
Comparación y explicación de VMware vSphere HA y DRS
Un hipervisor VMware permite ejecutar máquinas virtuales en un único servidor. Puede ejecutar varias máquinas virtuales en un host ESXi independiente e implementar varios hosts para ejecutar más máquinas virtuales. Si dispone de varios hosts ESXi conectados a través de la red, puede migrar máquinas virtuales de un host a otro.
A veces, utilizar varios hosts conectados a través de la red para ejecutar máquinas virtuales no es suficiente para satisfacer las necesidades de la empresa. Por ejemplo, en los casos en los que falle un host, todas las máquinas virtuales que residan en ese host también fallarán. Además, las cargas de trabajo de las máquinas virtuales en hosts ESXi pueden estar desequilibradas, y la migración manual de máquinas virtuales entre hosts es rutinaria. Para hacer frente a estos problemas, VMware ofrece funciones de agrupación en clústeres como VMware High Availability (HA) y Distributed Resource Scheduler (DRS). El uso de vSphere clustering permite reducir el tiempo de inactividad de las máquinas virtuales y consumir los recursos de hardware de forma racional. Esta entrada de blog cubre VMware HA y DRS, así como los casos de uso práctico para cada función de clustering.

¿Qué es un clúster vSphere?
Un clúster vSphere es un conjunto de hosts ESXi conectados que comparten recursos de hardware como procesador, memoria y almacenamiento. Los clústeres de VMware vSphere se gestionan de forma centralizada en vCenter. Los recursos de un cluster se agregan en un pool de recursos, por lo que cuando añades un host a un cluster, los recursos del host pasan a formar parte de los recursos de todo el cluster. Los hosts ESXi que son miembros del clúster también se denominan nodos de clúster. Existen dos tipos de clústeres vSphere: vSphere High Availability y Distributed Resource Scheduler (VMware HA y DRS).
Requisitos del clúster VMware
Para implantar VMware HA y DRS, es necesario cumplir una serie de requisitos de clúster:
- Deben utilizarse dos o más hosts ESXi con una configuración idéntica(procesadores de la misma familia, versión de ESXi y nivel de parches, etc.). Por ejemplo, puede utilizar dos servidores con procesadores Intel de la misma familia (o procesadores AMD) y ESXi 7.0 Actualización 3 instalado en los servidores. Se recomienda utilizar al menos tres hosts para mejorar la protección y el rendimiento.
- Conexiones de red de alta velocidad para la red de gestión, la red de almacenamiento y la red vMotion. Se requieren conexiones de red redundantes.
- Un almacén de datos compartido al que pueden acceder todos los hosts ESXi de un clúster. La red de área de almacenamiento (SAN), el almacenamiento conectado a la red (NAS) y VMware vSAN pueden utilizarse como almacén de datos compartido. Los protocolos NFS e iSCSI son compatibles para acceder a los datos de un almacén de datos compartido. Los archivos de la máquina virtual deben almacenarse en un almacén de datos compartido.
- VMware vCenter Server compatible con la versión de ESXi instalada en los hosts.
A diferencia de un clúster de conmutación por recuperación de Hyper-V, no se requiere quórum y no es necesario utilizar nombres de red complejos.
¿Qué es VMware HA en vSphere?
VMware vSphere High Availability (HA) es una función de clustering diseñada para reiniciar una máquina virtual (VM) automáticamente en caso de fallo. VMware vSphere High Availability permite a las organizaciones garantizar una alta disponibilidad para las máquinas virtuales y las aplicaciones que se ejecutan en las máquinas virtuales de un clúster vSphere (independientemente de las aplicaciones en ejecución). VMware HA puede proporcionar protección contra el fallo de un host ESXi: la máquina virtual que ha fallado se reinicia en un host sano. Como resultado, puede reducir significativamente el tiempo de inactividad.
Requisitos para vSphere HA
Los requisitos para vSphere HA deben tenerse en cuenta junto con los requisitos generales del clúster de vSphere. Para configurar VMware vSphere High Availability, debe tener:
- Una licencia de VMware vSphere Standard
- Mínimo 4 GB de RAM en cada host
- Una pasarela pingable
¿Cómo funciona vSphere HA?
VMware vSphere High Availability comprueba los hosts ESXi para detectar un fallo de host. Si se detecta un fallo en el host (las máquinas virtuales que se ejecutan en ese host también fallan), las máquinas virtuales que han fallado se migran a hosts ESXi sanos dentro del clúster. Tras la migración, las máquinas virtuales se registran en los nuevos hosts y, a continuación, se inician. Los archivos de la máquina virtual (VMX, VMDK y otros archivos) se encuentran en el mismo recurso, que es un almacén de datos compartido, después de la migración. Los archivos de la máquina virtual no se migran. Sólo los componentes de CPU, memoria y red utilizados por las máquinas virtuales fallidas son proporcionados por el nuevo host ESXi después de la migración.
El tiempo de inactividad es igual al tiempo necesario para reiniciar una máquina virtual en otro host. Sin embargo, ten en cuenta que también hay que tener en cuenta el tiempo necesario para que el sistema operativo arranque y para cargar las aplicaciones necesarias en una máquina virtual. VMware HA es una solución que funciona en la capa VM y que también puede utilizarse si las aplicaciones no disponen de funciones nativas de alta disponibilidad. VMware vSphere High Availability no depende del sistema operativo invitado instalado en la máquina virtual.
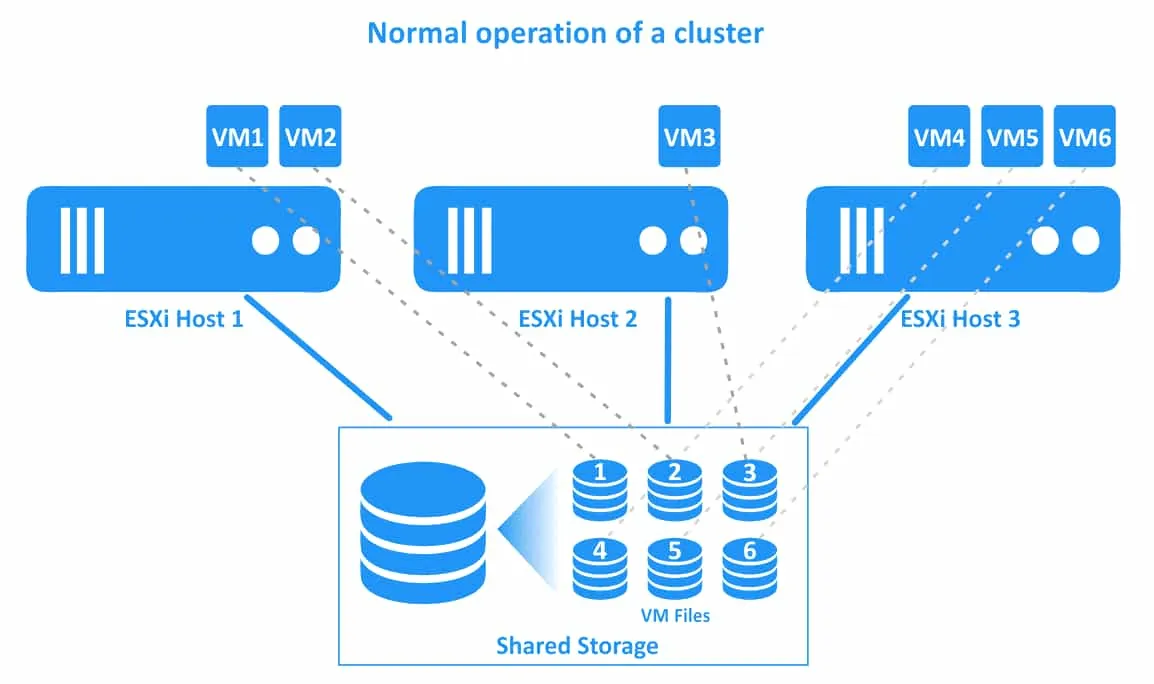
El flujo de trabajo de un clúster vSphere HA se ilustra en el siguiente diagrama. En este ejemplo hay un cluster con tres hosts ESXi. Las máquinas virtuales se ejecutan en todos los hosts. Las conexiones de las máquinas virtuales y sus archivos se ilustran con líneas de puntos.
1. El funcionamiento normal de un clúster. Todas las máquinas virtuales se ejecutan en sus hosts nativos.
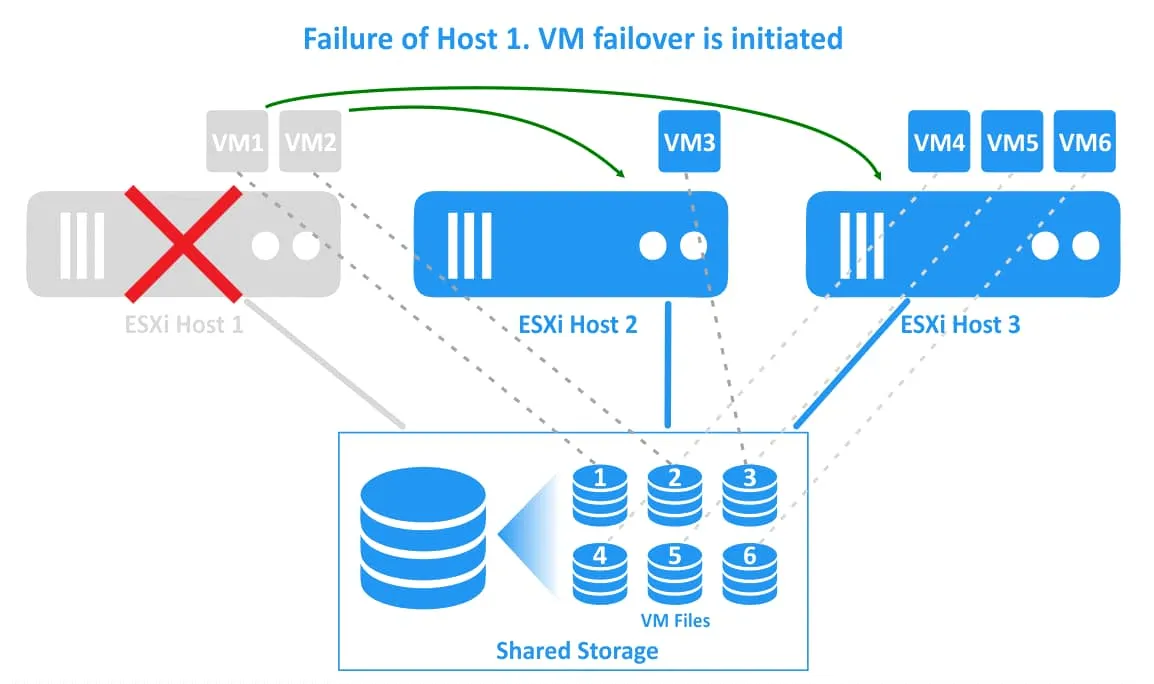
2. El host ESXi 1 falla. Las máquinas virtuales que residen en el host ESXi 1 (VM1 y VM2) han fallado (estas máquinas virtuales están apagadas). Un clúster de HA de vSphere inicia reinicios de máquinas virtuales en otros hosts ESXi sanos.
