
Aprovisionamiento Thick y Thin: ¿Cuál es la diferencia?
En este artículo, vamos a considerar en detalle el aspecto de la asignación previa de almacenamiento de la configuración del disco virtual y descubrir qué es el aprovisionamiento thick y thin, en qué se diferencian y cuál de estos tipos de asignación previa de almacenamiento es mejor para su infraestructura.

Aprovisionamiento Thick
El aprovisionamiento thick es un tipo de asignación previa de almacenamiento. Con un aprovisionamiento thick, la cantidad completa de la capacidad de almacenamiento del disco virtual se asigna previamente en el almacenamiento físico cuando se crea el disco virtual. Un disco virtual de aprovisionamiento thick consume todo el espacio asignado en el almacén de datos desde el principio, por lo que el espacio no está disponible para otras máquinas virtuales.
Hay dos subtipos de discos virtuales de aprovisionamiento thick:
- Un disco Lazy zeroed es un disco que ocupa todo su espacio en el momento de su creación, pero este espacio puede contener algunos datos antiguos en el medio físico. Estos datos antiguos no se borran ni se sobrescriben, por lo que se deben «poner a cero» antes de que se puedan escribir nuevos datos en los bloques. Este tipo de disco se puede crear más rápidamente, pero su rendimiento será menor para las primeras escrituras debido al aumento de IOPS (operaciones de entrada / salida por segundo) para los nuevos bloques;
- Un disco Eager zeroed es un disco que obtiene todo el espacio requerido aún en el momento de su creación, y el espacio se borra de todos los datos anteriores en los medios físicos. La creación de discos eager zeroed lleva más tiempo, porque los ceros se escriben en todo el disco, pero su rendimiento es más rápido durante las primeras escrituras. Este subtipo de disco virtual de aprovisionamiento thick es compatible con las características de agrupación en clústeres, como la tolerancia a fallos

Por razones de seguridad de datos, eager zeroing es más común que lazy zeroing con discos virtuales de aprovisionamiento thick. ¿Por qué? Cuando elimina un VMDK, los datos en el almacén de datos no se borran totalmente; los bloques simplemente se marcan como disponibles, hasta que el sistema operativo los sobrescribe. Si crea un disco virtual eager zeroed en este almacén de datos, el área del disco se borrará totalmente (es decir, se pondrá a cero), lo que evitará que cualquier persona con malas intenciones pueda recuperar los datos anteriores, incluso si utiliza software especializado de terceros.
Provisionamiento Thin
El aprovisionamiento thin es otro tipo de asignación previa de almacenamiento. Un disco virtual de aprovisionamiento thin consume solo el espacio que necesita inicialmente y crece con el tiempo según la demanda.
Por ejemplo, si crea un nuevo disco virtual de 30 GB con aprovisionamiento thin y le copia 10 GB de archivos, el tamaño del archivo VMDK resultante será de 10 GB, mientras que tendría un archivo VMDK de 30GB si hubiera elegido usar un Disco de aprovisionamiento thick.
