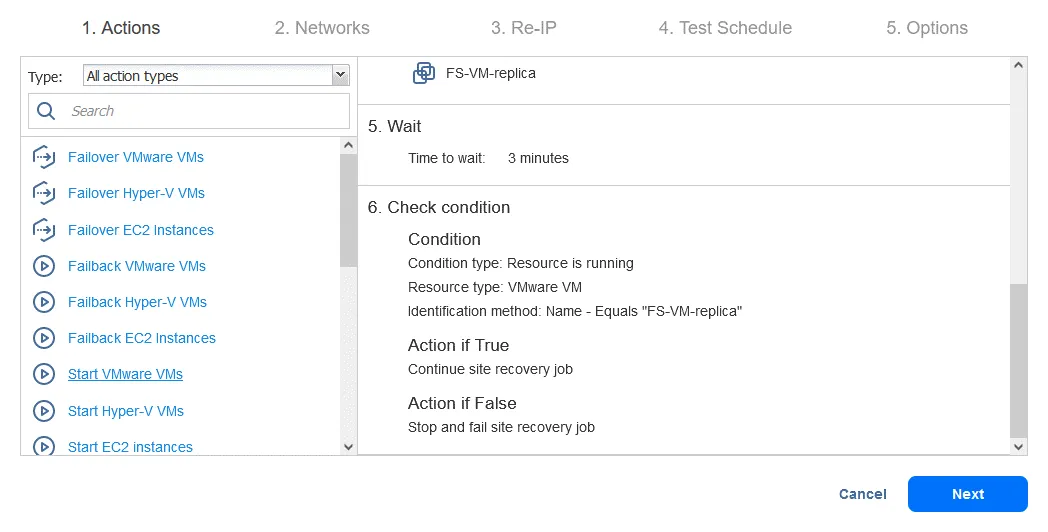
- Seleccione DB-VM. Esta VM se puede iniciar una vez que esté seguro de que la réplica FS-VM está funcionando. En la parte inferior de la página, seleccione las mismas opciones de acción que en las acciones anteriores. A continuación, haga clic en Guardar.
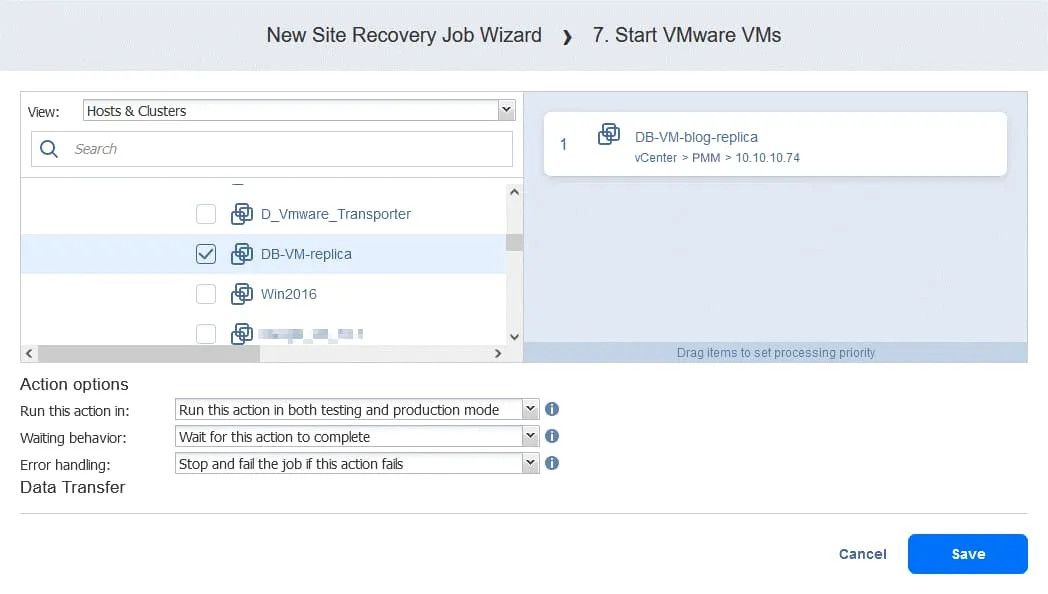
Acción 8. Espere 5 minutos
Espere 5 minutos. Haga clic en Esperar y configure esta acción de forma similar a la acción 2. Esto debería ser suficiente para iniciar el servicio Oracle en DB-VM.
Acción 9. Ejecutar script
- En la pantalla Acciones, haga clic en Ejecutar script. Recordemos que este script está destinado a recuperar la base de datos Oracle en el nivel de base de datos a partir de un volcado almacenado en FS-VM-replica.
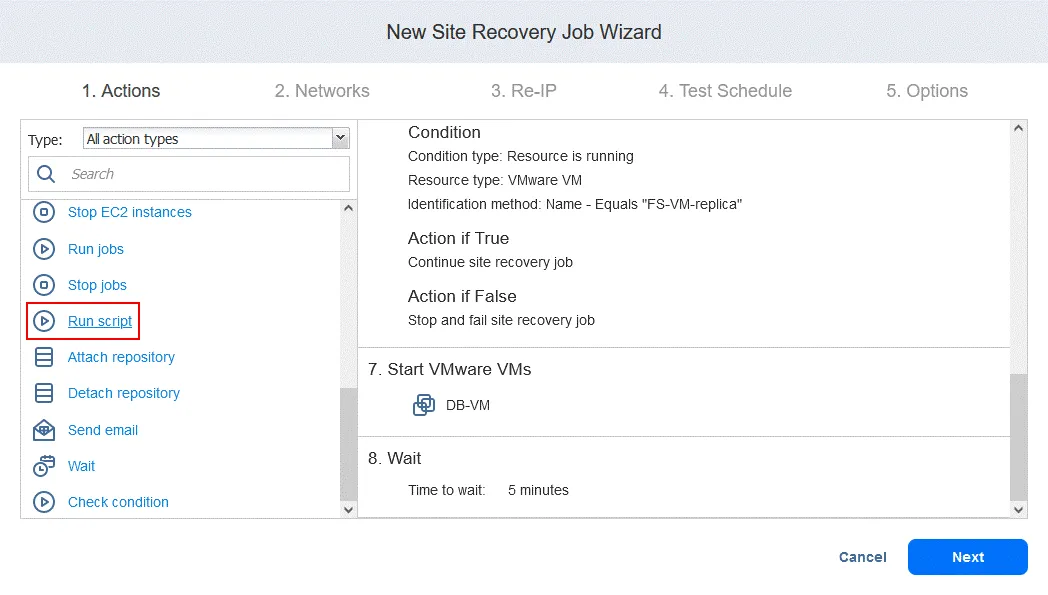
- Definir las opciones del script. En nuestro caso:
- Tipo de objetivo: VMware VM
- VM de destino: DB-VM
- Ruta del script: /home/oracle/restore.db.sh
- Nombre de usuario: oracle
- Contraseña: (contraseña)
La ruta del script, el nombre de usuario y la contraseña serán diferentes. No olvides asegurarte de que un archivo de script es ejecutable y de que el usuario tiene permisos suficientes para ejecutar el script. Las opciones de acción se configuran como de costumbre en este ejemplo.
Haga clic en Guardar cuando esté listo para continuar.
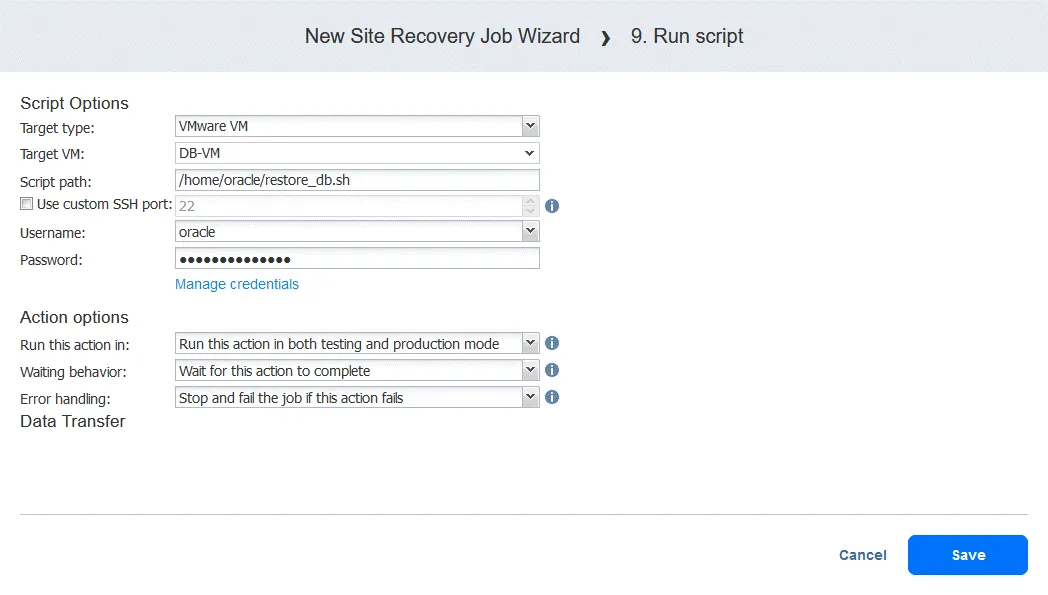
- Ahora puede ver todas las acciones configuradas. Haga clic en el botón Siguiente para continuar con la configuración de la función Site Recovery basada en su plan de recuperación ante desastres.
