
Mejores prácticas de recuperación ante desastres de Hyper-V
En los entornos virtuales, las expectativas de disponibilidad del servicio y continuidad del negocio son muy altas. Hoy en día se espera que las empresas lleven a cabo sus operaciones y presten servicios a sus clientes sin interrupción.
Para mantener la disponibilidad frente a las interrupciones causadas por distintos factores, debe crear y actualizar constantemente un plan de recuperación ante desastres. Un plan de este tipo permite mantener el nivel de disponibilidad requerido y los objetivos de prevención de pérdida de datos, así como garantizar una recuperación rápida con una pérdida de datos mínima. Este blog proporciona consejos útiles para la recuperación ante desastres de Hyper-V.

¿Qué es la recuperación ante desastres con máquinas virtuales?
La recuperación ante desastres es un conjunto de políticas, procedimientos y herramientas cuyo objetivo es minimizar el tiempo de inactividad y recuperar las funciones de la empresa lo antes posible tras un incidente grave. La recuperación ante desastres (DR) para entornos virtuales, incluida la recuperación ante desastres de Hyper-V, generalmente incluye:
- Copia de seguridad y replicación de máquinas virtuales basadas en imágenes a nivel de bloque
- Retención de backups y réplicas de máquinas virtuales en un sitio remoto de DR.
- Conmutación por recuperación a réplicas de máquinas virtuales en caso de desastre
- Uso de backups de máquinas virtuales para almacenamiento a largo plazo y recuperación fiable.
Recuperación ante desastres de máquinas virtuales en un entorno Hyper-V
Microsoft Hyper-V incluye un conjunto de funciones inherentes que permiten una recuperación ante desastres eficiente de las máquinas virtuales. El presupuesto, la infraestructura y la escala de las operaciones de su empresa determinan qué funciones deben incluirse en su plan de recuperación ante desastres. Sin embargo, la recuperación ante desastres de máquinas virtuales en un entorno Hyper-V suele basarse en lo siguiente:
- Sitio de RD. Ubicación a la que una organización puede trasladar sus procesos durante un incidente hasta que el sitio/sistemas de producción vuelvan a estar operativos.
- Plataforma virtual alternativa y servidores de bases de datos. En caso de desastre, los servidores y el software de la plataforma virtual deben estar listos en el sitio de DR para alojar máquinas virtuales. Así se minimiza el tiempo de inactividad y se garantiza la continuidad de la actividad.
- Software de backup y replicación virtual para DR. Hyper-V utiliza la tecnología Volume Shadow Copy Service (VSS), que permite crear backups o instantáneas, incluso cuando están en uso. Mientras que la replicación de Hyper-V permite el uso de las copias (réplicas) de las máquinas virtuales en ejecución como medio para restaurar la máquina virtual en caso de desastre. Las modernas soluciones de software combinan las funciones de backup y replicación para ayudarle en la recuperación ante desastres.
Este conjunto de medios puede ayudar a las organizaciones a crear y aplicar con éxito un plan de recuperación ante desastres de máquinas virtuales en un entorno Hyper-V.
Consejos para una recuperación ante desastres exitosa de Hyper-V VM
He aquí una lista de consejos para una recuperación ante desastres exitosa de Hyper-V VM:
- Ejecute y pruebe regularmente los backups de las máquinas virtuales. Establezca el calendario de backups en función de las necesidades y prioridades de su organización. Compruebe periódicamente la validez e integridad de los backups creados.
- Cree y pruebe réplicas con regularidad. En función de la importancia de una aplicación o máquina virtual concreta para la continuidad de la actividad, puede configurar la replicación para garantizar una recuperación instantánea. Pruebe sus réplicas con regularidad para verificar su integridad y utilidad.
- Realice pruebas de conmutación por recuperación. Las pruebas le permiten verificar la capacidad de transferir operaciones críticas a un sitio de DR en caso de un incidente de DR. Las pruebas de conmutación por recuperación ayudan a identificar los puntos débiles que pueden socavar el proceso de RD.