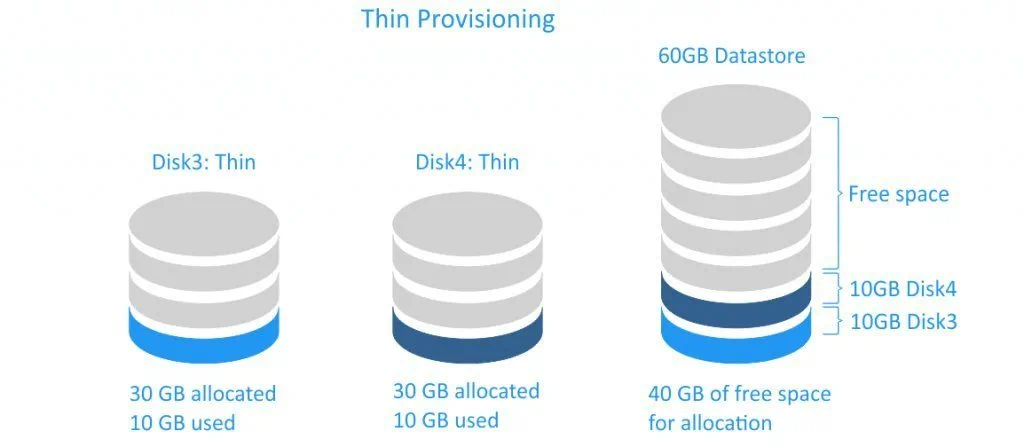
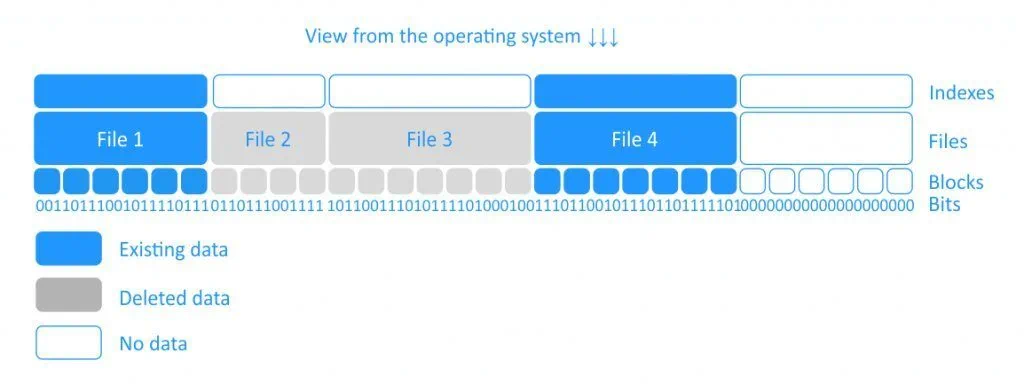
Los discos virtuales de aprovisionamiento thin son rápidos de crear y útiles para ahorrar espacio de almacenamiento. El rendimiento de un disco de aprovisionamiento thin no es mayor que el de un disco de aprovisionamiento thick con puesta a cero, ya que para ambos tipos de discos, los ceros deben escribirse antes de escribir datos en un nuevo bloque. Tenga en cuenta que cuando elimina sus datos de un disco virtual de aprovisionamiento thin, el tamaño del disco no se reduce automáticamente. Esto se debe a que el sistema operativo solo elimina los índices de la tabla de archivos que hacen referencia al cuerpo del archivo en el sistema de archivos; marca los bloques que pertenecían a archivos «eliminados» como libres y accesibles para que se escriban nuevos datos. Es por eso por lo que vemos la eliminación de archivos como instantánea. Si se tratara de una eliminación completa, donde se escribieron ceros sobre los bloques que ocupaban los archivos eliminados, llevaría aproximadamente la misma cantidad de tiempo que la copia de los archivos en cuestión. Vea la ilustración simplificada a continuación.
Problemas que pueden surgir al usar discos virtuales de aprovisionamiento Thin
El uso de discos virtuales de aprovisionamiento thin no siempre es ligero. Hay algunos problemas que debe conocer y estar preparado para enfrentar.
Descargue nuestro libro blanco gratuito: “Cómo calcular el objetivo de tiempo de recuperación y reducir los costos de tiempo de inactividad”
Consideremos un ejemplo que hace que las máquinas virtuales sean inutilizables. Por ejemplo, tenemos un almacén de datos de 20 GB con tres máquinas virtuales que se ejecutan en él. Cada máquina virtual tiene un conjunto de discos virtuales de aprovisionamiento thin con un tamaño máximo de 10 GB. (Esta práctica se denomina «exceso de aprovisionamiento»: asignamos a los discos virtuales más espacio del que pueden ocupar físicamente. Esto se hace a menudo, ya que le permite escalar el sistema agregando más almacenamiento físico según lo necesite). El tamaño del archivo de Cada disco virtual se expandirá a medida que se agreguen datos, hasta que no quede espacio libre en el almacén de datos. La situación se vuelve crítica cuando solo queda 1 GB de espacio libre en el almacén de datos, como cuando, por ejemplo, VM1 ocupa 8 GB, VM2 ocupa 7 GB y VM3 – 4 GB.