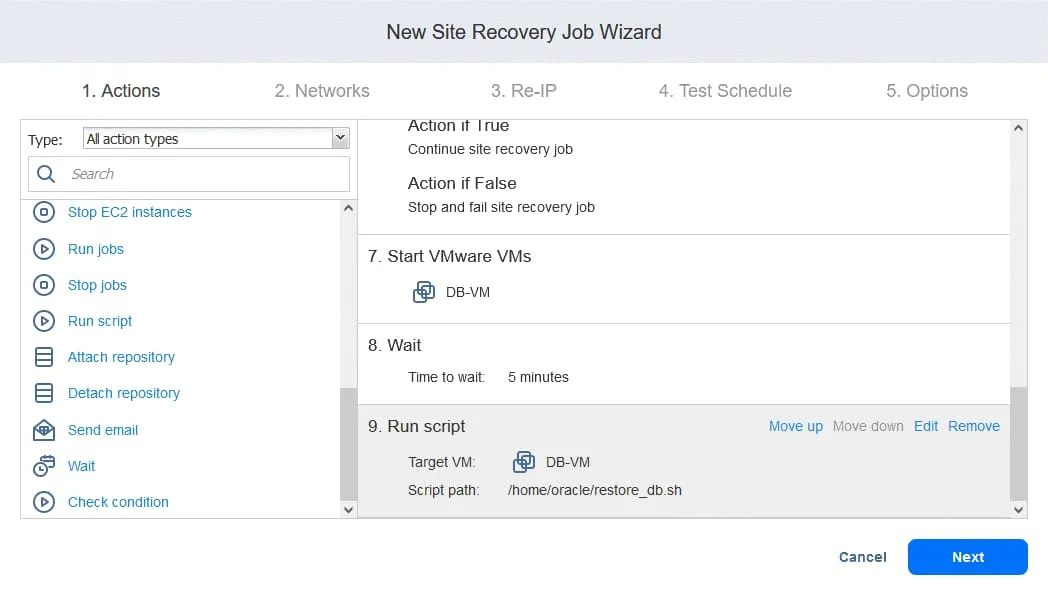
2. Redes
Si las máquinas virtuales del sitio de producción y del sitio de DR están conectadas a redes diferentes, seleccione Activar mapeo de la red. Haga clic en Crear nuevo mapeo y, en las ventanas emergentes, seleccione una red de origen, una red de destino y una red para utilizar en las pruebas de la función Site Recovery.
Haga clic en Guardar para guardar la regla de mapeo de la red y, a continuación, en Siguiente.
Nota: También puede utilizar las reglas de asignación existentes si las ha configurado en otros jobs de replicación, conmutación por error o restauración del entorno.
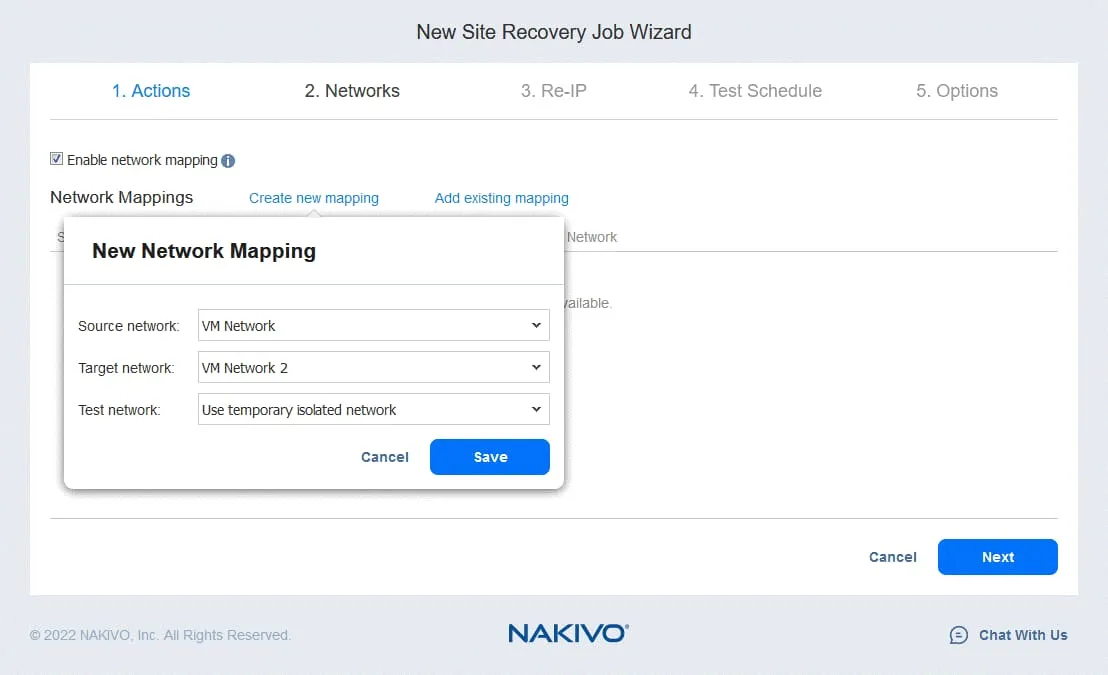
3. Re-IP
Si las redes utilizadas para la conexión de máquinas virtuales en el sitio de origen y en el sitio de destino tienen direcciones diferentes, deberá activar Re-IP seleccionando Activar Re-IP.
- Cree una nueva regla Re-IP haciendo clic en Crear nueva regla. Defina los ajustes de origen y de destino y, a continuación, haga clic en Guardar.
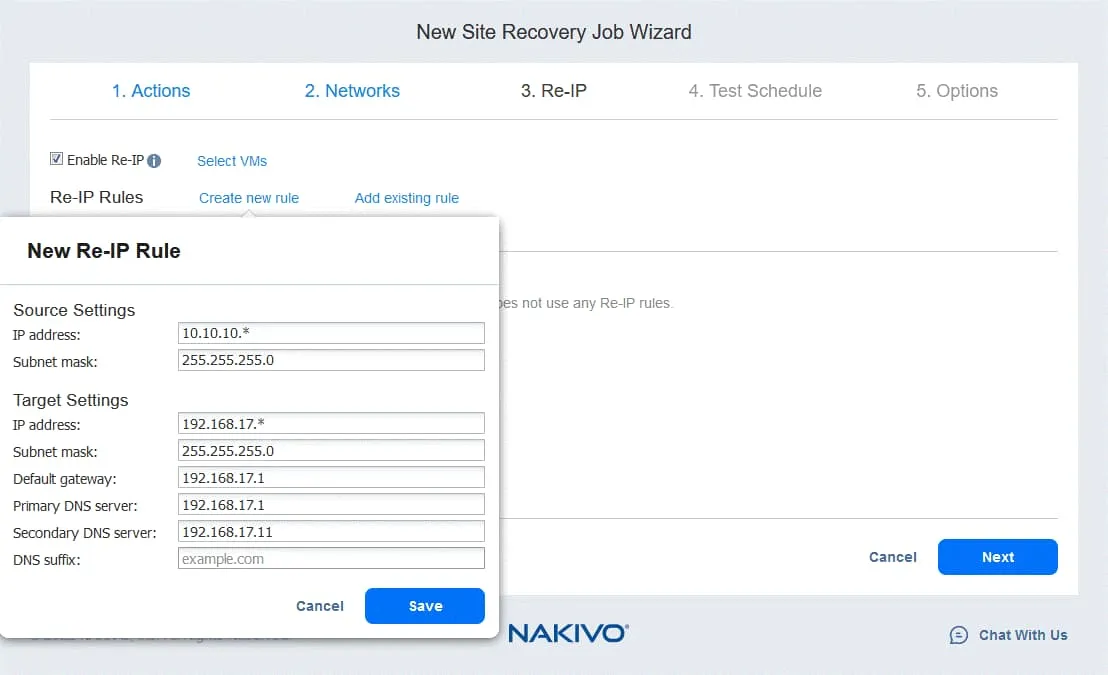
- Haga clic en Seleccionar máquinas virtuales y seleccione las máquinas virtuales para las que debe utilizarse Re-IP. Debe proporcionar las credenciales de un usuario con permisos suficientes para cambiar los ajustes de red en el SO invitado de la máquina virtual.