- Actualice regularmente su solución de protección de datos. Dado que Microsoft actualiza constantemente sus productos, es importante que actualice su solución de protección de datos para hacer uso de las nuevas API y extensiones de Hyper-V.
- Almacenar backups y réplicas en un sitio remoto. Mantener estos datos en un lugar distante permite eliminar el riesgo de un único punto de fallo.
- Aplique actualizaciones de Windows a cada VM para parchear vulnerabilidades de seguridad. Hyper-V cambia y se desarrolla rápidamente, y Microsoft intenta mantener actualizados sus Servicios de integración de Hyper-V.
- Compruebe si hay errores de hardware y software. Realizar pruebas de verificación de RAM y disco, junto con comprobar si hay advertencias en el disco, es esencial si quieres evitar fallos en el sistema y posibles pérdidas de datos.
- Mantenga un espacio de disco adecuado en sus máquinas físicas y máquinas virtuales. El espacio libre en disco permite hacer backups fiables y una replicación rápida, mientras que una gran cantidad de RAM es crucial a la hora de reiniciar una máquina virtual. Así, para garantizar el éxito de los backups y las replicas, es práctico instalar una solución de protección de datos que pueda gestionar el espacio de almacenamiento y enviar notificaciones sobre el nivel crítico de RAM.
- Instale e implemente una solución de protección de datos compatible con VSS. VSS supervisa el rendimiento y el estado de las máquinas virtuales durante los jobs de backup y replicación. También debe configurar VSS para optimizar eficazmente los backups y las réplicas.
Cómo proteger su infraestructura con la solución DR de NAKIVO