Los métodos regulares de eliminación de archivos dentro de las máquinas virtuales no ayudarán a reducir los discos virtuales de aprovisionamiento thin. Si se escribe más de 1 GB de datos nuevos en cualquiera de estas máquinas virtuales, las tres fallarán y deberá migrar una o más de las máquinas virtuales a otro almacén de datos para restaurar sus estados de funcionamiento.
Cómo reducir el tamaño del disco virtual de aprovisionamiento thin después de eliminar archivos
Para poder reducir el tamaño de archivo VMDK de sus discos virtuales de aprovisionamiento fino, debe saber cómo poner a cero los bloques que ocupaban los datos que eliminó anteriormente. Averigüemos cómo hacer eso.
NOTA: Las operaciones de reducción de disco solo son posibles si las máquinas virtuales no contienen instantáneas. Además, esté atento y ejecute los comandos bajo su propia responsabilidad. Realice siempre un respalo de todos sus datos importantes antes de realizar cualquier operación de disco. Para realizar un respaldo sus máquinas virtuales VMware y Hyper-V, use NAKIVO Backup & Replication.
Reducción de discos VMware con aprovisionamiento thin en Linux
Consideremos un ejemplo: tenemos un archivo VMDK de 10,266,496 KB (10 GB) (aprendimos sobre su tamaño yendo al directorio en el almacén de datos donde se encuentra nuestra máquina virtual) y queremos reducir el disco virtual en el que se encuentra el sistema operativo Linux invitado instalado. Podemos intentar eliminar archivos innecesarios en este disco virtual. Sin embargo, Linux no bloquea automáticamente los bloques después de eliminar archivos; Tendrás que hacerlo tú mismo. Puede hacerlo utilizando la utilidad dd (duplicador de datos) para copiar y convertir datos. Esta herramienta está disponible en todos los sistemas Linux.
NOTA: Antes de ejecutar la utilidad dd, es necesario asegurarse de que el almacén de datos tenga la capacidad suficiente para usarla (por ejemplo, para el servidor ESXi, puede verificar la capacidad de almacenamiento en la sección de almacenamiento del cliente vSphere; vaya a Configuration >> Storage).
Vamos a usar la utilidad dd.
- Primero, verificamos el espacio libre en una máquina virtual invitada de Linux usando el comando df –h:
root@test-virtual-machine:/# df –h
Obtenemos la siguiente salida en la consola:
Filesystem Size Used Avail Use% Mounted on udev 469M 0 469M 0% /dev tmpfs 99M 6,3M 92M 7% /run /dev/sda7 17G 8,8G 6,4G 58% / tmpfs 491M 116K 491M 1% /dev/shm tmpfs 5,0M 4,0K 5,0M 1% /run/lock tmpfs 491M 0 491M 0% /sys/fs/cgroup /dev/sda1 945M 121M 760M 14% /boot /dev/sda6 3,7G 13M 3,5G 1% /var/log tmpfs 99M 36K 99M 1% /run/user/1000
Podemos ver en esta salida que la partición / (root) contiene 8.8 GB de archivos.
- Vamos a eliminar algunos gigabytes de archivos innecesarios en la partición raíz. Esto es lo que vemos en la consola, si ejecutamos el comando df –h /:
Filesystem Size Used Avail Use% Mounted on /dev/sda7 17G 4,7G 11G 31% /
Por lo tanto, nuestra partición root ahora contiene 4.7 GB de archivos. Sin embargo, al ir al directorio donde se encuentra nuestro archivo VMDK, podemos ver que su tamaño todavía es de 10,266,496 KB (10 GB).