4. Calendario de pruebas
Puede crear una programación específica para ejecutar jobs de Site Recovery en modo de prueba y realizar pruebas de recuperación ante desastres. Esto permite comprobar si el job puede ejecutarse con éxito dentro de los plazos requeridos. Una vez hecho esto, haga clic en Siguiente.
Hablaremos de las pruebas de la función Site Recovery con más detalle en el paso 6.
5. Opciones
Escriba el nombre del job y el objetivo de tiempo de recuperación. Haga clic en Finalizar cuando haya terminado la configuración.
Paso 4. Volver a proteger el medio ambiente
Una vez que las máquinas virtuales han fallado y las cargas de trabajo se han migrado al sitio de DR, las máquinas virtuales de producción originales están ahora fuera de línea, y las réplicas en el sitio de DR son ahora las únicas copias funcionales. Si ahora falla una réplica de máquina virtual encendida, no podrá restaurar rápidamente los datos y las cargas de trabajo.
Para proteger las máquinas virtuales que se ejecutan en el sitio de DR, debe replicar estas máquinas virtuales en otro lugar seguro. De este modo, si la máquina virtual que se ejecuta en el sitio de DR falla, puede conmutar rápidamente a la nueva réplica de la máquina virtual.
La función Site Recovery permite configurar la replicación automatizada en cuanto se completa la conmutación por error de la máquina virtual. A continuación se muestra un ejemplo de cómo volver a proteger las máquinas virtuales con una función Site Recovery después de una conmutación por error.
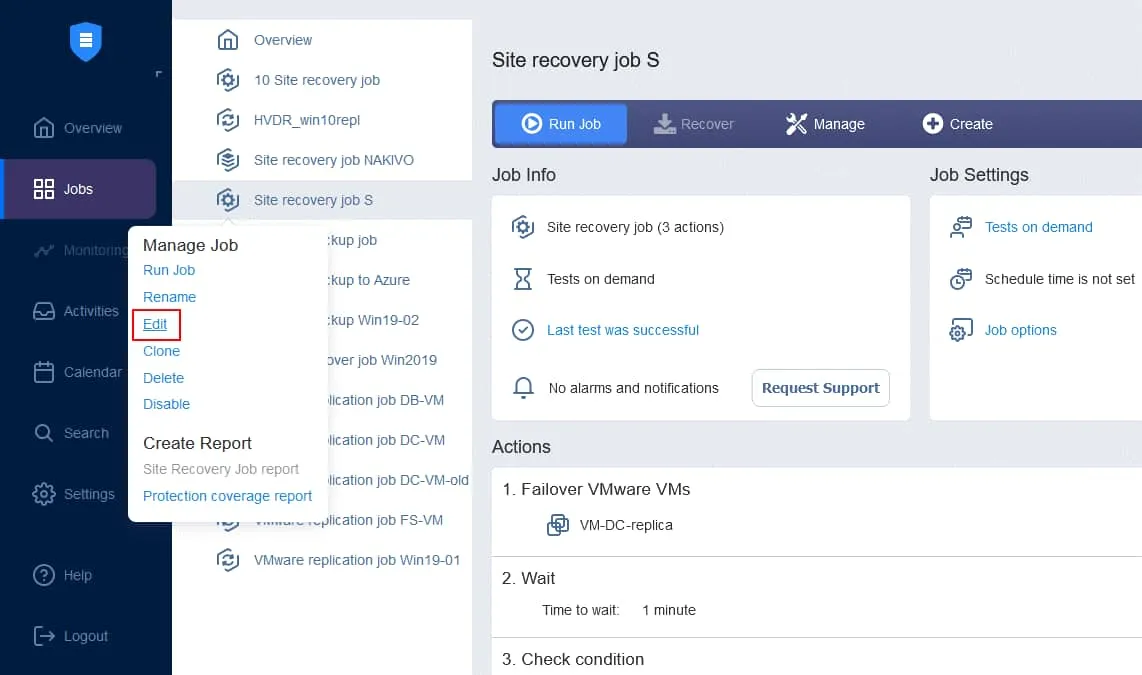
- En la página Jobs, haga clic con el botón derecho del ratón en el nombre de la función Site Recovery que ha creado recientemente. Haga clic en Editar en el menú contextual.
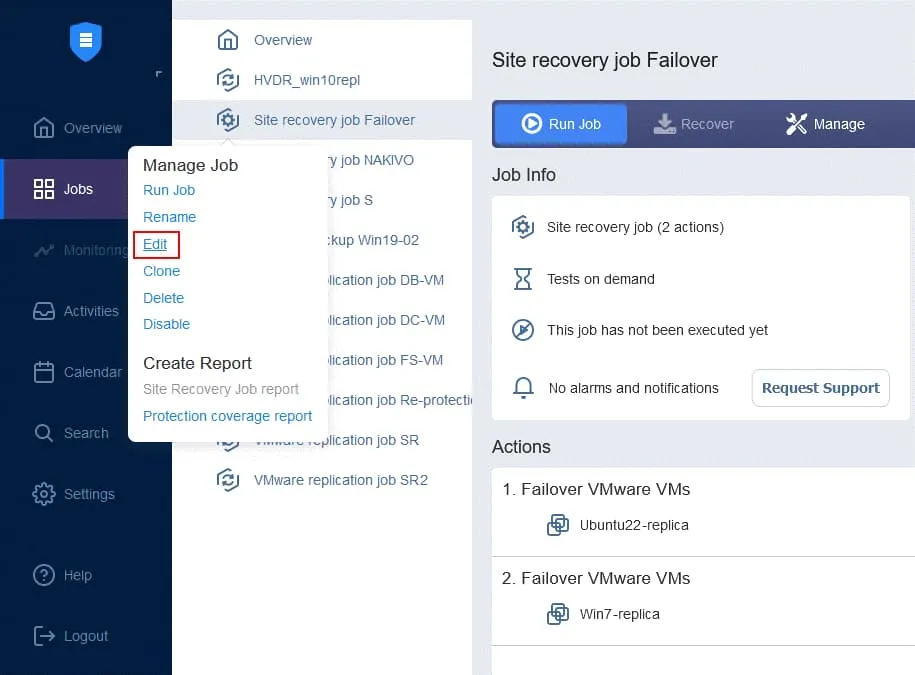
- Antes podrá ver las acciones de conmutación por recuperación añadidas a la función Site Recovery. Busque y haga clic en Ejecutar jobs en la lista de acciones situada en el panel izquierdo de la pantalla Acciones de Site Recovery.

- Seleccione el job de replicación de la lista de jobs. Seleccione las opciones de acción como de costumbre y haga clic en Guardar.