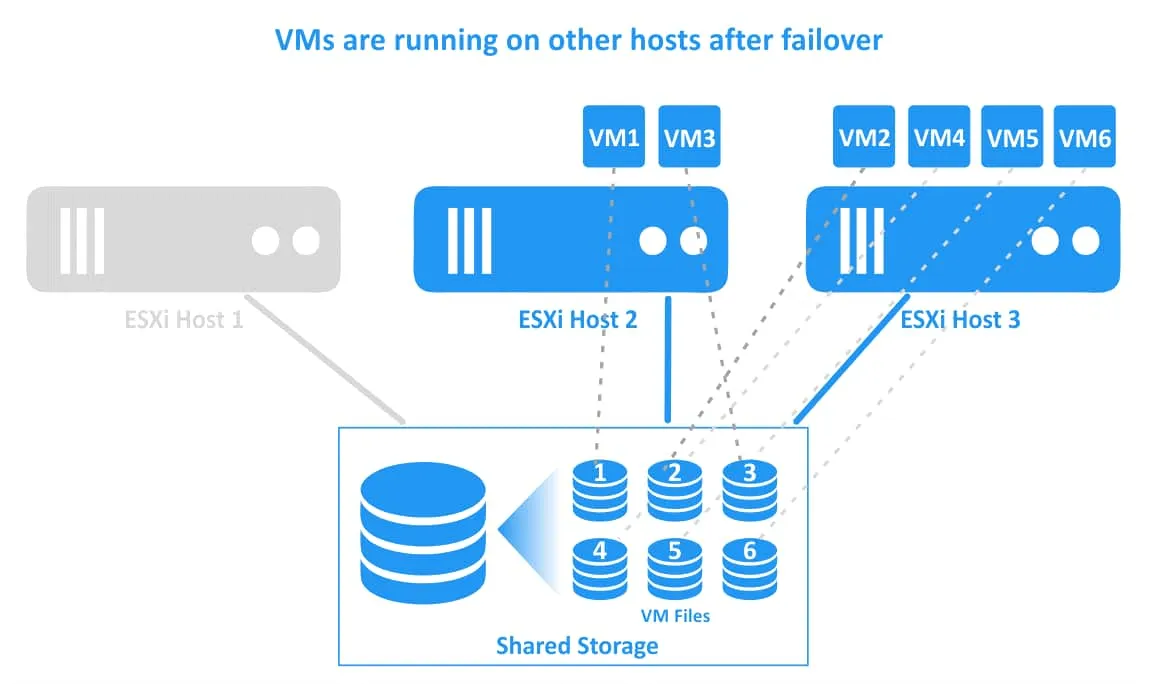
3. Las máquinas virtuales se han migrado y reiniciado en hosts sanos. VM1 se ha migrado al host ESXi 2, y VM2 se ha migrado al host ESXi 3. Los archivos de las máquinas virtuales se ubican en el mismo lugar del almacenamiento compartido que está conectado a todos los hosts ESXi del clúster vSphere.
Maestro y subordinados de HA
Una vez habilitada la alta disponibilidad de vSphere en el clúster, se selecciona un host ESXi como maestro de HA. Otros hosts ESXi son subordinados (hosts subordinados esclavos). Un maestro supervisa el estado de los subordinados para detectar a tiempo un fallo en el host e iniciar el reinicio de las máquinas virtuales averiadas. El host maestro también supervisa el estado de energía de las máquinas virtuales en los nodos del clúster. Si se detecta un fallo en la máquina virtual, el maestro inicia un reinicio de la máquina virtual (el maestro selecciona el host óptimo antes de reiniciar la máquina virtual que ha fallado). El maestro de HA envía información sobre el estado del clúster de HA a vCenter. VMware vCenter gestiona el clúster utilizando la interfaz proporcionada por el host maestro de HA.
El maestro puede ejecutar máquinas virtuales al igual que otros hosts del clúster. Si falla un host maestro, se selecciona otro host maestro. El host que esté conectado al mayor número de almacenes de datos tiene ventaja en la elección del host ESXi primario. Los hosts que no están en modo de mantenimiento participan en la elección del host primario.
Los hosts subordinados pueden ejecutar máquinas virtuales, supervisar los estados de las máquinas virtuales y enviar información actualizada sobre los estados de las máquinas virtuales al host maestro de HA.
Fault Domain Manager (FDM) es el nombre del agente utilizado para supervisar la disponibilidad de los servidores físicos. El agente FDM funciona en cada host ESXi dentro de un clúster de HA.
Tipos de fallo del host
Hay tres tipos de fallos de host ESXi:
Fallo. Un host ESXi ha dejado de funcionar por algún motivo.
Aislamiento. Un host ESXi y las máquinas virtuales en este host siguen funcionando, pero el host está aislado de otros hosts en el clúster debido a problemas de red.
Partición. Se pierde la conectividad de red con el host primario.
Cómo se detectan los fallos
Los latidos se intercambian para detectar fallos en un clúster de HA de vSphere. El host primario supervisa el estado de los hosts secundarios recibiendo latidos del corazón de los hosts secundarios cada segundo. El host primario envía pings ICMP al host secundario y espera las respuestas. Si el host primario no puede comunicarse directamente con el agente del host secundario, el host secundario puede estar sano o fallar pero ser inaccesible a través de la red.
Si el host primario no recibe heartbeats, entonces el host primario comprueba el host sospechoso mediante Datastore Heartbeating. Durante el funcionamiento normal, cada host de un clúster de HA intercambia latidos con el almacén de datos compartido. El host ESXi primario comprueba si se han intercambiado los latidos del almacén de datos con el host sospechoso, además de enviar pings a dicho host. Si no hay intercambio de heartbeat de almacén de datos con el host sospechoso, y ese host no envía peticiones ICMP, entonces el host se designa como host fallido.
Nota: Se crea un directorio especial .vSphere-HA en la raíz de un almacén de datos compartido para el heartbeating y la identificación de una lista de máquinas virtuales protegidas. Tenga en cuenta que los almacenes de datos vSAN no se pueden utilizar para el heartbeating de almacenes de datos.
Si el host primario no puede conectarse con el agente del host secundario, pero éste intercambia latidos con el almacén de datos compartido, el host primario marca al host sospechoso como host aislado de la red. Si el host primario determina que el host secundario se está ejecutando en un segmento de red aislado, el host primario continúa supervisando las máquinas virtuales en ese host aislado. Si las máquinas virtuales del host aislado se apagan, el host primario inicia el reinicio de estas máquinas virtuales en otro host ESXi. Puede configurar la respuesta del clúster vSphere HA cuando un host ESXi queda aislado de la red.
Supervisión de máquinas virtuales individuales. VMware vSphere High Availability dispone de un mecanismo para la supervisión de máquinas virtuales individuales y la detección de fallos de una máquina virtual concreta. Las herramientas VMware Tools instaladas en un sistema operativo invitado (SO) se utilizan para determinar el estado de la máquina virtual. VMware Tools envía los latidos del sistema operativo invitado al host ESXi.
Los latidos y la actividad de entrada/salida (E/S) generados por VMware Tools son supervisados por el servicio de supervisión de máquinas virtuales. Si el host ESXi principal del clúster de HA detecta que VMware Tools en la máquina virtual protegida no responde y que no hay actividad de E/S, el host inicia un reinicio de la máquina virtual. La supervisión de la actividad de E/S de las máquinas virtuales permite a un clúster de HA evitar reinicios innecesarios de las máquinas virtuales si VMware Tools no envía heartbeats por algún motivo pero la máquina virtual está en ejecución. Puede establecer la sensibilidad de supervisión para configurar el periodo de tiempo tras el cual debe reiniciarse una máquina virtual si el host ESXi no recibe los latidos del sistema operativo invitado generados por VMware Tools. VMware vSphere HA reinicia la máquina virtual en el mismo host ESXi en caso de fallo de una sola máquina virtual.
Los heartbeats de VMware Tools se envían a hostd a nivel de hipervisor (ESXi), no utilizando la pila de red. A continuación, el host ESXi envía la información recibida a vCenter. Los latidos de VMware Tools pueden ser recibidos por un host ESXi si una VM está desconectada de una red e incluso si no hay ningún adaptador de red virtual conectado a la VM.
Supervisión de máquinas virtuales y aplicaciones. Puede utilizar SDK de un proveedor externo para supervisar si una aplicación específica instalada en una VM ha fallado. La opción alternativa es utilizar una aplicación que ya sea compatible con la supervisión de aplicaciones de VMware. Los latidos de aplicación se utilizan para la supervisión de aplicaciones en máquinas virtuales de VMware que se ejecutan en un clúster de HA de vSphere.
Parámetros clave para la configuración de clústeres de HA
Antes de empezar a configurar un clúster de HA, es necesario definir algunos parámetros clave.
La respuesta de aislamiento es un parámetro que define cómo actúa un host ESXi cuando no recibe señales de heartbeat. Las opciones son Dejar encendido, Apagar (por defecto) y Apagar.
La reserva es un parámetro que se calcula en función de las características máximas de la máquina virtual más necesitada de recursos dentro de un clúster. Este parámetro se utiliza para estimar la capacidad de conmutación por recuperación. Un clúster de HA crea ranuras de reserva utilizando el valor del parámetro Reserva.
Capacidad de conmutación por recuperación. Este parámetro se mide en números enteros y define el número máximo de servidores que pueden fallar en el clúster sin un impacto negativo en las cargas de trabajo (el clúster y todas las máquinas virtuales pueden seguir funcionando tras el fallo de este número de hosts ESXi).