- Ahora vamos a llenar el espacio libre con ceros (en nuestro caso, llenaremos 10 GB de los 11 GB disponibles). Primero, escribimos cd seguido del nombre del directorio en el que está montada la partición que necesita ser puesta a cero (en nuestro caso es cd /, porque queremos navegar a la partición root). Después de eso, ejecutamos el siguiente comando, cambiando las variables para satisfacer nuestras necesidades:
dd bs=1M count=10240 if=/dev/zero of=zero
En este comando:
– dd puede ser solo ejecutado como super usuario.
– bs establece el tamaño del bloque (por ejemplo, bs = 1M le daría un tamaño de bloque de 1 Megabyte).
– count especifica el número de bloques que se copiarán (el valor predeterminado es que dd siga funcionando para siempre o hasta que se agote la entrada). En nuestro caso, 10,240 MB es la cantidad de espacio libre que queremos llenar con ceros, por lo que el número de bloques de 1 Megabyte es 10240.
– if significa «archivo de entrada». Aquí es donde debe indicar la fuente desde la que desea copiar los datos. En nuestro caso, es / dev / zero, un archivo especial (un pseudo-dispositivo) que proporciona tantos caracteres nulos como quiera leer.
– of significa «archivo de salida». Aquí es donde establece el destino donde desea escribir / pegar sus datos (en nuestro caso, el nombre del archivo es zero).
Después de ejecutar el comando anterior, el tamaño de nuestro archivo VMDK crece. Esta es la salida que vemos después del comando completado con éxito:
10240+0 records in 10240+0 records out 10737418240 bytes (10 GB) copied, 59,4348 s, 181 MB/s Command has been completed successfully.
Entonces, ahora el tamaño de nuestro archivo VMDK es de 11,321,856 KB (10.8 GB), lo que significa que se ha expandido. Además, si ejecutamos el comando df –h / nuevamente, veremos lo siguiente
Filesystem Size Used Avail Use% Mounted on /dev/sda7 17G 15G 569M 97% /
Esto significa que casi toda la partición root (es decir, 97%) está ocupada. Esto se debe a que hemos llenado la mayoría del espacio «disponible» con ceros. Ahora, nuestro disco virtual de aprovisionamiento delgado está listo para ser reducido.
NOTA: Para realizar la reducción, es necesario instalar VMware Tools.
- Para las máquinas virtuales que se ejecutan en VMware ESXi o VMware Workstation, ejecutamos los siguientes dos comandos en el sistema operativo invitado de Linux.
- Para asegurarnos de que la partición del disco esté disponible, ejecutamos el comando:
root@test-virtual-machine:/# vmware-toolbox-cmd disk list
Esta es la salida que vemos en nuestro caso (es decir, vemos la lista de particiones disponibles):
/ /boot /var/log
La partición root está presente, así que podemos proceder.
- Para reducir la partición, ejecutamos el siguiente comando:
root@test-virtual-machine:/# vmware-toolbox-cmd disk shrink /
Esta es la salida que vemos en nuestro caso:
Please disregard any warnings about disk space for the duration of shrink process. Progress: 100 [===========>] Disk shrinking complete.
Ahora, el tamaño de nuestro archivo VMDK reducido es de 5,323,456 KB (es decir, 5.08 GB, mucho menos que los 10.8 GB que tenía antes).
- Para asegurarnos de que la partición del disco esté disponible, ejecutamos el comando:
NOTA: Si su máquina virtual invitada se ejecuta en un servidor ESXi, después de llenar los espacios en blanco con ceros, puede seguir estos pasos:
- Apague la máquina virtual o desconecte el disco virtual que desea reducir.
- Conéctese al host ESXi con el cliente SSH.
- Navegue a la carpeta de la máquina virtual.
- Verifique el uso del disco con du -h.
- Ejecute vmkfstools -K test-virtual-machine.vmdk.
- Verifique el uso del disco con du -h una vez más.