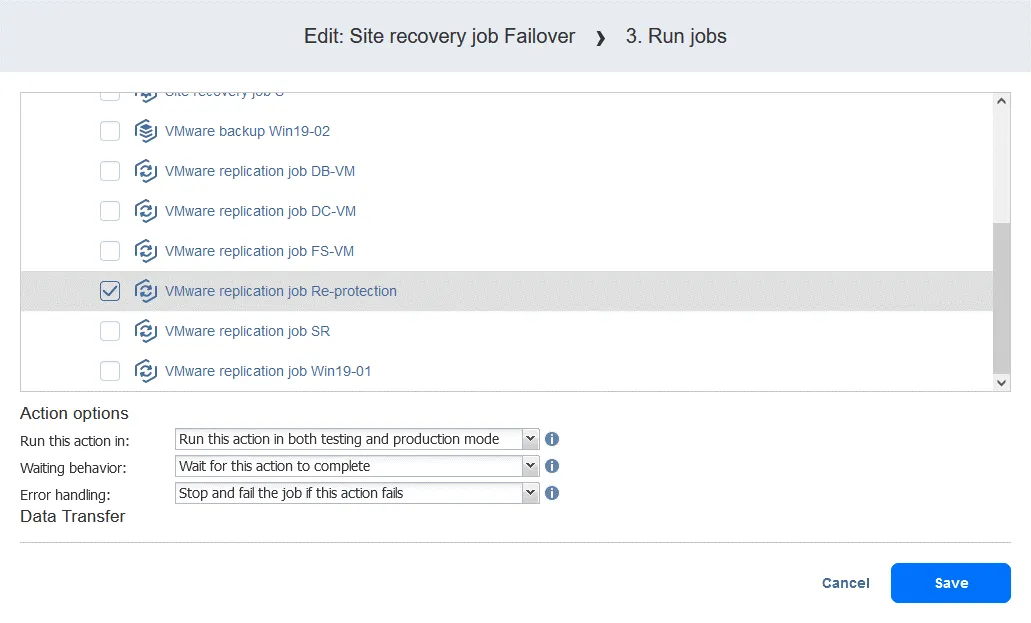
- Añada una acción de espera entre la acción de conmutación por recuperación y el job de replicación. Esto le da a la réplica de la VM algo de tiempo para arrancar y cargar el sistema operativo (no se puede replicar una VM apagada). En la lista Acciones del panel izquierdo, haga clic en Esperar.

- Seleccione un tiempo de espera – 5 minutos deberían ser suficientes. Seleccione las opciones de acción y haga clic en Guardar.
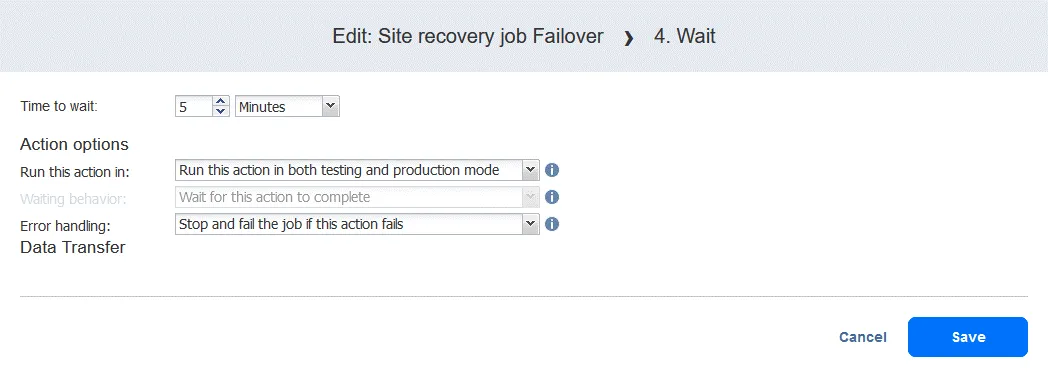
- Al añadir la acción, se añade al final de la lista de acciones. Haga clic en Mover hacia arriba y mueva la acción Esperar de la cuarta posición a la tercera: debe producirse antes de la replicación.
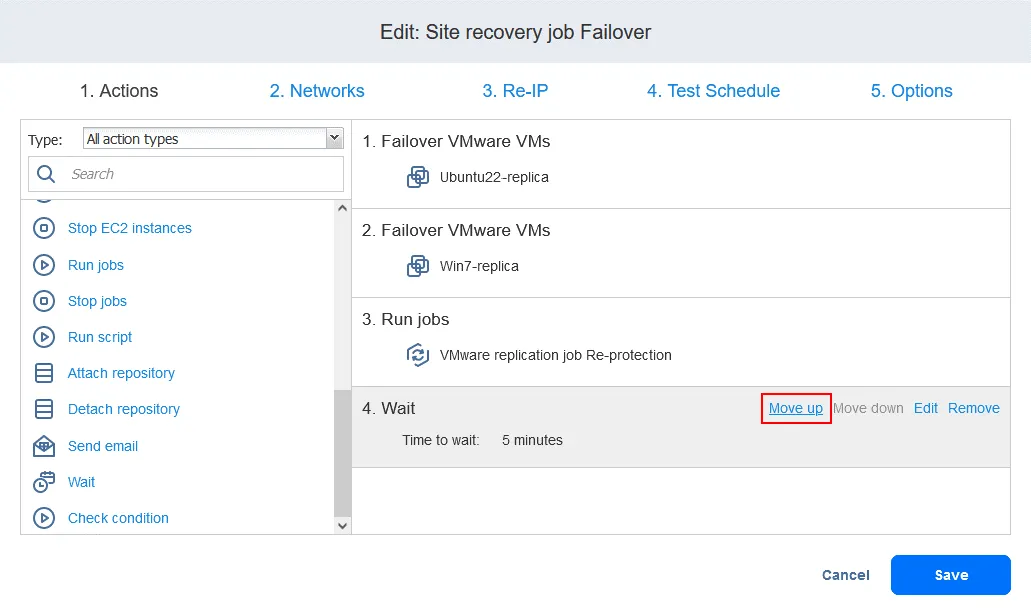
Ahora las acciones están dispuestas en el orden necesario.
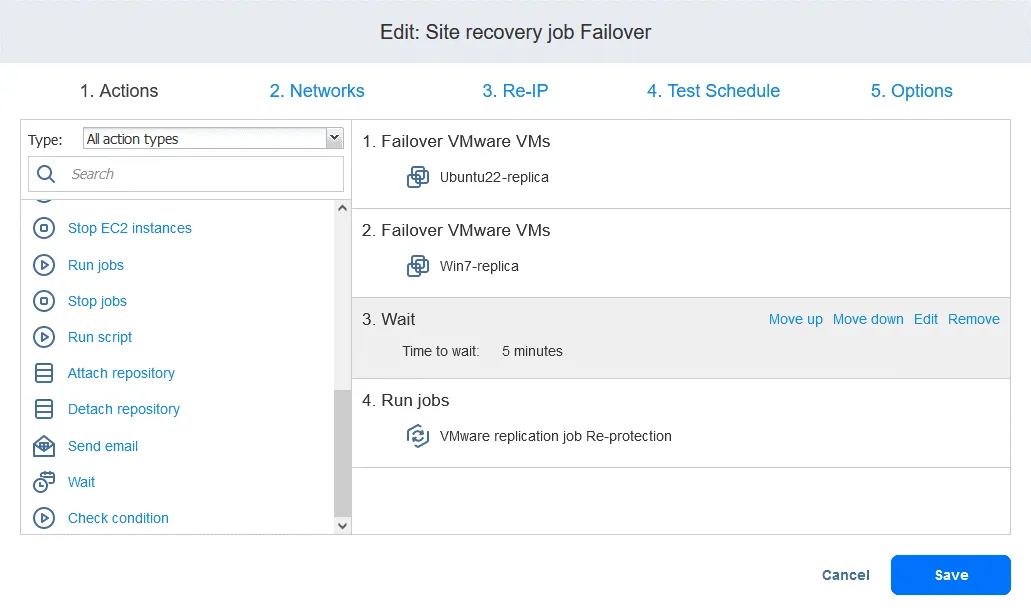
- Por último, el job Site Recovery está listo para ser utilizado para realizar la conmutación por error de las máquinas virtuales y la protección automática de las réplicas de las máquinas virtuales utilizadas para la conmutación por error. Haga clic con el botón derecho en el nombre de su función Site Recovery en la página de inicio y haga clic en Ejecutar job en el menú contextual.
Paso 5. Conmutación por error
La conmutación por error es el proceso de restauración de máquinas virtuales en sus últimos estados desde el sitio de DR al sitio original o a un nuevo sitio de producción. Para entender por qué necesita la conmutación por error, recapitulemos cómo funciona la conmutación por recuperación:
- Cuando se produce un desastre (o se prevé que se produzca), se realiza una conmutación por recuperación a una réplica de la máquina virtual.