El número de fallos de host permitidos. Este parámetro lo define un administrador del sistema para establecer cuántos hosts pueden fallar para continuar el funcionamiento del clúster. La capacidad de conmutación por recuperación se tiene en cuenta al establecer el valor de este parámetro.
Admission Control es el parámetro utilizado para garantizar que haya suficientes recursos reservados para recuperar las máquinas virtuales después de que falle un host ESXi. Este parámetro es establecido por un administrador y define el comportamiento de las VMs si no hay suficientes ranuras libres para arrancar VMs tras fallos del host ESXi. Admission Control define la capacidad de conmutación por recuperación, es decir, el porcentaje de degradación de recursos que se puede tolerar en un clúster de HA de vSphere tras la conmutación por recuperación.
La prioridad de reinicio la establece un administrador para definir la secuencia de inicio de las máquinas virtuales tras la conmutación por recuperación de un nodo del clúster. Los administradores pueden configurar vSphere HA para que inicie primero las máquinas virtuales críticas y, a continuación, inicie otras máquinas virtuales.
Capacidad de conmutación por recuperación y fallo de host
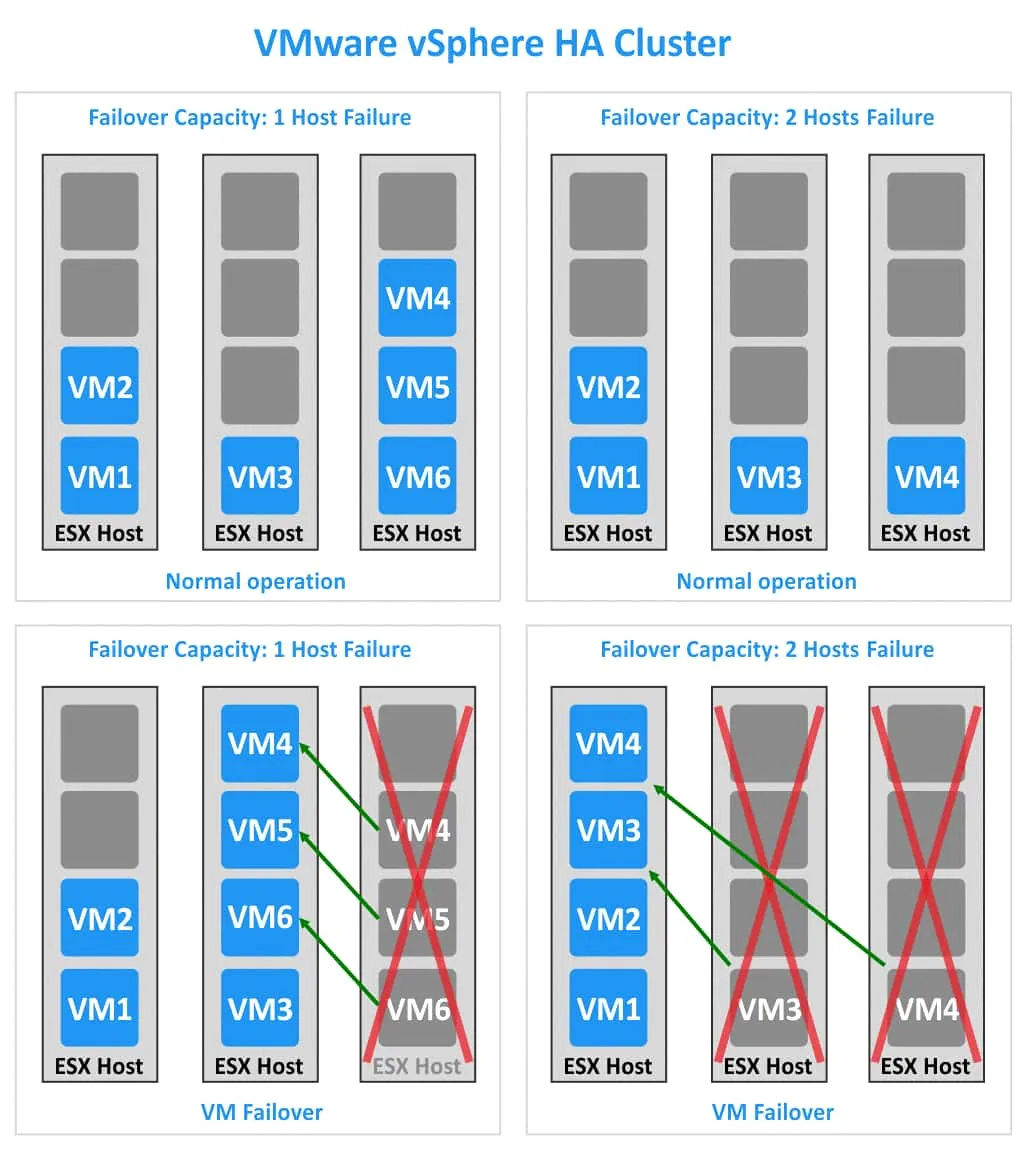
Veamos dos casos, cada uno con tres hosts ESXi pero con diferentes valores de capacidad de conmutación por recuperación. En el primer caso, el clúster de HA puede funcionar tras el fallo de un host ESXi (véase la parte izquierda de la imagen siguiente). En el segundo caso, el clúster de HA puede tolerar el fallo de dos hosts ESXi (véase la parte derecha de la imagen).
1. Cada host ESXi tiene 4 ranuras. Hay 6 máquinas virtuales en el clúster. Si falla un host ESXi (el tercer host, por ejemplo), las tres máquinas virtuales (VM4, VM5 y VM6) pueden migrar a los otros dos hosts ESXi. En mi ejemplo, estas tres máquinas virtuales están migrando al segundo host ESXi. Si falla un host ESXi más, no habrá ranuras libres para migrar y ejecutar otras máquinas virtuales.
2. Cada host ESXi tiene 4 ranuras. En el clúster VMware vSphere HA se ejecutan 4 máquinas virtuales. En este caso, hay suficientes ranuras para ejecutar todas las máquinas virtuales de un clúster si fallan dos hosts ESXi.
Para calcular la capacidad de conmutación por recuperación, haga lo siguiente: Del número de todos los nodos del clúster reste la relación entre el número de máquinas virtuales del clúster y el número de ranuras de un nodo. Si el resultado no es un número entero (un número que no es entero), redondee el número al entero más cercano. Calculemos la capacidad de conmutación por recuperación de los dos ejemplos.
Ejemplo 1:
3-6/4=1,5
Redondea 1,5 a 1. Todas las máquinas virtuales de un clúster de HA pueden sobrevivir si falla un host ESXi.
Ejemplo 2:
3-4/4=2
No es necesario redondear hacia abajo, ya que 2 es un número entero. Todas las máquinas virtuales pueden seguir funcionando si fallan 2 hosts ESXi.
Control de admisión
Como se mencionó anteriormente, el control de admisión es el parámetro necesario para garantizar que haya suficientes recursos para ejecutar máquinas virtuales después de un fallo de host en el clúster. También puede definir el parámetro Estado de Control de Admisión para mayor comodidad. El estado de control de admisión se calcula como la relación entre la capacidad de conmutación por recuperación y el número de fallos de host permitidos (NHF).
Si la capacidad de conmutación por recuperación es superior al NHF, el clúster de HA está configurado correctamente. De lo contrario, deberá configurar el Control de Admisión manualmente. Hay dos opciones disponibles:
1. No encienda las máquinas virtuales si infringen las restricciones de disponibilidad (no encienda las máquinas virtuales si no hay suficientes recursos de hardware).
2. Permitir que las máquinas virtuales se inicien incluso si violan la disponibilidad (iniciar las máquinas virtuales a pesar de la falta de recursos de hardware).
Elija la opción que mejor se adapte a su caso de uso práctico del clúster de alta disponibilidad de vSphere. Si su objetivo es la fiabilidad del clúster de HA, seleccione la primera opción(No encender las máquinas virtuales). Si lo más importante para usted es ejecutar todas las máquinas virtuales, seleccione la segunda opción(Permitir que se inicien las máquinas virtuales). Ten en cuenta que en el segundo caso el comportamiento del clúster puede ser impredecible. En el peor de los casos, el clúster de HA puede quedar inutilizado.
VM anula
VM overrides (o HA overrides en el caso de un clúster de HA) la opción que permite desactivar HA para una determinada VM que se ejecuta en el clúster de HA. Puede configurar su cluster vSphere HA a un nivel más granular con esta opción a nivel de cluster.
Tolerancia a fallos
VMware proporciona una función para un clúster vSphere HA que permite conseguir un tiempo de inactividad cero en caso de fallo de un host ESXi. Esta función se denomina Tolerancia a fallos. Mientras que la configuración estándar de vSphere High Availability requiere un reinicio de la máquina virtual en caso de fallo, Fault Tolerance permite que las máquinas virtuales sigan funcionando si falla el host ESXi principal en el que están registradas. La tolerancia a fallos puede utilizarse para máquinas virtuales de misión crítica que ejecuten aplicaciones críticas.
Existe la sobrecarga de lograr un tiempo de inactividad cero para el más alto nivel de continuidad de negocio porque hay dos instancias en ejecución de una VM protegida con Tolerancia a Fallos. La segunda VM fantasma se ejecuta en el segundo host ESXi, y todos los cambios de la VM original (CPU, RAM, estado de la red) se replican desde el host ESXi inicial al host ESXi secundario. La máquina virtual protegida se denomina máquina virtual primaria y la máquina virtual duplicada se denomina máquina virtual secundaria. Las máquinas virtuales primaria y secundaria deben residir en hosts ESXi diferentes para garantizar la protección contra fallos del host ESXi.
Las dos máquinas virtuales (la principal y la secundaria) se ejecutan simultáneamente y consumen recursos de CPU, RAM y red en ambos hosts ESXi (de este modo, una máquina virtual protegida con la función de tolerancia a fallos consume el doble de recursos en el clúster de HA de vSphere). Estas máquinas virtuales se sincronizan continuamente en tiempo real. Los usuarios sólo pueden trabajar con la VM primaria (original) y la VM secundaria (fantasma) es invisible para ellos.