Dado que la recuperación ante desastres de Hyper-V VM se basa en copias de seguridad y réplicas de VM, ambas opciones deben tenerse en cuenta a la hora de elegir una solución de protección de datos para implementar un plan de DR. NAKIVO Backup & Replication es una solución que proporciona una completa protección de datos para máquinas virtuales Microsoft Hyper-V e incluye funciones de backup y replicación.
- Microsoft Hyper-V VM backup. Si utiliza una solución moderna basada en imágenes como NAKIVO Backup & Replication, se crea una copia puntual de la máquina virtual, que incluye el sistema operativo, las configuraciones, etc. En caso de un incidente de DR, se puede recuperar una VM del backup en el mismo estado en el que se encontraba durante el proceso de backup. Por ejemplo, puede arrancar instantáneamente una máquina virtual Hyper-V o recuperarla como una máquina virtual VMware vSphere.
Puede hacer backups de Hyper-V VMs con NAKIVO creando un nuevo job de backups desde la pantalla principal después de añadir el host Hyper-V al Inventario de la solución.
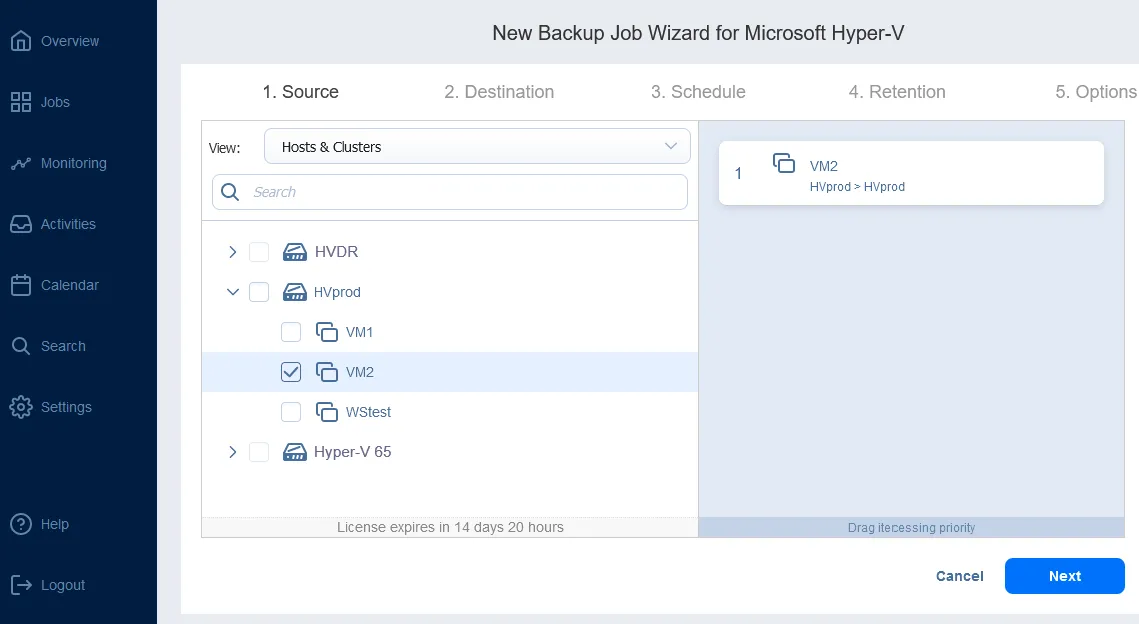
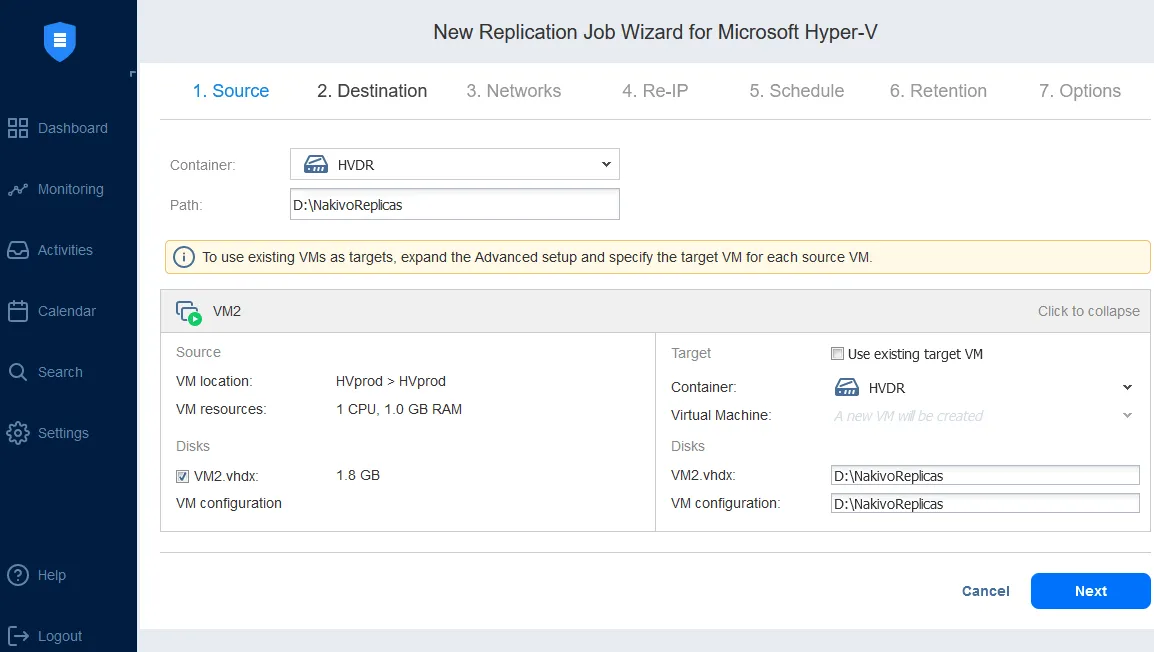
- Replicación de Hyper-V VM de Microsoft. Mediante el uso de la replicación de Hyper-V VM, puede crear una copia idéntica de una VM primaria, conocida como una réplica de VM, que simplemente se puede encender en caso de un evento de DR cuando se requiere una recuperación inmediata. La conmutación por error de las cargas de trabajo a la réplica (es decir, mover las máquinas virtuales y los sistemas al sitio de DR) para recuperar las operaciones en el sitio de DR es esencial para mantener la continuidad del negocio y la alta disponibilidad.La configuración de un job de replicación Hyper-V con NAKIVO permite configurar el mapeo de la red y las reglas de reIP.