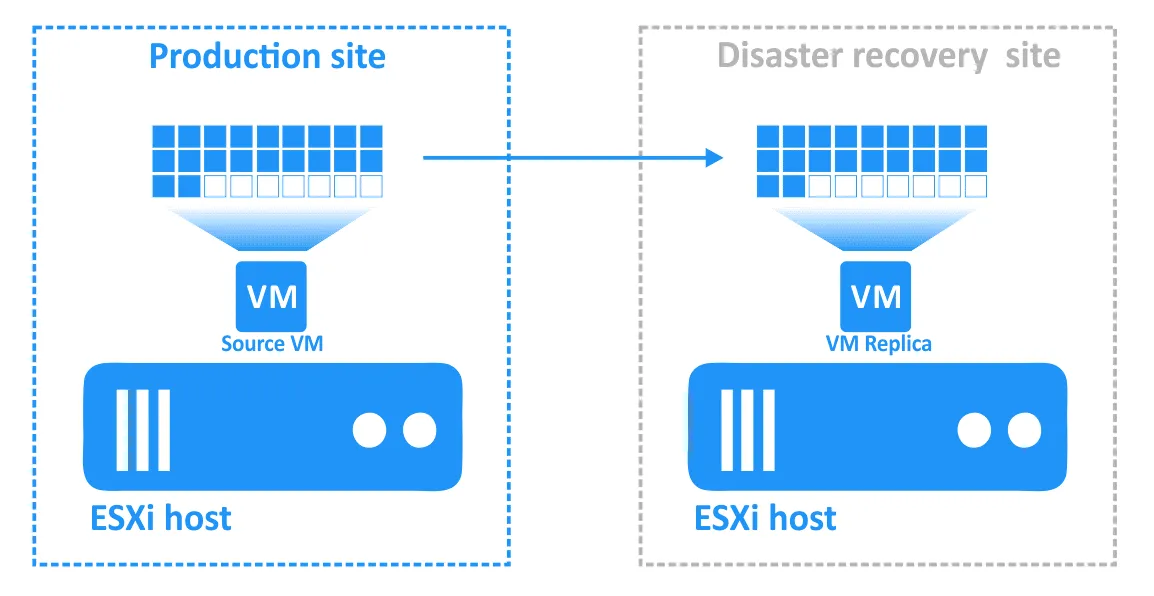
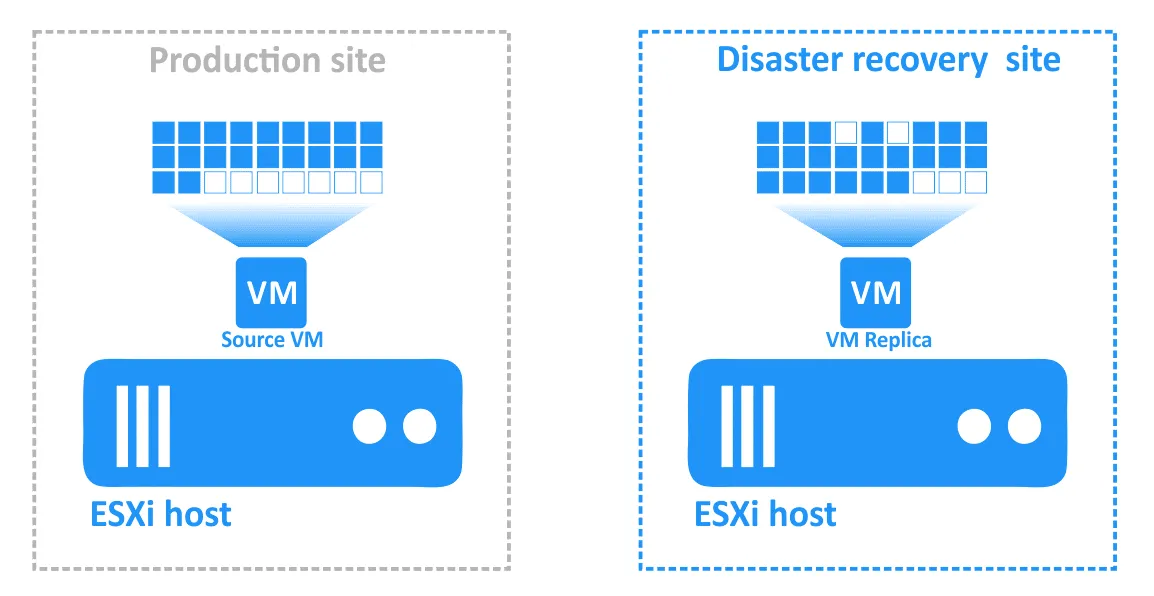
- Cualquier cambio en la máquina virtual (por ejemplo, transacciones añadidas a una base de datos a medida que los clientes realizan compras en línea) se escribe en un disco virtual de la réplica de la máquina virtual. Algunos bloques se escriben y otros se borran. El disco virtual de la máquina virtual de origen no tiene esas transacciones.
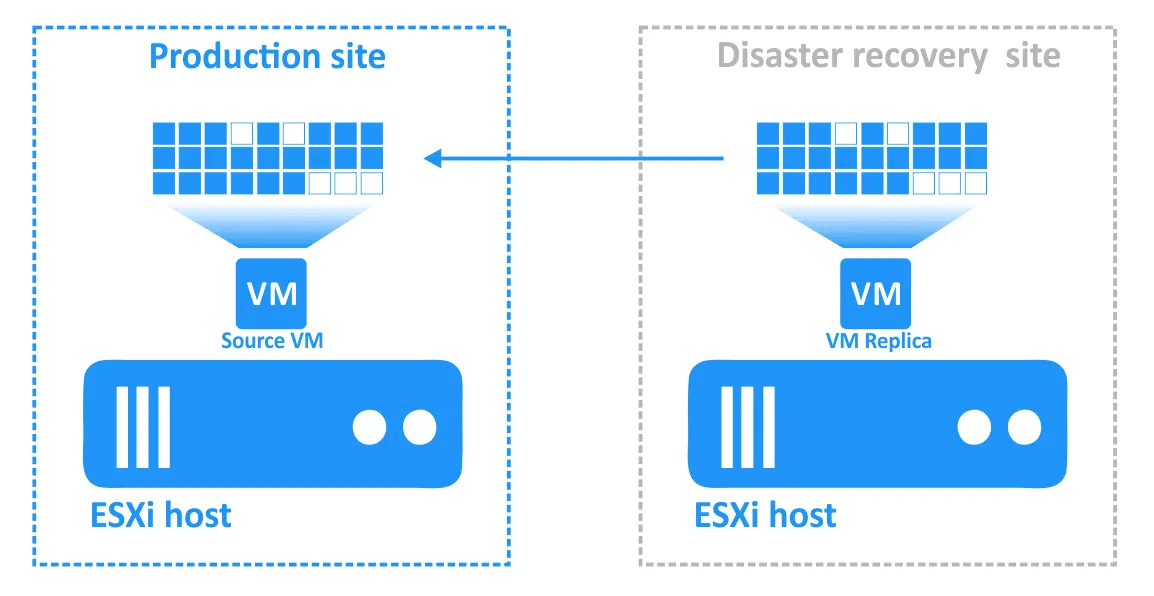
- Una vez que el incidente se ha resuelto y el sitio de producción vuelve a ser funcional, las cargas de trabajo deben volver al sitio de producción. Los datos actualizados de la réplica de la máquina virtual deben transferirse de nuevo a la máquina virtual de origen. Las máquinas virtuales deben volver a sincronizarse con la replicación inversa mediante conmutación por error.
Configurar la conmutación por error en NAKIVO Backup & Replication
La conmutación por error puede realizarse tanto en modo de producción como en modo de prueba (cuando todos los cambios realizados en su entorno virtual por la acción de conmutación por error se revierten al estado anterior a la conmutación por error después de la prueba).
Veamos en detalle cómo funciona cada caso.
| Conmutación por error en la producción | Prueba de conmutación por error | |
| 1 | Apagar la máquina virtual de origen (si existe y está encendida). | |
| 2 |
Creación de una instantánea de protección de la máquina virtual de origen (si la máquina virtual de origen es funcional). La creación de esta instantánea permite restaurar un estado previo a la conmutación por error de la máquina virtual de origen en caso de que la conmutación por error no pueda realizarse correctamente. |
|
| 3 | Ejecutar la replicación incremental (si la máquina virtual fuente original está en línea en el sitio de producción) o la replicación completa (si la máquina virtual se está recuperando en un nuevo sitio de producción). | |
| 4 | Apagado de la réplica VM (opcional). | La réplica VM se utiliza para alojar las cargas de trabajo y no se apaga. |
| 5 | La replicación incremental se ejecuta una vez más desde la réplica VM a la VM de origen. El delta (los datos que cambiaron desde la primera ejecución de replicación) debería ser mucho menor esta vez. | La replicación desde una réplica de máquina virtual a la máquina virtual de origen (o a una nueva máquina virtual de producción) se realiza una sola vez, ya que es suficiente para realizar pruebas. |
| 6 | Conectar la máquina virtual de origen a su nueva red con el mapeo de la red (opcional). | Conectar la máquina virtual de origen a una red aislada para que no haya ningún tipo de interrupción en el entorno de producción (opcional). |
| 7 | Modificación de la dirección IP estática de la máquina virtual de origen con Re-IP (opcional). | |
| 8 | Encendido de la máquina virtual de origen. | |
| 9 | Limpieza tras una conmutación por error correcta. Después de una operación de conmutación por error con éxito, tanto la máquina virtual de origen como la réplica de la máquina virtual existen en sus estados normales.