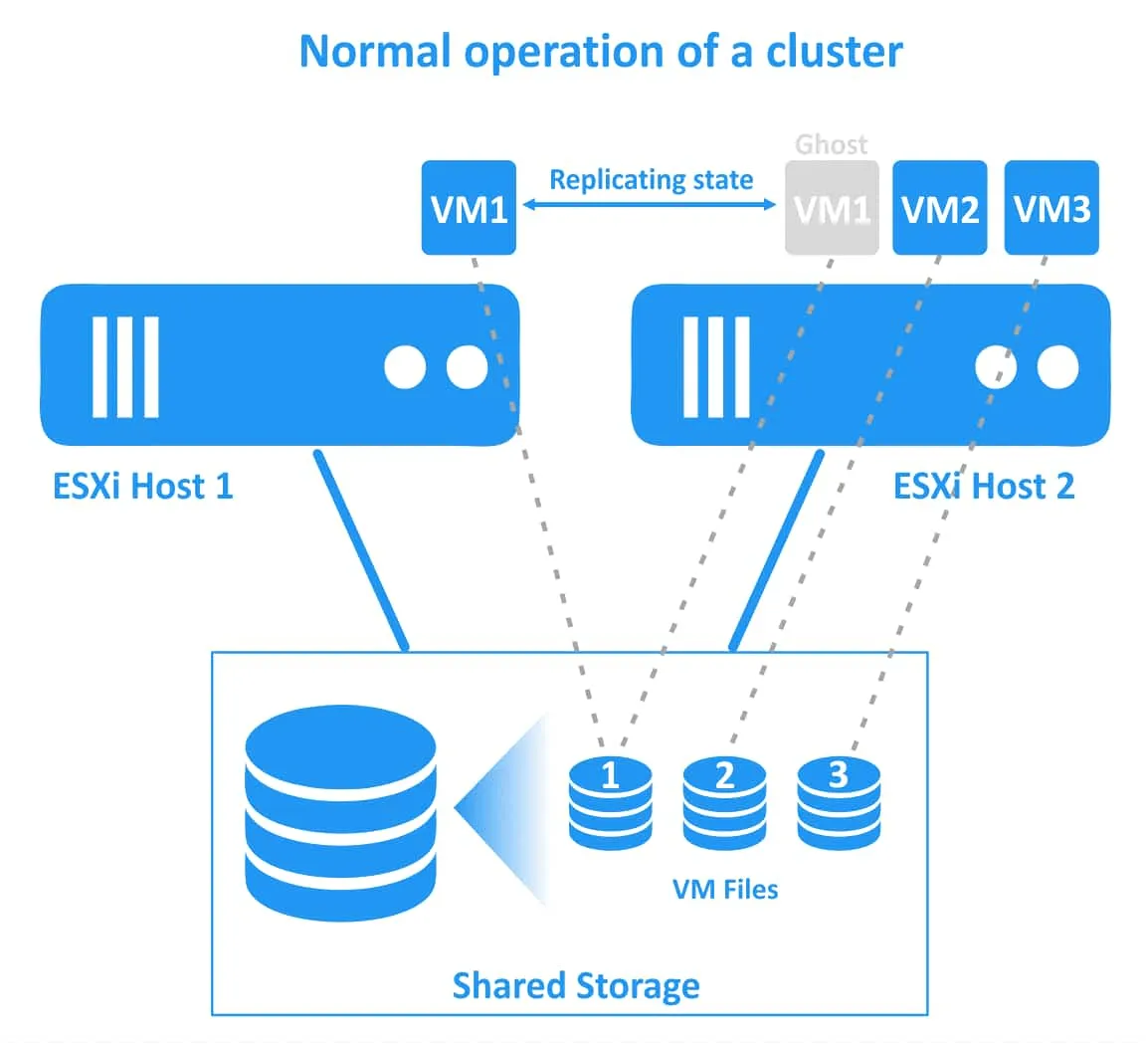
Si falla el primer host ESXi (el host en el que reside la máquina virtual principal), las cargas de trabajo se migran a la máquina virtual secundaria (es decir, el clon de la máquina virtual o la máquina virtual fantasma) que se ejecuta en el segundo host ESXi. La máquina virtual secundaria se activa y es accesible en un momento. Los usuarios pueden notar una ligera latencia de red durante el momento de la conmutación por error transparente. No hay interrupción del servicio ni pérdida de datos durante la conmutación por recuperación. Una vez que la conmutación por recuperación se ha realizado correctamente, se crea una nueva máquina virtual fantasma en el host ESXi sano alternativo para proporcionar redundancia y continuar con la protección de la máquina virtual contra fallos del host ESXi.
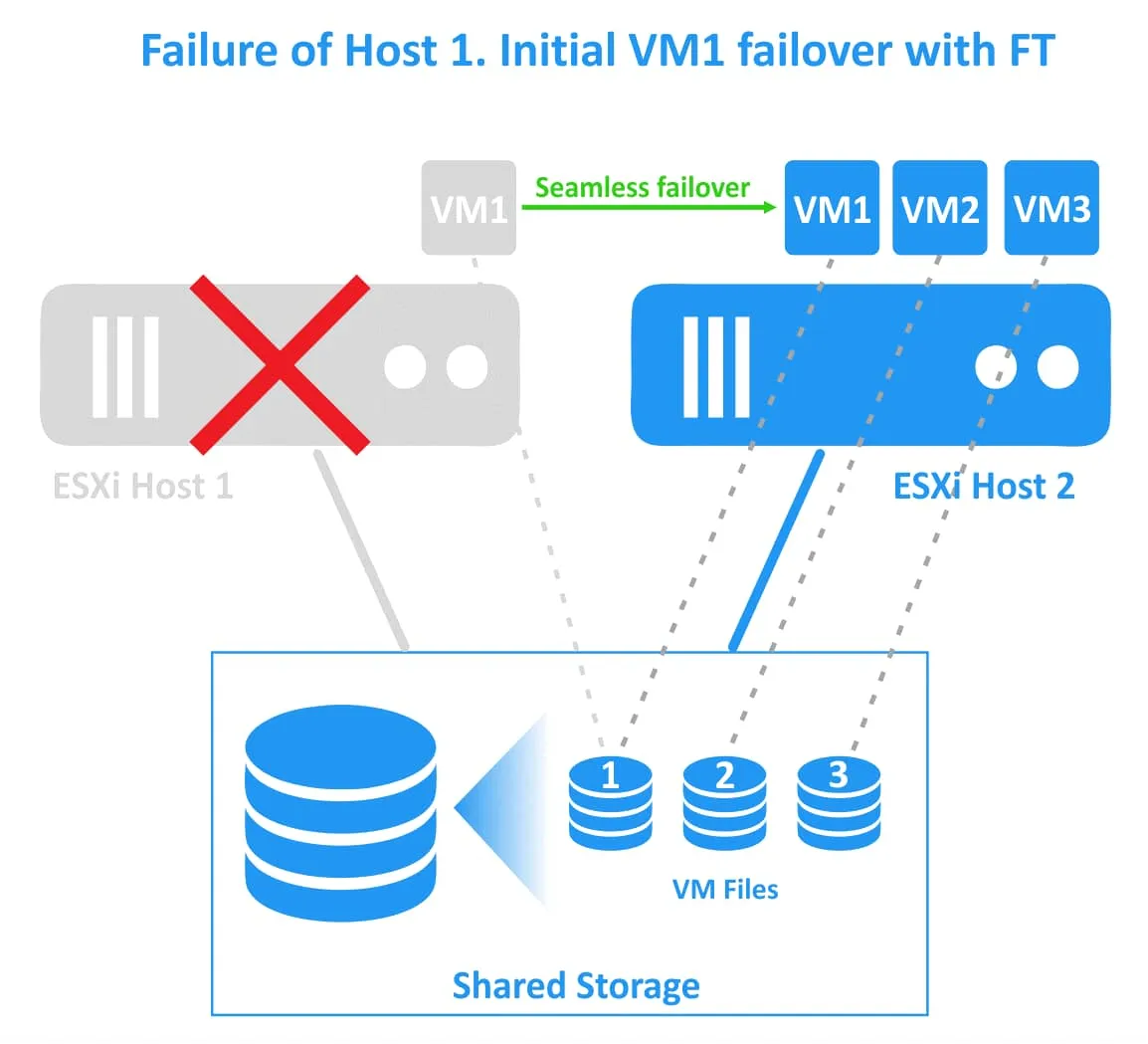
La tolerancia a fallos evita los escenarios de cerebro dividido (cuando dos copias activas de una máquina virtual protegida se ejecutan simultáneamente) gracias al mecanismo de bloqueo de archivos en el almacenamiento compartido para la coordinación de la conmutación por error. Sin embargo, la tolerancia a fallos no protege contra fallos de software dentro de una máquina virtual (como fallos del sistema operativo invitado o fallos de aplicaciones concretas). Si falla una máquina virtual primaria, también falla la secundaria.
Requisitos para la tolerancia a fallos
- Un clúster vSphere HA con un mínimo de dos hosts ESXi.
- Registro de vMotion y FT.
- Una CPU compatible que soporte virtualización MMU asistida por hardware.
Se recomienda utilizar una red de tolerancia a fallos dedicada en el clúster de HA de vSphere.
Una licencia para la tolerancia a fallos
- Los hosts ESXi deben tener licencia para utilizar la tolerancia a fallos.
- vSphere Standard y Enterprise admiten hasta 2 vCPU para una única máquina virtual.
- vSphere Enterprise Plus permite utilizar hasta 8 vCPUs por VM.
Limitaciones de Fault Tolerance
Existen algunas limitaciones en el uso de VMware Fault Tolerance en vSphere. Funciones de VMware vSphere incompatibles con FT:
- Instantáneas de máquinas virtuales. Una máquina virtual protegida no debe tener instantáneas.
- Clones vinculados
- Almacenes de datos VMware vVol
Dispositivos no compatibles:
- Dispositivos de asignación de dispositivos en bruto
- CD-ROM físico y otros dispositivos de un servidor que están conectados a una máquina virtual como dispositivos virtuales.
- Dispositivos de sonido y USB
- Discos virtuales VMDK de tamaño superior a 2 TB
- Dispositivos de vídeo con gráficos 3D
- Puertos paralelo y serie
- Dispositivos de conexión en caliente
- Paso de NIC (controlador de interfaz de red)
- Storage vMotion (debe desactivarse temporalmente para migrar los archivos de la máquina virtual a otro almacenamiento)
¿Qué es DRS en VMware vSphere?
Distributed Resource Scheduler (DRS) es una función de clustering de VMware vSphere que permite equilibrar la carga de las máquinas virtuales que se ejecutan en el cluster. DRS comprueba la carga de máquinas virtuales y una carga de servidores ESXi dentro de un clúster vSphere. Si DRS detecta que hay un host o una VM sobrecargados, DRS migra la VM a un host ESXi con suficientes recursos de hardware libres para garantizar la calidad del servicio (QoS). DRS puede seleccionar el host ESXi óptimo para una máquina virtual cuando se crea una nueva máquina virtual en el clúster.