- RTO y RPO. El objetivo de punto de recuperación (RPO) y el objetivo de tiempo de recuperación (RTO) son métricas clave que se deben establecer al planificar la recuperación ante desastres de Hyper-V VM. RPO y RTO deben definirse en su plan de DR para las diferentes cargas de trabajo críticas y dictarán la frecuencia de backup/replicación.
- RPO significa la cantidad de datos que una empresa puede permitirse perder sin perjudicarla (medida como intervalo de tiempo entre dos jobs de backup/replicación).
- RTO es el periodo de tiempo en el que las operaciones empresariales deben recuperarse tras un desastre antes de que el incidente tenga un impacto negativo en una organización. Las operaciones de replicación y conmutación por error de máquinas virtuales permiten RTO mucho más cortos que la recuperación a partir de backups de máquinas virtuales.
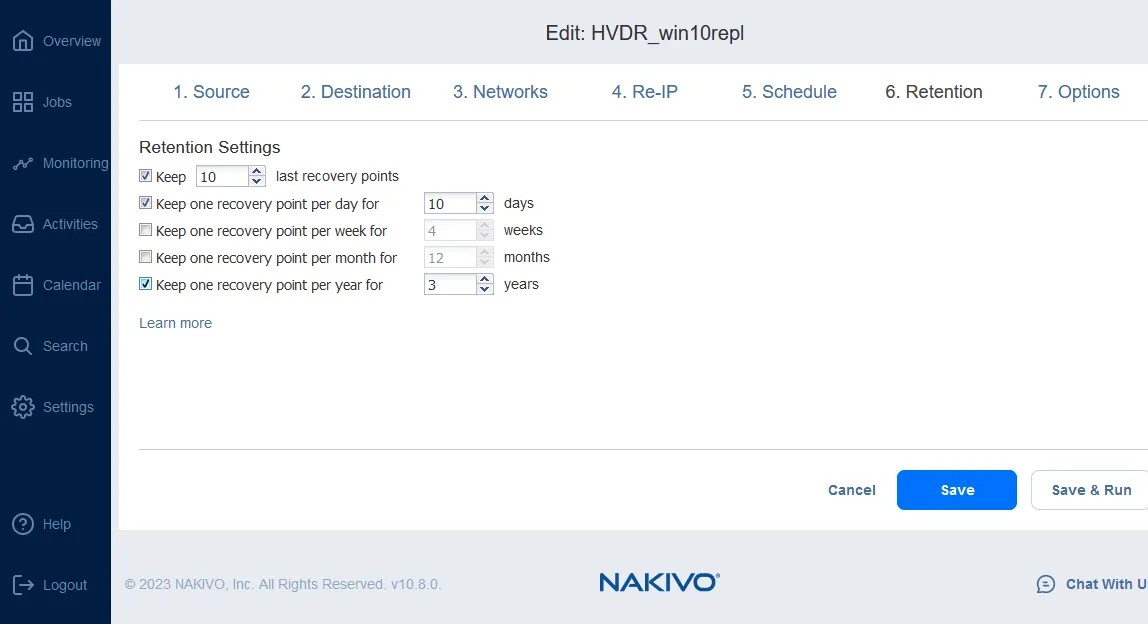
Puede configurar los ajustes de retención aplicando la política de retención abuelo-padre-hijo. Estos ajustes determinan el número de réplicas de VM que conserva y que puede utilizar para la recuperación ante desastres de Hyper-V.
Orquestación de la recuperación ante desastres de Hyper-V con NAKIVO
NAKIVO Backup & Replication cuenta con un conjunto de funciones, incluida la función avanzada Site Recovery compatible con entornos VMware, Hyper-V y AWS EC2. La función Site Recovery representa un conjunto de acciones y procedimientos que pueden organizarse de una forma determinada para crear un flujo de trabajo (job) de recuperación ante desastres de VM. Los flujos de trabajo de restauración del entorno en NAKIVO Backup & Replication permiten la orquestación y automatización de un proceso de DR en varios sitios.