Limpieza tras una conmutación por error fallida:
|
Limpieza si la máquina virtual de origen no existía antes de ejecutar la prueba de conmutación por error:
Limpieza si la máquina virtual de origen ya existía antes de que se ejecutara la conmutación por error de prueba:
|
Preparación para la conmutación por error
En primer lugar, debe crear un job de Site Recovery que incluya acciones de conmutación por recuperación. Este proceso ya se ha descrito antes en detalle.
- Se requiere un job de replicación y una réplica VM para realizar una acción de conmutación por error.
- Un job de Site Recovery debe incluir una acción de conmutación por error para poder realizar el failback.
- Las réplicas de la máquina virtual deben estar en estado de conmutación por error; por lo tanto, puede realizar la conmutación por error sólo después de realizar la conmutación por error.
Ejecución de conmutación por error
Veamos un ejemplo de cómo hacer una conmutación por error con NAKIVO Backup & Replication.
- Asegúrese de que la conmutación por recuperación se ha ejecutado como parte de un job de Site Recovery (éste ya debería haberse creado).
- Cree una nueva función Site Recovery – las acciones de conmutación por error pueden incorporarse a este job. En la página Jobs, haga clic en Create > Site Recovery job.
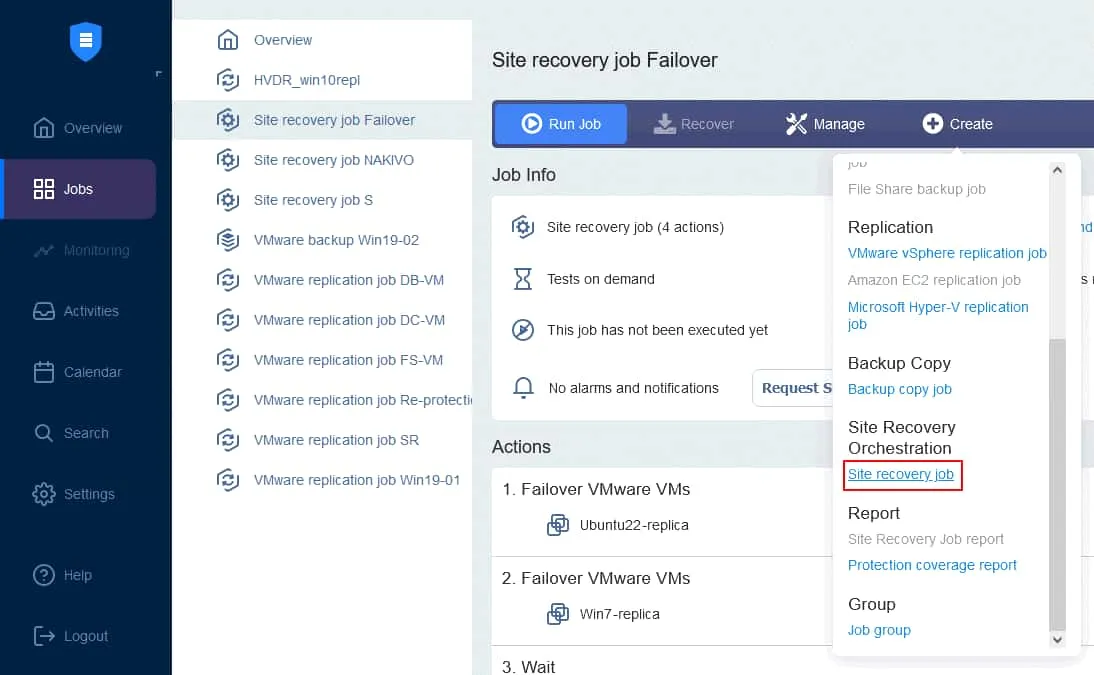
Se inicia el Asistente para nueva función Site Recovery.
1. Acciones.
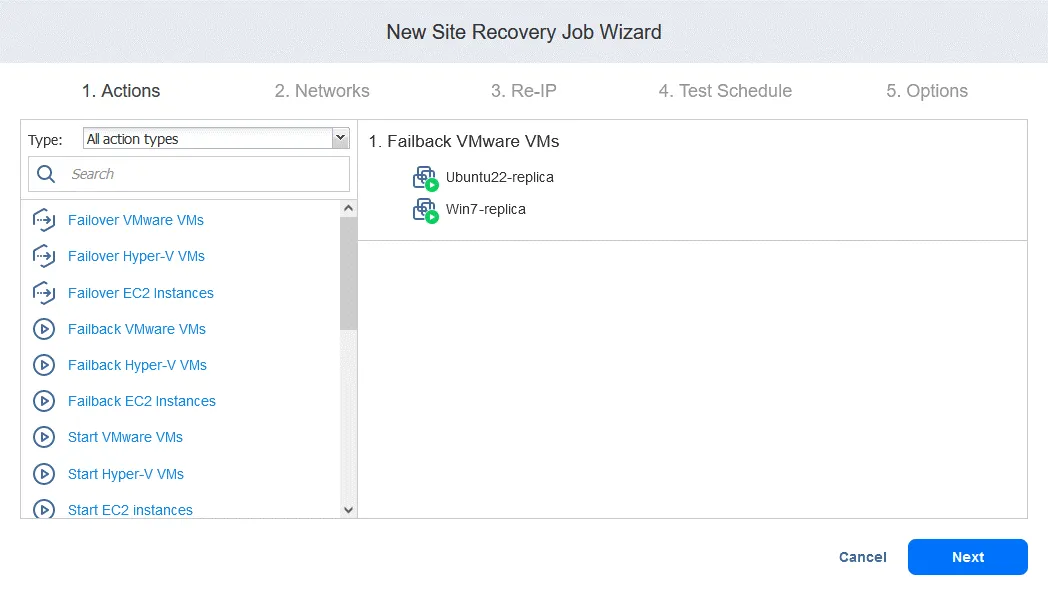
- En el panel izquierdo, haga clic en Failback VMware VMs (para otros entornos, utilice Failback Hyper-V VMs o Failback EC2 Instances).
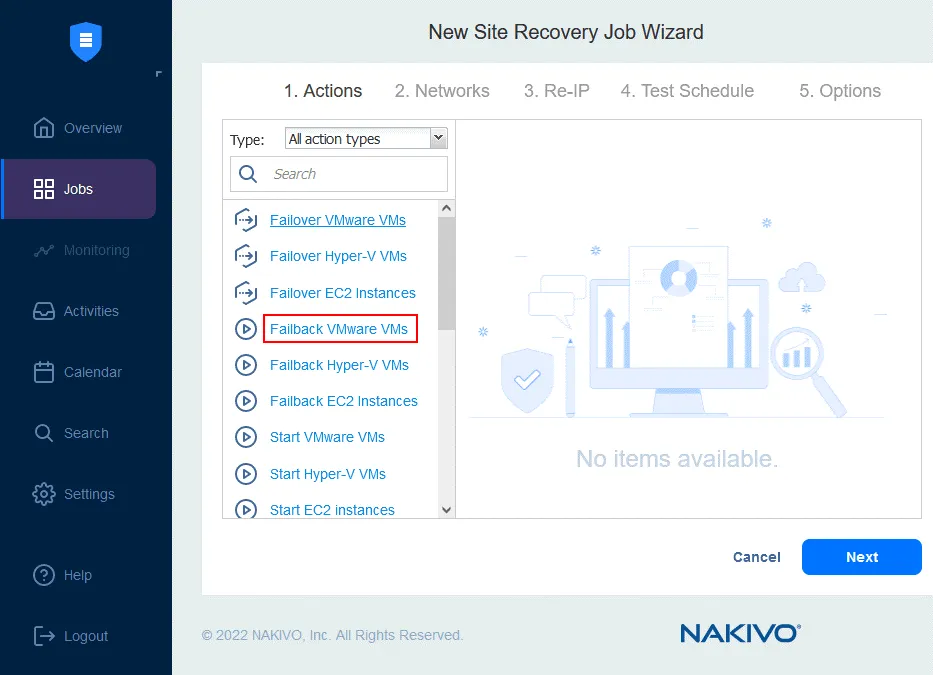
- Seleccione las réplicas de VM a las que debe aplicarse la operación de conmutación por recuperación. Haga clic en Siguiente.