VMware DRS le permite ejecutar máquinas virtuales en un clúster equilibrado y evitar la sobrecarga y las situaciones en las que no hay suficientes recursos de hardware para las máquinas virtuales y las aplicaciones que se ejecutan en las máquinas virtuales para un funcionamiento normal (en este caso, debe haber suficientes recursos en todo el clúster).
Requisitos del DRS
Los requisitos para DRS, junto con los requisitos generales para un clúster vSphere, incluyen:
- Licencia vSphere Enterprise o vSphere Enterprise Plus
- Una CPU con compatibilidad vMotion mejorada para la migración en vivo de máquinas virtuales con vMotion
- Una red vMotion dedicada
Se requiere un VMware vMotion configurado para operar un cluster DRS, a diferencia de un cluster HA, donde vMotion sólo es necesario si se utiliza Tolerancia a Fallos. Además, la licencia de vSphere necesaria para VMware DRS es mayor que la licencia para utilizar vSphere High Availability.
El papel de vMotion
Migrar máquinas virtuales de un host ESXi a otro con vMotion, que mencionamos al explicar cómo funciona la tolerancia a fallos. Con VMware vMotion, la migración de máquinas virtuales (CPU, memoria, estado de red) se produce sin interrumpir las máquinas virtuales en ejecución (no hay tiempo de inactividad). VMware vMotion es la función clave para el correcto funcionamiento de DRS.
Veamos los pasos principales de la operación vMotion:
1. vMotion crea una VM sombra en el host ESXi de destino. El host ESXi de destino preasigna recursos suficientes para la máquina virtual que se va a migrar. La VM se pone en estado intermedio y la configuración de la VM no se puede cambiar durante la migración.
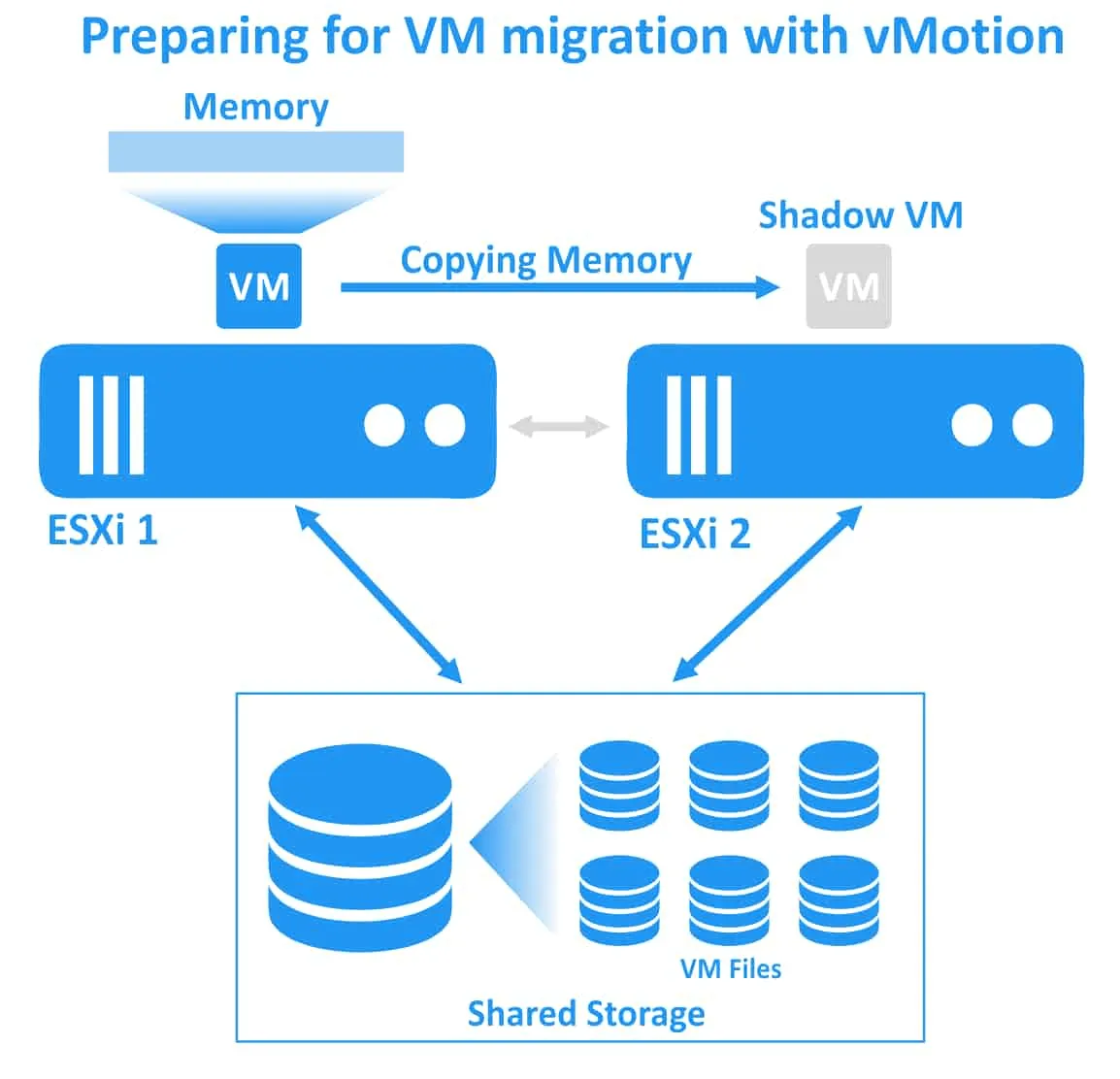
2. El proceso de precopia. Cada página de memoria de la VM se copia del origen al destino utilizando una red vMotion.
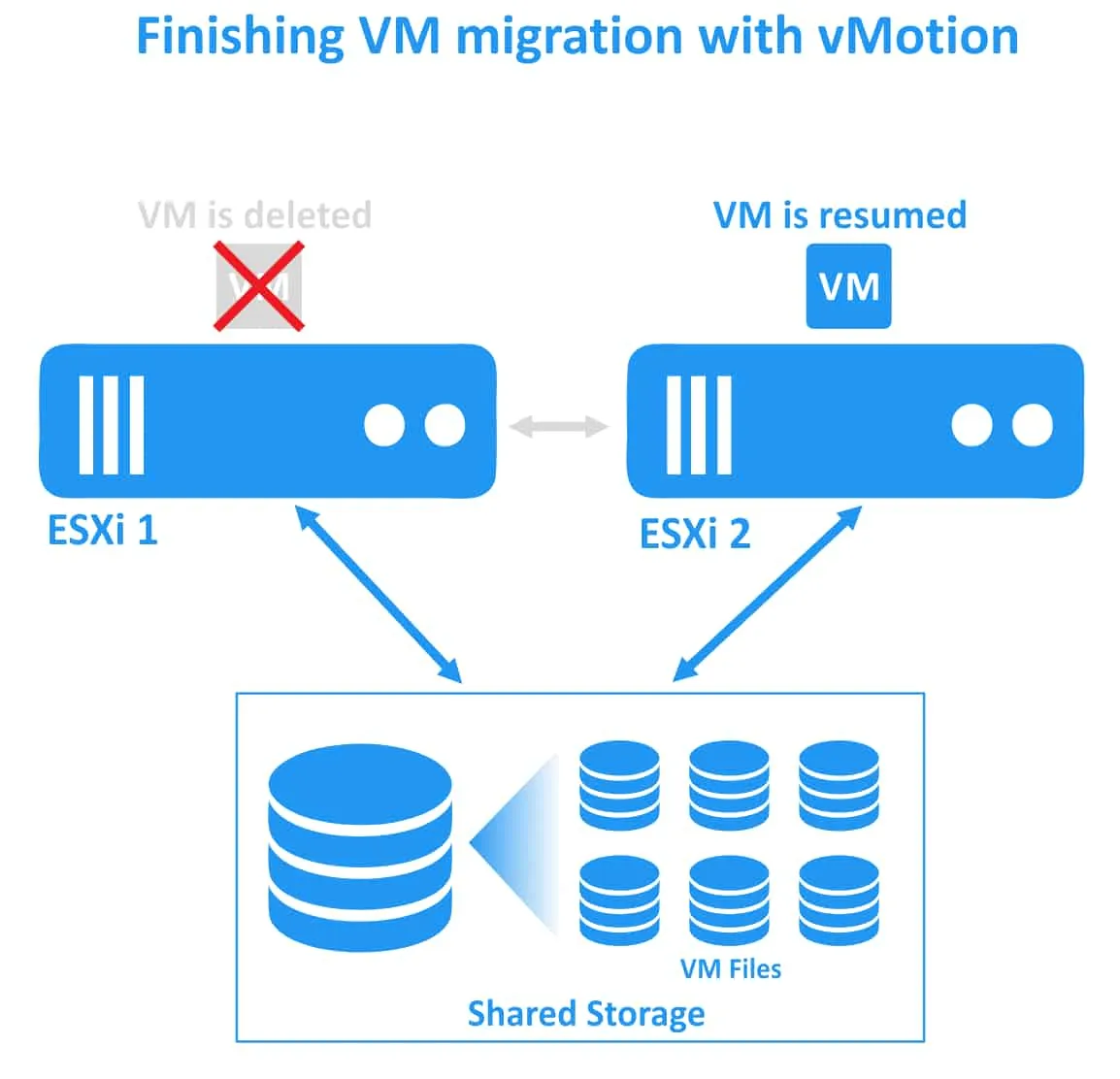
3. Se realiza la siguiente pasada de copia de páginas de memoria del origen al destino, ya que las páginas de memoria se están cambiando durante la operación de la máquina virtual. Se trata de un proceso iterativo que se realiza hasta que no quedan páginas de memoria modificadas. Las páginas de memoria modificadas se denominan páginas sucias. La migración de máquinas virtuales con vMotion tarda más tiempo si se realizan operaciones de uso intensivo de memoria en una máquina virtual, ya que se cambian más páginas de memoria.

4. La máquina virtual se detiene en el host ESXi de origen y se reanuda en el host de destino. En este momento se puede notar una latencia de red insignificante dentro de la máquina virtual migrada durante aproximadamente un segundo.