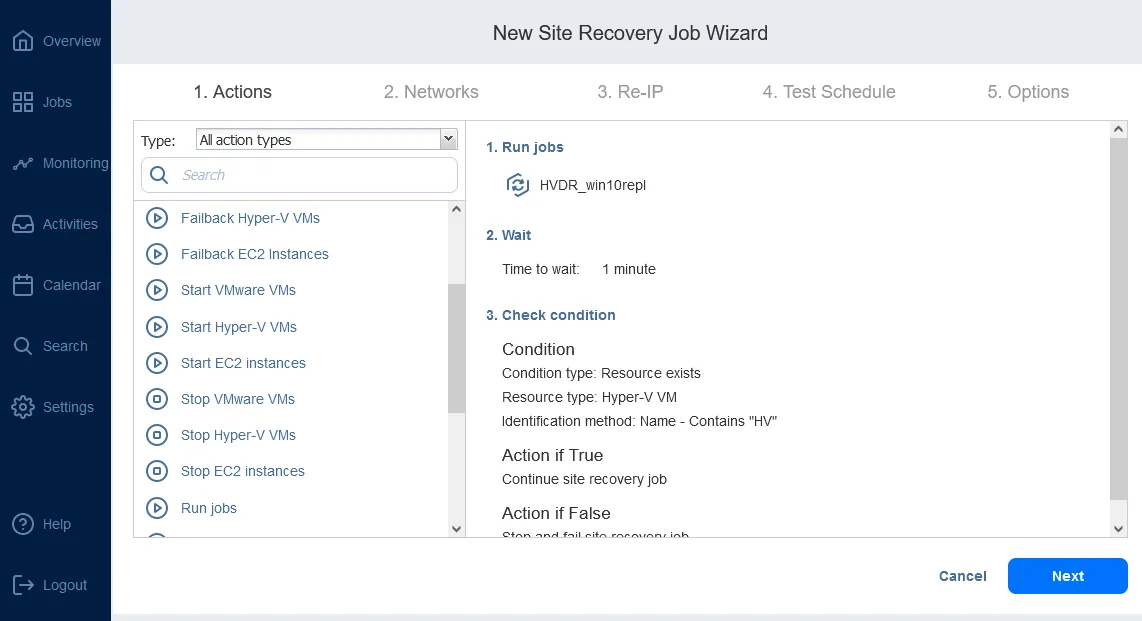
Los jobs de Site Recovery pueden incluir (entre otras acciones de DR) la conmutación por error automatizada, que permite la restauración de todo un sitio en unos pocos clics. Además, NAKIVO Backup & Replication ofrece dos tipos de conmutación por error: planificada y de emergencia.
- La conmutación por recuperación planificada se utiliza generalmente para proteger un sistema de un desastre inminente o durante las operaciones de mantenimiento en el sitio primario. En este caso, la solución realiza una última sincronización de datos y, a continuación, traslada la carga de trabajo del sitio primario a las réplicas de máquinas virtuales.
- La conmutación por recuperación de emergencia se activa cuando su sitio primario ya ha sido afectado por un incidente. La solución traslada la carga de trabajo del sitio primario a la réplica de la máquina virtual sin la sincronización de datos (para ahorrar tiempo) y reducir el tiempo de inactividad.
Además, NAKIVO Backup & Replication puede ejecutar un job de Site Recovery en modo de prueba (programado o ad hoc), lo que constituye una forma ideal de averiguar si sus flujos de trabajo de recuperación funcionan según lo previsto y si sus RTO pueden cumplirse.

La posibilidad de crear un flujo de trabajo de restauración del entorno con la ayuda de NAKIVO Backup & Replication ofrece una ventaja significativa a cualquier empresa. Puede crear una estrategia de DR que se adapte a las necesidades específicas de su empresa, configurarla de antemano y ejecutarla con sólo unos clics en caso de desastre. Además, puede probar y optimizar constantemente su estrategia de DR para lograr los mejores resultados posibles (tiempo de inactividad cero, RTO más cortos, alta disponibilidad y menores costes).