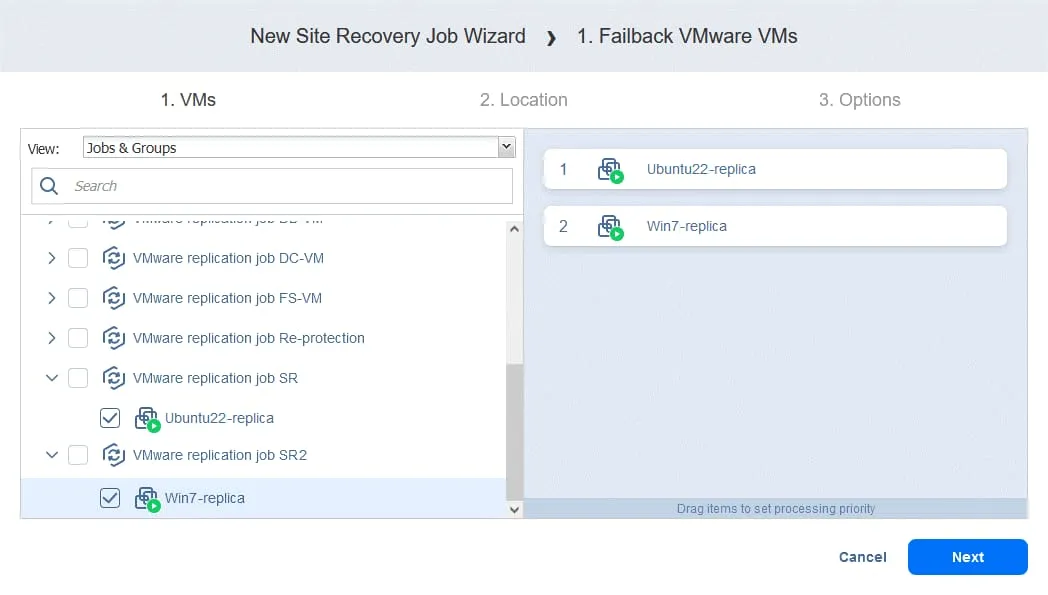
- Seleccione una ubicación de conmutación por error: puede ser el sitio de producción original o una nueva ubicación. Haga clic en Siguiente.

- Seleccione las opciones del job. Seleccione Apagar réplica VMs si es necesario. Haga clic en Guardar cuando esté listo para continuar.
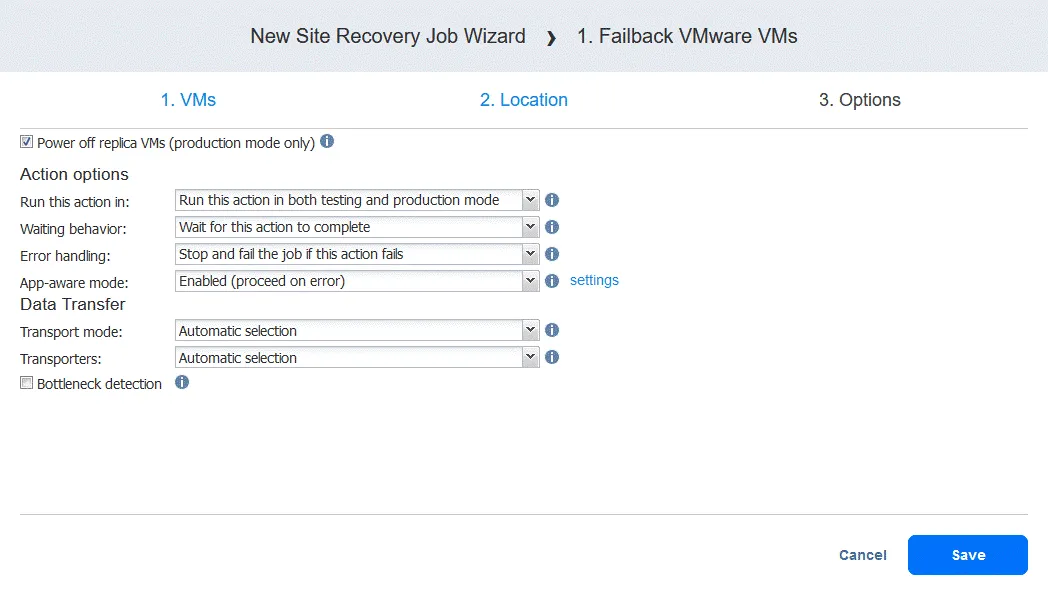
- Una vez añadida la acción de conmutación por error, el job de Site Recovery tendrá el aspecto que se muestra en la siguiente captura de pantalla. Haga clic en Siguiente.
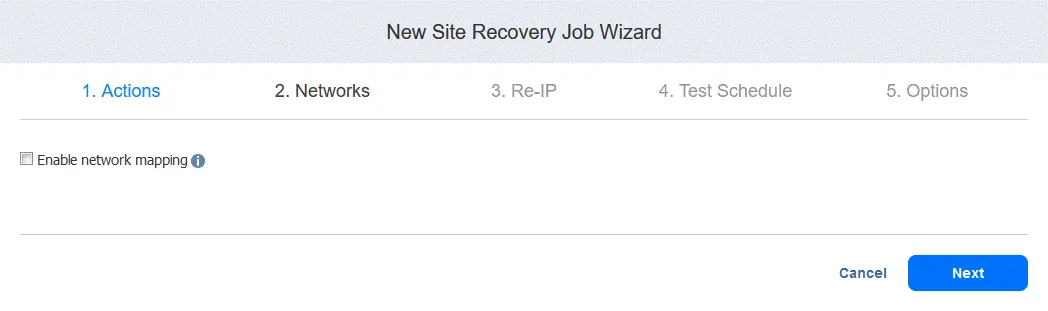
2. Redes. Seleccione esta opción si necesita activar el mapeo de la red para este job. Haga clic en Siguiente.
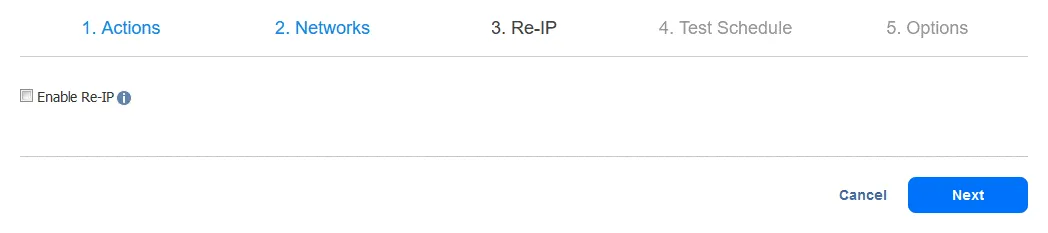
3. Re-IP. Seleccione esta opción si necesita activar Re-IP para este job. Haga clic en Siguiente.
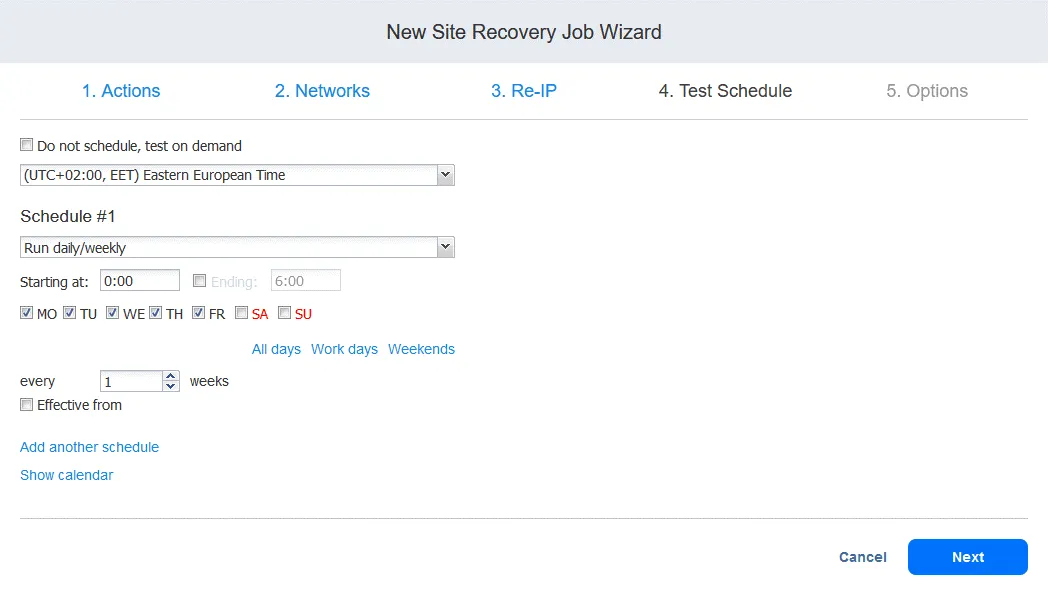
4. Calendario de pruebas. Configure las opciones de programación y haga clic en Siguiente.
5. Opciones. Defina las opciones de la función Site Recovery e introduzca el nombre del job. Puede establecer el RTO necesario para la máquina virtual y especificar la dirección de correo electrónico para el informe de conmutación por error. Haga clic en Finish para finalizar la creación de este nuevo job de Site Recovery con conmutación por error.