Principio de funcionamiento de DRS en VMware
VMware DRS comprueba las cargas de trabajo desde las perspectivas de CPU y RAM para determinar el equilibrio del clúster de vSphere cada 5 minutos, que es el intervalo predeterminado. VMware DRS comprueba todos los recursos del pool de recursos del cluster, incluyendo los recursos consumidos por las VMs y los recursos de cada host ESXi dentro del cluster que pueden ser proporcionados para ejecutar VMs. Las comprobaciones de recursos se realizan de acuerdo con las políticas configuradas.
También se tienen en cuenta las demandas de las máquinas virtuales (los recursos de hardware que la máquina virtual necesita para funcionar en el momento de la comprobación). La fórmula se utiliza para el cálculo de la demanda de VM para la memoria:
Demanda de memoria VM = Función(Memoria activa utilizada, Intercambiada, Compartida) + 25% (memoria consumida inactiva)
La demanda de CPU se calcula en función del número de recursos de procesador que consume actualmente una VM. Los valores máximos de CPU de VM y los valores medios de CPU de VM recopilados durante la última comprobación ayudan al DRS a determinar la tendencia de uso de recursos para una VM concreta. Si vSphere DRS detecta un desequilibrio en el clúster y que algunos hosts ESXi están sobrecargados, entonces el DRS inicia la migración en vivo de las máquinas virtuales que se ejecutan en el host sobrecargado a un host con recursos libres.
Veamos cómo funciona vSphere DRS en VMware mediante un ejemplo con diagramas. En el siguiente diagrama, puede ver un clúster DRS con 3 hosts ESXi. Todos los hosts están conectados a un almacenamiento compartido, donde se encuentran los archivos de las máquinas virtuales. El primer host está muy cargado, el segundo tiene recursos de CPU y memoria libres y el tercero está muy cargado. Algunas VMs en el primer (VM1) y tercer (VM4, VM5) hosts ESXi están consumiendo casi todos los recursos de CPU y memoria provisionados. En este caso, el rendimiento de estas máquinas virtuales puede degradarse.
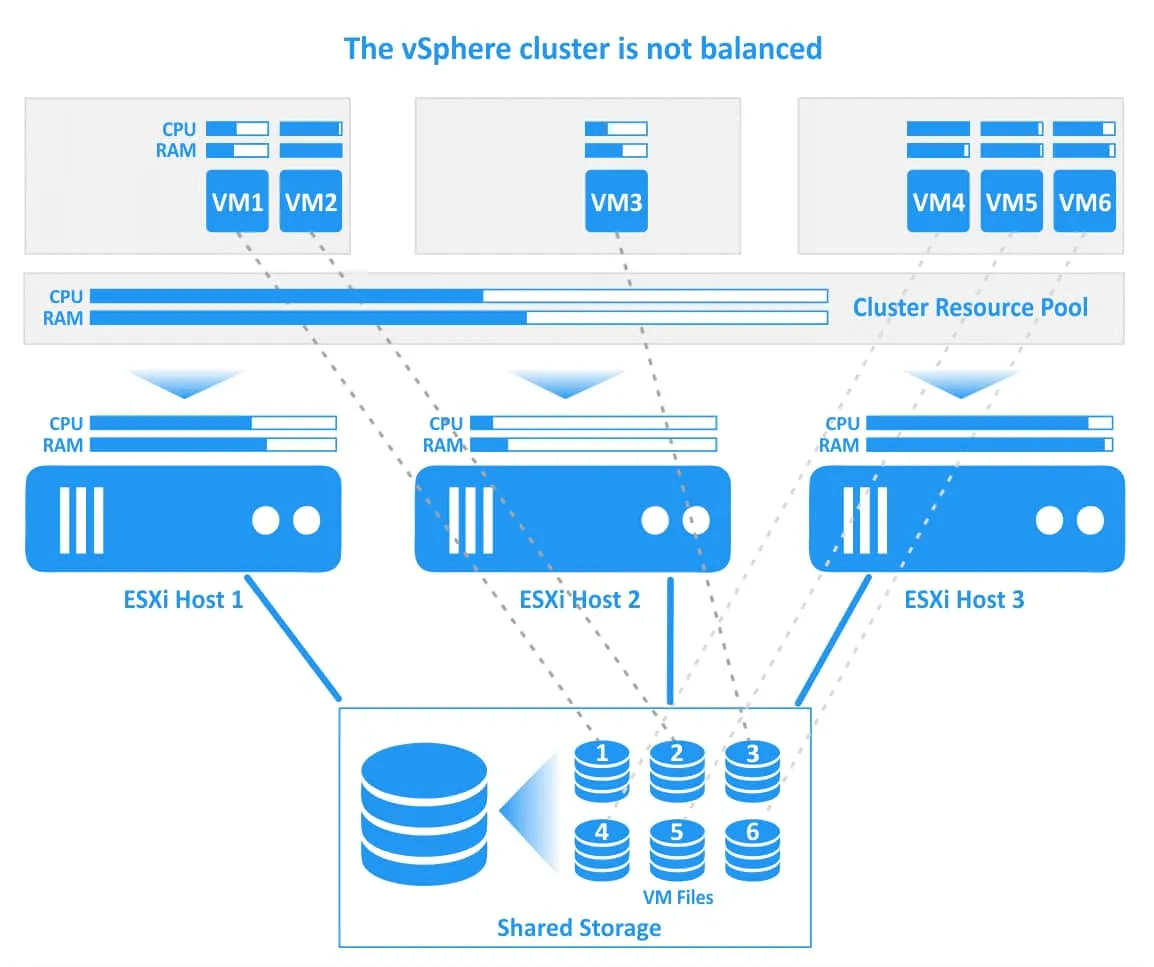
VMware DRS determina que la acción racional es migrar la VM2 muy cargada del host ESXi 1 sobrecargado al host ESXi 2, que tiene suficientes recursos libres, y migrar la VM4 del host ESXi 3 al host ESXi 2. Si el DRS está configurado para funcionar en modo automático, las máquinas virtuales en ejecución se migran con vMotion (esta acción se ilustra con flechas verdes en la imagen siguiente). Los archivos de las máquinas virtuales, incluidos los discos virtuales (VMDK), los archivos de configuración (VMX) y otros archivos, se ubican en el mismo lugar del almacenamiento compartido durante la migración de las máquinas virtuales y después de ésta (las conexiones de las máquinas virtuales y sus archivos se ilustran con líneas de puntos en la imagen).
Una vez migradas las máquinas virtuales seleccionadas, el clúster DRS se equilibra. Hay recursos libres en cada host ESXi dentro del clúster para ejecutar las máquinas virtuales de forma eficaz y garantizar un alto rendimiento.
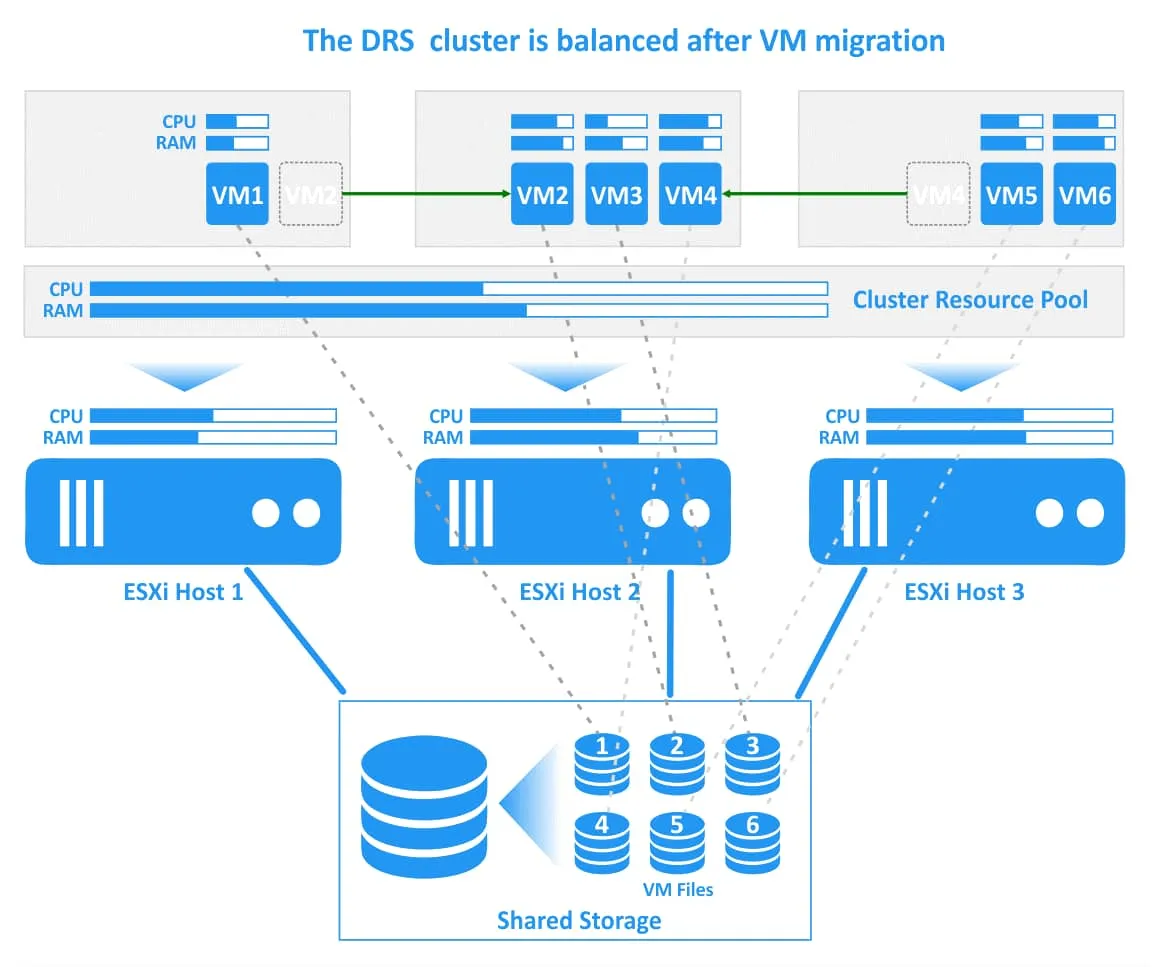
La situación puede cambiar debido a cargas de trabajo de máquinas virtuales desiguales, y el clúster puede volver a desequilibrarse. En este caso, DRS comprobará los recursos consumidos y los recursos libres en el clúster para iniciar de nuevo la migración de máquinas virtuales.