La edición gratuita de NAKIVO Backup & Replication – La solución de protección de datos gratuita #1 que se puede instalar tanto en Linux como en Windows.
Reducción de discos VMware con aprovisionamiento thin en Windows
Al igual que Linux, Windows no bloquea automáticamente los bloques después de eliminar archivos. Para poder poner a cero el espacio libre de los discos de destino en su máquina virtual de Windows, debe descargar SDelete, una utilidad gratuita de la Suite Sysinternals de Microsoft, y descomprimir los archivos del archivo descargado en c:\program files\sdelete.
Luego sigue estos pasos:
- Ejecuta cmd.
- Vaya al directorio donde se encuentra SDelete. En nuestro caso, escd c:\program files\sdelete
- Para cada partición en la consola, use el comando sdelete –z. Esto es lo que tenemos en nuestro caso:
sdelete -z c: sdelete -z d:
Estos comandos pondrán a cero cualquier espacio libre en su disco de aprovisionamiento thin rellenando cualquier espacio no utilizado en las particiones especificadas.
Espera un par de minutos hasta que finalice el proceso. Su archivo VMDK se expandirá a su tamaño máximo durante el proceso.
- Asegúrese de que VMware Tools esté instalado en su máquina virtual de Windows. De forma predeterminada, las herramientas de VMware se instalan en c: \ archivos de programa \ vmware \ vmware tools \. Vaya a este directorio escribiendo: cd c: \ archivos de programa \ vmware \ vmware tools \.
- Para ver las particiones de disco disponibles, escriba:vmwaretoolboxcmd disk list
- Reduzca las particiones de disco que necesita. En nuestro caso, ejecutamos los comandos.:
vmwaretoolboxcmd disk shrink c:\ vmwaretoolboxcmd disk shrink d:\
Espera hasta que el programa haya terminado de reducir el disco.
Puede usar este método para máquinas virtuales que se ejecutan en VMware ESXi o VMware Workstation.
VMware Storage Distributed Resource Scheduler
Anteriormente, mencionamos una solución para reducir manualmente los discos de aprovisionamiento thin. Sin embargo, hay una forma más de administrar sus discos virtuales (tanto de aprovisionamiento thin como de aprovisionamiento thick), si usa un clúster de almacenamiento de datos en vSphere. VMware proporciona migración automática de disco virtual dentro del clúster del almacén de datos para evitar el desbordamiento del almacenamiento en disco donde se ubican los discos virtuales de aprovisionamiento thin y para equilibrar los recursos de E/S. Si tiene más de un almacén de datos compartido montado en el servidor ESXi, puede configurar el programador de recursos distribuidos de almacenamiento (DRS de almacenamiento). Storage DRS es una función inteligente de vCenter Server para administrar de manera eficiente el almacenamiento VMFS y NFS que proporciona la migración y la colocación automática de discos de máquinas virtuales. También puede configurar Storage DRS en modo manual si prefiere aprobar las recomendaciones de migración manualmente
Siga estos pasos para habilitar el almacenamiento DRS:
- Navegue hasta el clúster del almacén de datos en vSphere Web Client.
- Vaya a vCenter >> Datastore Clusters.
- Seleccione su grupo de datos y haga clic en Manage >> Settings >> Services >> Storage DRS.
- Haga clic Edit.
- Configure las opciones de automatización, las funciones relacionadas con E / S y las opciones avanzadas que necesita.