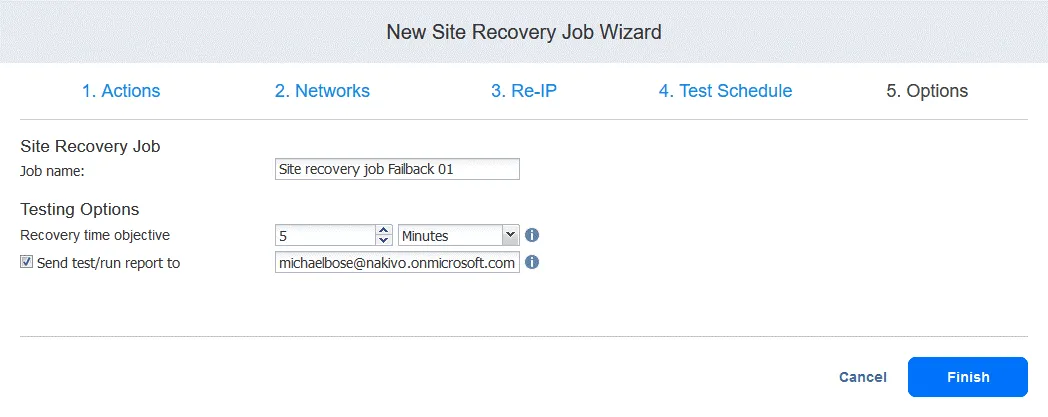
Ahora puede ejecutar este job de Site Recovery para realizar la conmutación por error de la VM: Simplemente haga clic con el botón derecho en el nombre de la función Site Recovery, seleccione Run job y seleccione Test site recovery job o Run site recovery job.

Paso 6. Realización de pruebas de recuperación ante desastres
Las pruebas de recuperación ante desastres le ayudan a asegurarse de que está preparado para la recuperación cuando se produzca un desastre y de que todos los componentes seleccionados pueden recuperarse con éxito dentro de los plazos establecidos.
Hay dos razones principales por las que necesita pruebas de recuperación ante desastres:
- Para asegurarse de que todo puede recuperarse con éxito. Cuando ponga a prueba su plan de recuperación ante desastres y descubra que algunas cosas van mal, podrá solucionar los problemas antes de que causen problemas graves en un escenario de crisis real.
- Para garantizar el cumplimiento de los valores RTO. Las pruebas de recuperación ante desastres le permiten comprobar si sus cargas de trabajo pueden recuperarse dentro de los RTO pertinentes. Una prueba de restauración del entorno puede ejecutarse manualmente bajo demanda o automáticamente de forma programada, lo que hace que el proceso sea indoloro y le ahorre tiempo.
Diferencias entre conmutación por recuperación en pruebas y en producción
El mecanismo de ejecución de una conmutación por recuperación difiere en función de si el job de Site Recovery se ejecuta en modo de prueba o de producción. En la tabla siguiente se muestra un desglose de los pasos para cada modo.
| Conmutación por recuperación de la producción (emergencia) | Prueba de conmutación por recuperación | |
| 1 | Desactivar la replicación de la máquina virtual de origen a la réplica | |
| 2 | Hacer retroceder la réplica de la máquina virtual a un determinado punto de recuperación (RP) (opcional, por defecto se utiliza el último RP). | Ejecutar la replicación incremental de la máquina virtual de origen a la réplica una vez |
| 3 | Conecte la réplica de la máquina virtual a una nueva red con el mapeo de la red (opcional). | Conecte la réplica VM a una red aislada con mapeo de la red (opcional) |
| 4 | Modificar la dirección IP estática de la réplica con Re-IP (opcional) | |
| 4A | Apagar la máquina virtual de origen (opcional) | — |
| 5 | Encender la réplica | |
| 6 | Conmutación de la réplica por recuperación | |
Como puede ver, los puntos segundo y tercero difieren entre los flujos de trabajo de producción y de prueba. Puede ejecutar la replicación desde una máquina virtual de origen en modo de prueba mientras la máquina virtual de origen está en ejecución. En la mayoría de los casos, cuando se produce un desastre, la máquina virtual de origen deja de funcionar y, por tanto, no se puede realizar la replicación. Las redes para la conexión de máquinas virtuales pueden definirse por separado en las opciones de mapeo de la red para el modo de producción y el modo de prueba al configurar un job de Site Recovery.
La limpieza de prueba de conmutación por error se realiza tras la ejecución de un job de Site Recovery en modo de prueba. La réplica de la máquina virtual se apaga y vuelve a su estado anterior a la conmutación por error mediante una instantánea (se toma una instantánea de una réplica de la máquina virtual antes de realizar una acción de conmutación por error). A continuación, la réplica pasa del estado de conmutación por recuperación a su estado normal y se vuelve a activar la replicación desde el objeto de origen a la réplica.
Capacidades de prueba de recuperación ante desastres en la función Site Recovery de NAKIVO.
Repasemos rápidamente los puntos principales de la función Site Recovery de NAKIVO.
1. Comprobación de las acciones incluidas en las pruebas
Revise la lógica de las acciones de la función Site Recovery. Compruebe si las acciones están dispuestas en el orden adecuado y asegúrese de que no forman un bucle infinito. Puede editar las opciones de la función Site Recovery cuando el job no se está ejecutando: cambie el orden de las acciones, añada acciones, elimine acciones o edite las opciones de acción según sea necesario.
2. Comprobación de la red
Compruebe que su red funciona correctamente. Se puede utilizar una conexión VPN entre un sitio de producción y un sitio de recuperación ante desastres (DR), pero esta conexión no se puede desconectar periódicamente en estado normal. La red del emplazamiento de RD también debe funcionar sin interrupciones. Compruebe los ajustes de mapeo de la red y Re-IP que ha utilizado para configurar la conmutación por error y la recuperación. Si una máquina virtual está configurada para una red incorrecta, puede que no se establezca una conexión de red. Lo mismo ocurre con los ajustes de IP.
3. Configuración de la programación de la prueba
La prueba de la función Site Recovery puede programarse en las opciones de programación del job de Site Recovery. Abra la interfaz web de su instancia de NAKIVO Backup & Replication. En el panel izquierdo, haga clic con el botón derecho del ratón en el nombre de su job y haga clic en Editar en el menú contextual.
Ventajas de la función Site Recovery de NAKIVO
- Completa orquestación y automatización de la RD. La función Site Recovery permite implantar planes de recuperación ante desastres con altos niveles de automatización. Puede definir el orden de recuperación de las máquinas virtuales teniendo en cuenta sus dependencias para que, cuando se produzca un desastre, la recuperación sea lo más eficaz posible.
- Flexibilidad para adaptarse a las necesidades de diversas empresas. Puede crear varios jobs de restauración del entorno según sus necesidades. El conjunto de acciones disponibles para su incorporación a los jobs de Site Recovery permite crear diferentes flujos de trabajo de recuperación personalizados para distintas situaciones.
- Integrado en la solución de protección de datos. Site Recovery es una función incluida en NAKIVO Backup & Replication y disponible junto con el resto del completo conjunto de funciones del producto; no es necesario adquirir una licencia independiente para Site Recovery. Con esta solución, todas las actividades de protección de datos y recuperación ante desastres se gestionan desde un único panel de cristal.
- Ahorro significativo en comparación con otras soluciones de RD. NAKIVO Backup & Replication, con la herramienta Site Recovery integrada, es una solución rentable. El producto sigue complaciendo a los usuarios con nuevas y útiles funciones, al tiempo que mantiene los mismos precios asequibles, especialmente en comparación con los competidores del mercado de recuperación ante desastres.