Parámetros clave para la configuración de vSphere DRS
VMware vSphere DRS es una función de clustering altamente personalizable que permite utilizar DRS con mayor eficacia en diferentes situaciones. Veamos los principales parámetros que afectan al comportamiento de DRS en un clúster vSphere.
Niveles de automatización de VMware DRS
Cuando DRS detecta que un cluster vSphere está desequilibrado, DRS proporciona recomendaciones para la colocación y migración de VM con vMotion. La recomendación puede aplicarse utilizando uno de los tres niveles de automatización:
Totalmente automatizado. Las recomendaciones iniciales de colocación de VM y vMotion son aplicadas automáticamente por DRS (no es necesaria la intervención del usuario).
Parcialmente automatizado. Las recomendaciones para la colocación inicial de nuevas máquinas virtuales son las únicas que se aplican automáticamente. Otras recomendaciones pueden iniciarse y aplicarse manualmente o ignorarse.
Manual. DRS proporciona recomendaciones para la colocación inicial y la migración de máquinas virtuales, pero se requiere la interacción del usuario para aplicar estas recomendaciones. También puede ignorar las recomendaciones proporcionadas por DRS.
Niveles de agresión DRS (umbrales de migración)
Niveles de agresión DRS o umbrales de migración es la opción para controlar el nivel máximo de desequilibrio que es aceptable para un cluster DRS. Hay cinco valores de umbral, desde 1, el más conservador, hasta 5, el más agresivo.
El ajuste agresivo inicia la migración de máquinas virtuales incluso si el beneficio de la colocación de máquinas virtuales es escaso. La configuración conservadora no inicia la migración de la máquina virtual aunque se puedan obtener beneficios significativos tras la migración de la máquina virtual. El nivel 3, el nivel medio de agresión, está seleccionado por defecto y es el recomendado.
Reglas de afinidad en VMware DRS
Las reglas de afinidad y antiafinidad son útiles cuando necesita colocar máquinas virtuales específicas en hosts ESXi específicos. Por ejemplo, puede que necesite ejecutar algunas máquinas virtuales juntas en un host ESXi dentro de un clúster, o viceversa (necesita que dos o más máquinas virtuales se coloquen sólo en hosts ESXi diferentes, y que las máquinas virtuales no se coloquen en un host). Los casos prácticos pueden ser:
- VMs de controlador de dominio virtual (un controlador de dominio primario y un controlador de dominio adicional) en diferentes hosts para evitar el fallo de ambas VMs si uno de los hosts falla. En este caso, estas máquinas virtuales no deben ejecutarse juntas en un único host ESXi.
- Máquinas virtuales que ejecutan software con licencia para ejecutarse en el hardware adecuado y que no pueden ejecutarse en otros ordenadores físicos debido a limitaciones de licencia (por ejemplo, Oracle Database).
Las normas de afinidad se dividen en:
- Reglas de afinidad VM-VM (para máquinas virtuales individuales)
- Reglas de afinidad VM-host (relación entre grupos de hosts y grupos de VMs)
Las reglas de alojamiento de máquinas virtuales pueden ser preferentes (las máquinas virtuales deben…) y obligatorias (las máquinas virtuales deben…). Las reglas obligatorias siguen funcionando incluso si DRS está desactivado, lo que no permite migrar manualmente las máquinas virtuales correspondientes con vMotion. Este principio se utiliza para evitar la violación de la regla aplicada a las máquinas virtuales que se ejecutan en hosts ESXi si vCenter no está disponible temporalmente o falla.
Existen cuatro opciones para las reglas de afinidad de DRS:
Mantener las máquinas virtuales juntas. Las máquinas virtuales seleccionadas deben ejecutarse juntas en un único host ESXi (si es necesaria la migración de máquinas virtuales, todas estas máquinas virtuales deben migrarse juntas). Esta regla puede utilizarse cuando se desea localizar el tráfico de red entre las máquinas virtuales seleccionadas (para evitar la sobrecarga de red entre hosts ESXi si las máquinas virtuales generan un tráfico de red significativo). Otro uso práctico es la ejecución de una aplicación compleja que utiliza componentes (que dependen unos de otros) instalados en varias máquinas virtuales o la ejecución de una vApp. Esto podría incluir, por ejemplo, un servidor de base de datos y un servidor de aplicaciones.
Máquinas virtuales separadas. Las máquinas virtuales seleccionadas no deben ejecutarse en un único host ESXi. Esta opción se utiliza con fines de alta disponibilidad.
Máquinas virtuales a hosts. Las máquinas virtuales añadidas a un grupo de máquinas virtuales deben ejecutarse en el host o grupo de hosts ESXi especificado. Es necesario configurar grupos DRS (grupos VM/Host). Un grupo DRS contiene varias máquinas virtuales o hosts ESXi.
Máquinas virtuales a máquinas virtuales. Esta regla puede seleccionarse para vincular máquinas virtuales a máquinas virtuales cuando desee encender un grupo de máquinas virtuales y, a continuación, encender otro grupo de máquinas virtuales (dependiente). Esta opción se utiliza cuando VMware HA y DRS están configurados juntos en el clúster.
En caso de conflicto, prevalecerá la norma más antigua.
Anulación de máquinas virtuales para VMware DRS
De forma similar al uso de VM override en un cluster vSphere HA, los VM overrides se utilizan para configuraciones más granulares de DRS en VMware vSphere y permiten anular ajustes globales establecidos a nivel de cluster DRS y definir ajustes específicos para una VM individual. Las demás máquinas virtuales del clúster no se ven afectadas cuando se aplica la anulación de una máquina virtual específica.
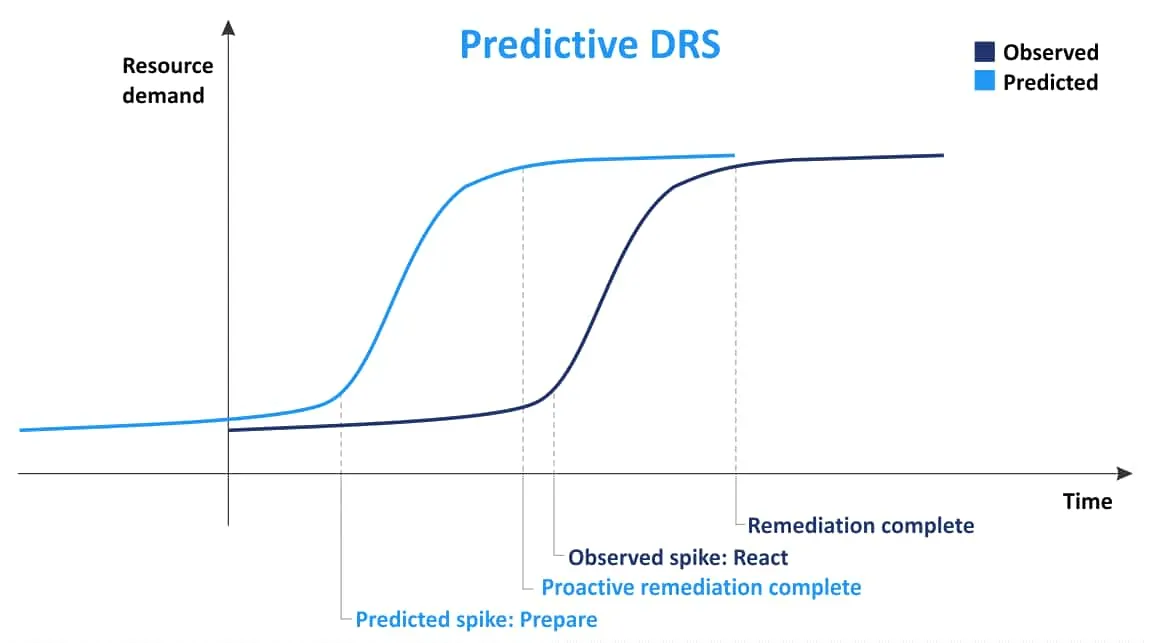
DRS predictivo
El concepto principal de DRS predictivo es recopilar información sobre la colocación de máquinas virtuales y, a continuación, basándose en la información recopilada previamente, predecir cuándo y dónde se producirá un uso elevado de recursos. Utilizando esta información, Predictive DRS puede mover máquinas virtuales entre hosts para un mejor equilibrio de la carga antes de que un servidor ESXi se sobrecargue y las máquinas virtuales carezcan de recursos. Esta función puede ser útil cuando se producen cambios en la demanda de máquinas virtuales en un clúster en función del tiempo. El DRS predictivo está desactivado por defecto. Se requiere VMware vRealize Operations Manager para utilizar Power DRS.