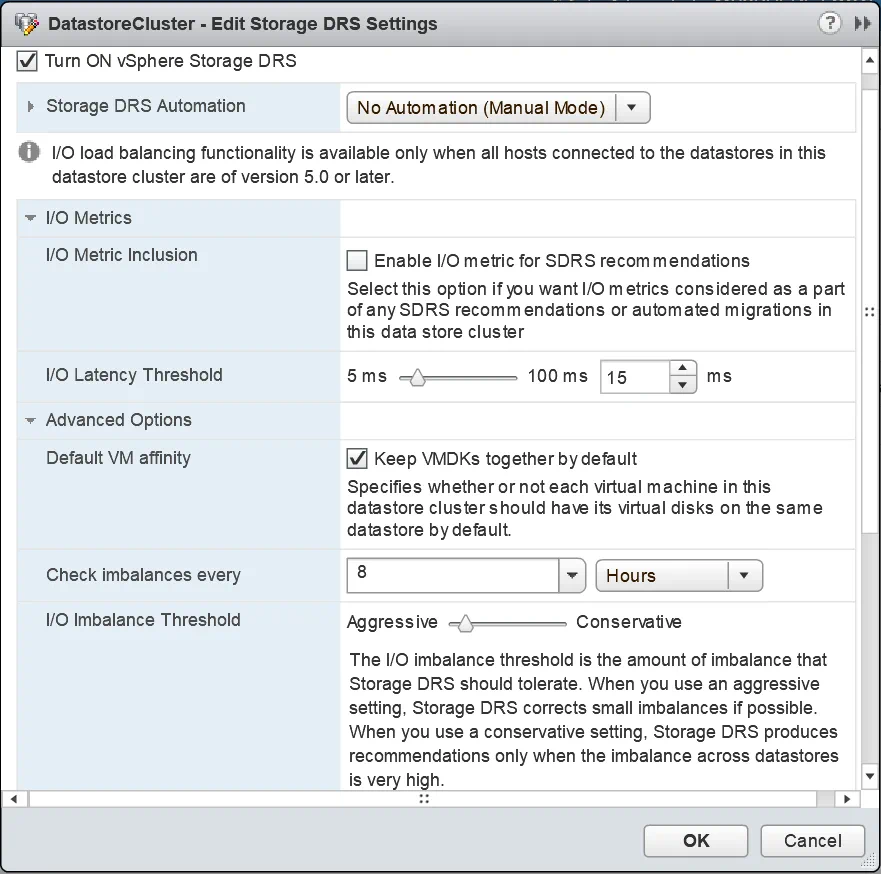
- Haga clic en OK para finalizar.
Si no hay clústeres de almacenes de datos en su entorno vSphere, siga estos pasos para crear y configurar un nuevo clúster de almacenes de datos.:
- Navegue hacia vCenter >> Datacenters en el cliente Web de vSphere.
- Haga clic derecho en su centro de datos y seleccione New Datastore Cluster.
- Ingrese el nombre de su grupo de datos y marque la casilla de verificación cerca de “Turn On Storage DRS“.
- Seleccione la configuración de automatización, las funciones relacionadas con E / S y las opciones avanzadas que necesita.
- Haga clic en OK para finalizar.
Conclusión
En esta publicación de blog, hemos considerado los tipos de discos virtuales y hemos analizado las ventajas y desventajas de cada uno para comprender mejor las diferencias entre el aprovisionamiento thick y thin. Los discos de aprovisionamiento eager thick y puestos a cero son los mejores para el rendimiento y la seguridad, pero requieren suficiente espacio de almacenamiento libre y toman mucho tiempo para crearse. Los discos de aprovisionamiento thick de puesta a cero lento son buenos para sus cortos tiempos de creación, pero no proporcionan tanta velocidad como los discos eager de puesta a cero, y son menos seguros. Los discos de aprovisionamiento thin son la mejor opción para ahorrar espacio en el almacén de datos en el momento de la creación del disco.
Puede crear un disco virtual con un tamaño máximo mayor que el espacio físico que tiene disponible («aprovisionamiento excesivo») y agregar más almacenamiento físico en el futuro, pero recuerde que, si el espacio del disco físico se llena y el disco de aprovisionamiento thin no puede crecer para acomodar más datos, sus máquinas virtuales se volverán inutilizables, así que no olvide vigilar la cantidad de espacio libre. También examinamos los métodos para reducir los discos virtuales VMware de aprovisionamiento thin, en caso de que prefiera no agregar más almacenamiento y necesite reducir el espacio ocupado.