Gestor de energía distribuida
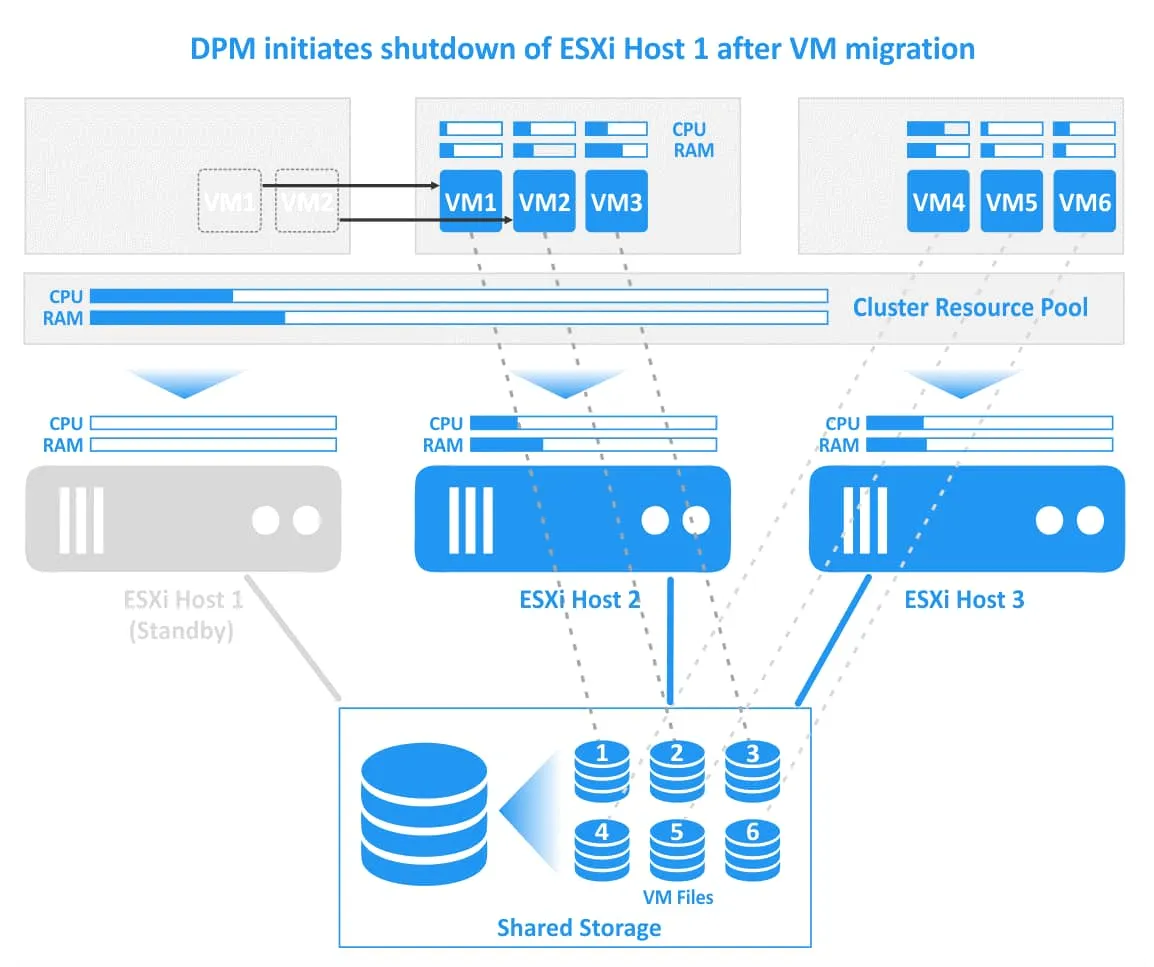
Distributed Power Manager (DPM) es una función utilizada para migrar máquinas virtuales si hay suficientes recursos libres en un clúster para apagar un host ESXi (poner un host en modo de espera) y ejecutar máquinas virtuales en los hosts ESXi restantes dentro del clúster (los hosts restantes deben proporcionar suficientes recursos para ejecutar las máquinas virtuales necesarias).
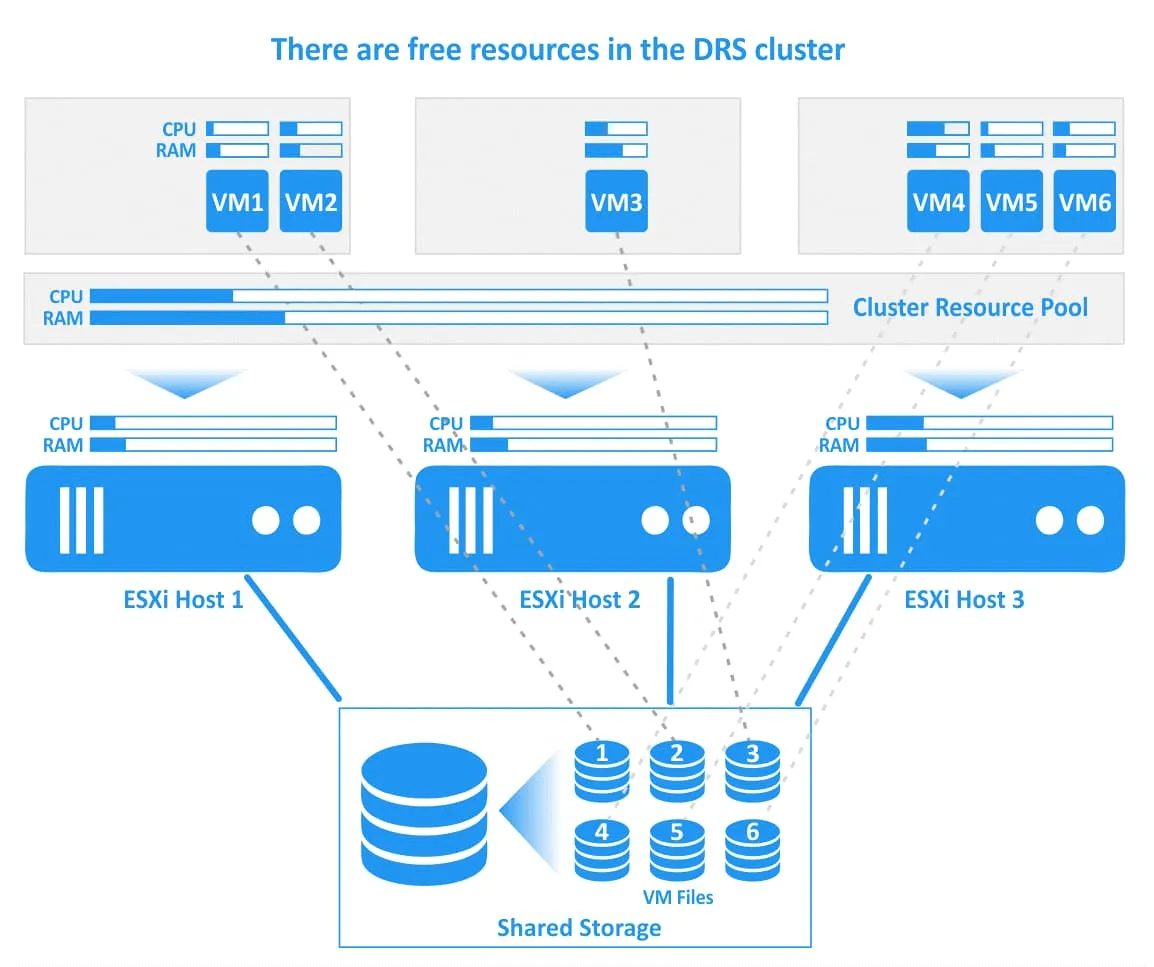
Cuando se necesitan más recursos en un clúster para ejecutar máquinas virtuales, DPM inicia un servidor que estaba apagado para que se despierte y funcione en modo normal. Uno de los protocolos de gestión de energía compatibles se utiliza para encender un host a través de la red. Estos protocolos son Intelligent Platform Management Interface (IPMI), Hewlett-Packard Integrated Lights-Out (iLO) o Wake-On-LAN (WOL). A continuación, DRS migra algunas máquinas virtuales a este servidor para distribuir las cargas de trabajo y equilibrar un clúster. Por defecto, la Gestión de Energía Distribuida está desactivada. Las recomendaciones de DPM pueden aplicarse automática o manualmente.
DRS de almacenamiento
Mientras que DRS migra las máquinas virtuales en función de los recursos informáticos de CPU y RAM, Storage DRS migra los archivos de las máquinas virtuales de un almacén de datos a otro en función del uso del almacén de datos, por ejemplo, el espacio libre en disco. Las reglas de afinidad y antiafinidad permiten configurar si Storage DRS debe almacenar los archivos de disco virtual de una máquina virtual juntos en el mismo almacén de datos. Por ejemplo, puede configurar la regla antiafinidad para almacenar los archivos VMDK de una máquina virtual que realice operaciones intensivas de E/S en distintos almacenes de datos. Esto se hace para evitar la degradación del rendimiento de la VM y del almacén de datos inicial de la VM (las cargas de trabajo de disco de E/S se distribuirán entre varios almacenes de datos cuando se utilice la regla antiafinidad).
Storage DRS es útil cuando se utilizan máquinas virtuales con discos thin provisioned en caso de sobreaprovisionamiento. Storage DRS ayuda a evitar situaciones en las que el tamaño de los discos delgados crece y, como resultado, no queda espacio libre en un almacén de datos. La falta de espacio libre provoca el fallo de las máquinas virtuales que almacenan discos virtuales en ese almacén de datos. Los archivos de disco de la máquina virtual se pueden migrar de un almacén de datos a otro con Storage vMotion mientras la máquina virtual se está ejecutando.
Supervisión del consumo de CPU y memoria
VMware ofrece la posibilidad de supervisar el uso de los recursos en la interfaz web de VMware vSphere Client. Puede supervisar el uso de la CPU en el clúster accediendo a Ajustes > Supervisión > vSphere DRS > CPU Utilization. También existen otras opciones para la supervisión de la memoria y el espacio de almacenamiento de hosts ESXi independientes. La supervisión de VMware es compatible con NAKIVO Backup & Replication 10.5. Más información sobre supervisión de infraestructuras en la entrada del blog.
Uso conjunto de VMware HA y DRS
VMware HA y DRS no son tecnologías competidoras. Se complementan entre sí, y puede utilizar tanto VMware DRS como HA en un clúster vSphere para proporcionar alta disponibilidad para las máquinas virtuales y equilibrar las cargas de trabajo si las máquinas virtuales son reiniciadas por HA en otros hosts ESXi. Se recomienda utilizar ambas tecnologías en clusters vSphere que se ejecuten en entornos de producción para la conmutación por error automática y el equilibrio de carga.
Cuando falla un host ESXi, HA inicia la conmutación por recuperación de las máquinas virtuales y éstas se reinician en otros hosts. La primera prioridad en esta situación es hacer que las máquinas virtuales estén disponibles. Pero después de la migración de máquinas virtuales, algunos hosts ESXi pueden sobrecargarse, lo que tendría un impacto negativo en las máquinas virtuales que se ejecutan en esos hosts. VMware DRS comprueba el uso de recursos en cada host dentro de un clúster y proporciona recomendaciones para la colocación más racional de las máquinas virtuales después de una conmutación por error. Como resultado, siempre puede estar seguro de que hay suficientes recursos para las máquinas virtuales después de la conmutación por recuperación para ejecutar cargas de trabajo con un rendimiento adecuado. Con VMware DRS y HA activados, puede tener un clúster más eficaz.
Conclusión
VMware proporciona las potentes funciones de los clústeres en vSphere para satisfacer las necesidades de los clientes de vSphere más exigentes. Cubrimos VMware DRS y HA y explicamos el principio de funcionamiento y los parámetros principales de cada una de estas funciones de clustering. VMware DRS y HA se complementan entre sí y hacen que el resultado final del uso de un clúster sea mejor.
Incluso si utiliza VMware DRS y HA, no olvide hacer backup de VMware VMs en vSphere. Descargue NAKIVO Backup & Replication Free Edition para hacer backup de VMware en su entorno.


